CentOS7 基于Hadoop2.7.3完全分布式安装Hive2.3.4以及安装MySql
CentOS7基于Hadoop2.7.3安装Hive2.3.4
- 0x00 本人的Hadoop集群已配置并且能正常运行
- 0x10 安装Mysql5.7
- 0x11 为yum配置mysql57的源
- 0x12 修改MySQL密码
- 开启 mysql 中 root用户远程访问权限
- 0x20 下载、配置Hive
- 0x21到apache下载Hive的tar包
- 0x22安装Hive,并设置环境变量
- 0x23 配置hive-site.xml文件--Hadoop相关部分
- 0x24 hive-site.xml配置文件--jdbc和MySQL相关部分
- 0x25 hive-env.sh配置文件
- 0x26 拷贝jdbc驱动到hive的lib目录
- 0x30 启动hive
- 0x31 初始化mysql的hive数据库
- 0x32 启动
- 0x33 新建数据库,表
- 0x34 通过网页查看hadoop50070端口(3.x.y以上端口为9870)
- 0x40 参考文章
0x00 本人的Hadoop集群已配置并且能正常运行
本文假设你的Hadoop能正常使用,如果没有请问神奇的海螺。
0x10 安装Mysql5.7
0x11 为yum配置mysql57的源
# 下载MySQL的repository
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
# 安装MySQL源
yum -y install mysql57-community-release-el7-10.noarch.rpm
# 通过yum安装MySQL
yum -y install mysql-community-server
0x12 修改MySQL密码
初始密码不能做任何事情,所以MySQL需要修改密码之后才能操作数据库
1.先启动mysql
# 启动MySQL
systemctl start mysqld.service
# 查看其状态
systemctl status mysqld.service
看到 active(running) 即为正确运行,如下
 2.查看默认密码并连接mysql
2.查看默认密码并连接mysql
查看默认密码
grep "password" /var/log/mysqld.log
查看结果如下:
![]() 通过默认密码登录mysql:
通过默认密码登录mysql:
mysql -uroot -p
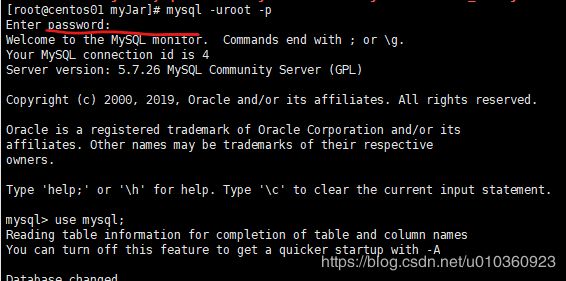
3.关闭弱密码限制和长度限制,
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1;
4.修改密码
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'my5qlpassw0rd';
/*
比较新的MySQL 要使用alter user 来修改密码
*/
开启 mysql 中 root用户远程访问权限
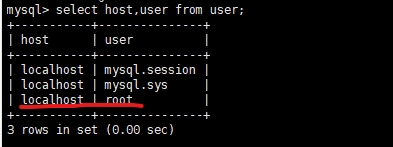
1.查看默认设置
mysql> use mysql;
mysql> select host,user from user;
可知,root用户只能本地访问:
2.开启root远程访问权限
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'my5qlpassw0rd' WITH GRANT OPTION;
/*
% 表示全部允许ip
root为用户
my5qlpassw0rd为密码
*/
mysql> flush privileges;
/*
刷新,或者重新启动mysql也行
*/
3.再次查看
mysql> select host,user from user;
可以看到已经开启:
注:因为下面内容中,在Hive配置文件里面链接mysql的用户配的是root,所以此处为MySQL的root开启远程

0x20 下载、配置Hive
0x21到apache下载Hive的tar包
1.查看Hive版本支持的Hadoop和其他变化:http://hive.apache.org/downloads.html
 2.到国内清华镜像网站选择版本:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
2.到国内清华镜像网站选择版本:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
此处使用wget下载Hive2.3.4:
wget -c https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.4/apache-hive-2.3.4-bin.tar.gz
0x22安装Hive,并设置环境变量
# 解压Hive 到安装目录/opt/module/
tar -zxvf apache-hive*.tar.gz -C /opt/module/
# 编辑profile文件 配置Hive环境变量
vim /etc/profile
# 配置的内容
# Hive
export HIVE_HOME=/opt/module/apache-hive-2.3.4-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$HIVE_HOME/bin:$PATH
# 记得source一下,使其生效
source /etc/profile
0x23 配置hive-site.xml文件–Hadoop相关部分
1.从模板拷贝配置文件
# 进入Hive的conf目录(也就是存放配置文件的目录)
cd /opt/module/apache-hive-2.3.4-bin/conf
# 查看
ls
# beeline-log4j2.properties.template ivysettings.xml
# hive-default.xml.template llap-cli-log4j2.properties.template
# hive-env.sh.template llap-daemon-log4j2.properties.template
# hive-exec-log4j2.properties.template parquet-logging.properties
# hive-log4j2.properties.template
# 复制 hive-default.xml.template模板,并重命名 hive-site.xml
cp hive-default.xml.template hive-site.xml
# 同样基于模板创建hive-env.sh
cp hive-env.sh.template hive-env.sh
2.设置存储路径和tmp路径
hive-site.xml中的两条配置内容,说明了存储路径和tmp路径
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
根据 hive-site.xml 中的上述的两条配置内容,我们需要在hadoop中建立两个目录:
# 在hdfs中建立/user/hive/warehouse并设置权限
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod -R 777 /user/hive/warehouse
# 在hdfs中建立/tmp/hive/并设置权限
hadoop fs -mkdir -p /tmp/hive/
