proGuard5.1混淆hadoop jar包使用指南
一.前期准备
1. 下载proGuard 5.1或proGuard 5.3,本文环境(proGuard 5.1)
2. 双击bin目录下的proguardgui.bat运行

3. 准备好待混淆的jar包和工程依赖的所有jar包

二.使用图形化界面进行配置(方法一)
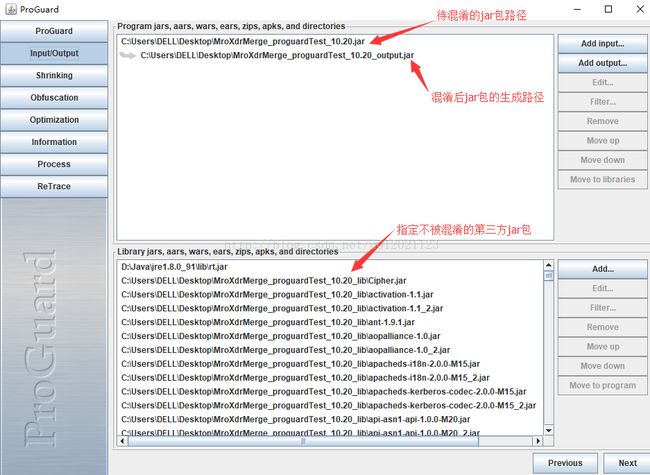
1.点击Add input加入待混淆jar包路径,Add output加入混淆后jar包生成路径,点击Add加入不被混淆的第三方jar包。
2.压缩选项(Shrinking)。

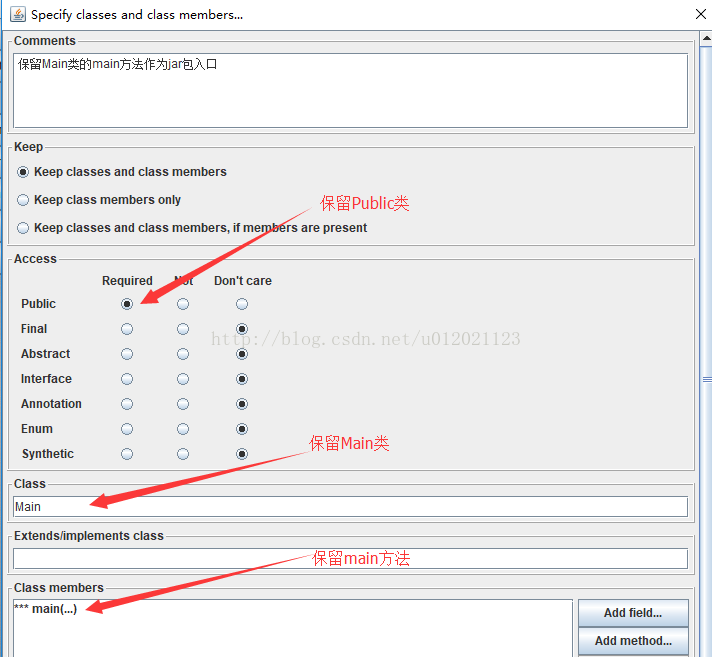
2.1点击Add加入需要保留的类及方法,拉下拉框点击ok保存设置。
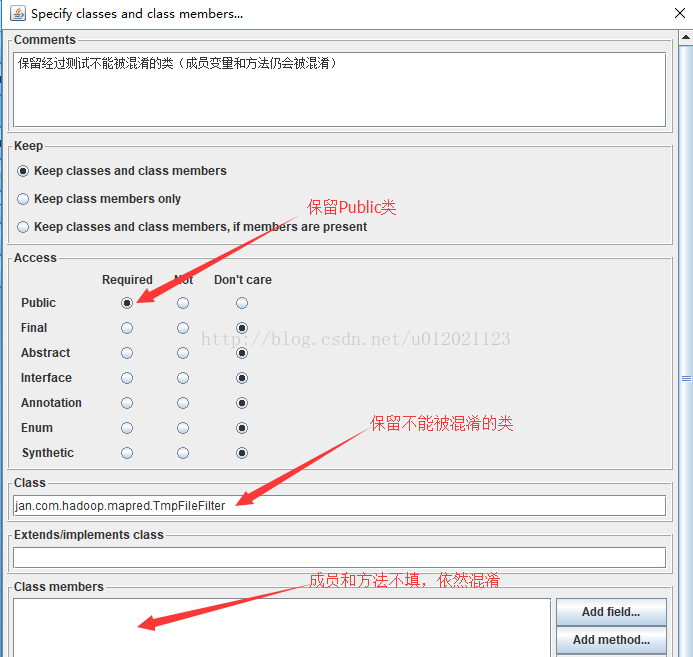
2.2点击Add加入需要保留的类,方法还是被混淆。
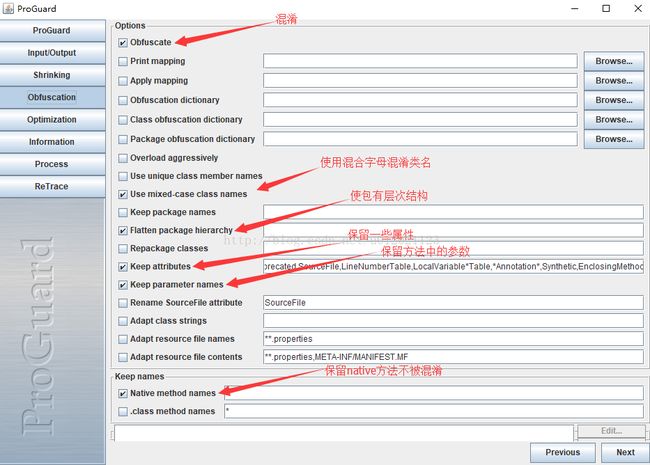
3. 混淆选项(Obfuscation)
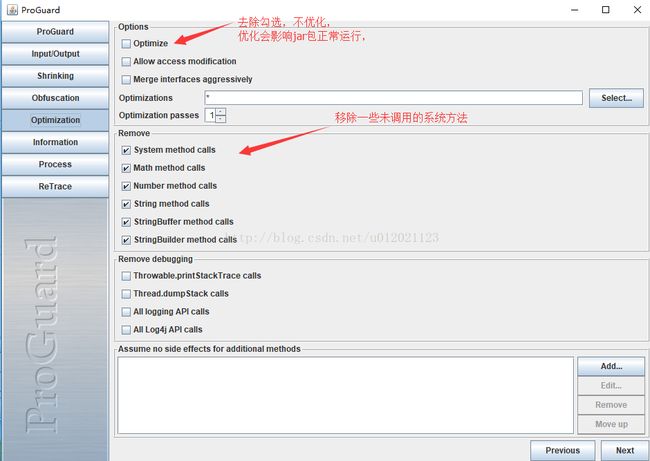
4. 优化(Optimization)
5. 预校验(Preverify)