hadoop fs -chmod -R 777 /tmp/hive
同过浏览器查看ip:50070端口(Hadoop3.x.y端口为9870),查看HDFS是否存在新建的目录
0x24 hive-site.xml配置文件–jdbc和MySQL相关部分
1.设置system:java.io.tmpdir
a.JAVA.IO的临时目录,我将其设定为hive路径下的tmp目录中,因为tmp不存在所以需要新建tmp
# 进入到hive的安装目录
cd /opt/module/apache-hive-2.3.4-bin/
mkdir tmp
chmod -R 777 tmp/
b.将hive-site.xml文件中的${system:java.io.tmpdir}替换为hive的临时目录,注意是所有${system:java.io.tmpdir}都要替换
此处使用vim替换方法,也可以用其他比较方便编辑器
注:此处使用的是vim的 :命令模式键入如下文本替换命令(当然vi也可以)
# ESC进入vim的命令模式后,shift+: 键入如下文本替换命令,反斜杠是为了斜杆正常化
1,$s/${system:java.io.tmpdir}/\/root\/opt\/module\/apache-hive-2.3.4-bin\/tmp/g
c.将配置文件中所有${system:user.name}都替换为root
此处使用vim替换方法,也可以用其他比较方便编辑器
# ESC进入vim的命令模式后,shift+: 键入如下文本替换命令
1,$s/${system:user.name}/root
2.设置javax.jdo.option.ConnectionDriverName
将该 javax.jdo.option.ConnectionDriverName 对应的value修改为MySQL驱动类路径
注:此处使用的jdbc版本是mysql-connector-java-5.1.39-bin.jar,如果你的版本是8或者更高,请加入预处理。
即,将com.mysql.jdbc.Driver改为com.mysql.cj.jdbc.Driver
修改后如下:
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
3.设置javax.jdo.option.ConnectionURL
将该javax.jdo.option.ConnectionURL对应的value修改为MySQL的地址(将内容中的IP地址换成你的mysql主机IP地址)
修改后如下:
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://10.1.1.91:3306/hive?createDatabaseIfNotExist=truevalue>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
description>
property>
4.配置javax.jdo.option.ConnectionUserName
将javax.jdo.option.ConnectionUserName对应的value修改为MySQL数据库登录名(此处使用默认root用户)
修改后如下:
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>Username to use against metastore databasedescription>
property>
5.配置javax.jdo.option.ConnectionPassword
将javax.jdo.option.ConnectionPassword对应的value修改为MySQL数据库的登录密码
修改后如下:
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>my5qlpassw0rdvalue>
<description>password to use against metastore databasedescription>
property>
0x25 hive-env.sh配置文件
在hive的conf目录下,打开配置文件:
vim hive-env.sh
配置HIVE_AUX_JARS_PATH, HIVE_CONF_DIR, HADOOP_HOME
在已有的基础上修改如下:
#Folder containing extra libraries required for hive compilation/execution can be controlled by:
#export HIVE_AUX_JARS_PATH=
export HIVE_AUX_JARS_PATH=/opt/module/apache-hive-2.3.4-bin/lib
#Hive Configuration Directory can be controlled by:
#export HIVE_CONF_DIR=
export HIVE_CONF_DIR=/opt/module/apache-hive-2.3.4-bin/conf
#Set HADOOP_HOME to point to a specific hadoop install directory
#HADOOP_HOME=${bin}/../../hadoop
export HADOOP_HOME=/opt/module/hadoop-2.7.3
0x26 拷贝jdbc驱动到hive的lib目录
关于JDBC以及下载地址,请问海螺
mv mysql-connector-java-5.1.39-bin.jar /opt/module/apache-hive-2.3.4-bin/lib/
0x30 启动hive
0x31 初始化mysql的hive数据库
#进入到hive的bin目录
cd /opt/module/apache-hive-2.3.4-bin/bin
#对数据库进行初始化
schematool -initSchema -dbType mysql
注:如出现此类错误:
Underlying cause: java.sql.SQLException : Access denied for user 'root'@'name' (using password: YES)
mysql 可能存在多个同名不同域的情况
解决方法请参考:https://blog.csdn.net/xiaoqiu_cr/article/details/80910318
0x32 启动
# 执行hive启动
hive
0x33 新建数据库,表
进入hive后可以直接使用sql语句来进行操作,这就是hive意义
更多关于sql语法,请问海螺
hive>create database xxxxxxxdb;
hive>use xxxxxxxdb;
hive> create table testtable(id int);
/*
查看
*/
hive> select * from testtable;
0x34 通过网页查看hadoop50070端口(3.x.y以上端口为9870)
 也可以通过Navicat连接到MySQL,然后通过sql查询语句来查看
也可以通过Navicat连接到MySQL,然后通过sql查询语句来查看

0x40 参考文章
CentOS 7 搭建 Hadoop2.7.3 完全分布式集群:https://blog.csdn.net/u010360923/article/details/90513693
Hive实现WordCount:https://blog.csdn.net/u010360923/article/details/90341102