6. 点击process开始处理。(可以点击Save configuration来保存你上面的配置信息为.pro文件以便下次混淆)
三.直接导入.pro配置文件(方法二)
1.配置信息,当然,针对不同的jar包,配置信息需要做相应的调整。
# 待混淆jar包路径
-injars MroXdrMerge_proguardTest_10.20.jar
# 混淆后jar包生成路径
-outjars MroXdrMerge_proguardTest_10.20_output.jar
# 不混淆工程依赖的所有jar包(项目中一般不混淆引入的第三方类库)
-libraryjars 'D:\Java\jre1.8.0_91\lib\rt.jar'
-libraryjars MroXdrMerge_proguardTest_10.20_lib\Cipher.jar
...
# 虽然压缩可以使我们的jar包占用内存更小,但是由于压缩会移除一些无用的类、字段、方法等影响到jar包的运行,所以我们选择不压缩
-dontshrink
# 不优化,经测试优化会导致jar包运行时报找不到类错误(优化过程也会删除一些没有被调用的类)。
-dontoptimize
# 移动重命名的包到父包中,使包呈现扁平化的层次结构
-flattenpackagehierarchy ''
# 保留一些属性,如异常,内部类,签名,注解等
-keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LineNumberTable,LocalVariable*Table,*Annotation*,Synthetic,EnclosingMethod
# 保留方法的参数
-keepparameternames
# 忽略所有警告
-ignorewarnings
# 保留Main类的main方法作为jar包入口
-keep public class Main {
*** main(...);
}
# 保留经过测试不能被混淆的类(成员变量和方法仍会被混淆)
-keep public class jan.com.hadoop.mapred.TmpFileFilter
# 保留枚举类不被混淆
-keepclassmembers enum * {
public static **[] values();
public static ** valueOf(java.lang.String);
}
# 保留Serializable序列化的类不被混淆
-keepclassmembers class * extends java.io.Serializable {
static final long serialVersionUID;
static final java.io.ObjectStreamField[] serialPersistentFields;
private void writeObject(java.io.ObjectOutputStream);
private void readObject(java.io.ObjectInputStream);
java.lang.Object writeReplace();
java.lang.Object readResolve();
}
# 经测试native类混淆也不会对jar包运行有影响,不过网上说最好不被混淆,那我们就保留它吧,不差这一个。
-keepclasseswithmembers,includedescriptorclasses,allowshrinking class * {
native
}
# 下面则是一些优化,删除一些返回值没用到的系统调用方法
-assumenosideeffects public class java.lang.System {
public static long currentTimeMillis();
static java.lang.Class getCallerClass();
public static int identityHashCode(java.lang.Object);
public static java.lang.SecurityManager getSecurityManager();
public static java.util.Properties getProperties();
public static java.lang.String getProperty(java.lang.String);
public static java.lang.String getenv(java.lang.String);
public static java.lang.String mapLibraryName(java.lang.String);
public static java.lang.String getProperty(java.lang.String,java.lang.String);
}
...