Benchmark: A survey
前言
在进行大规模集群问题的研究时,我们往往没有足够多的服务器来搭建一个真正的大规模云计算集群,通常有以下几种方案解决此问题:
-
租用云计算集群服务,如Amazon,华为云和阿里云等云服务。但该方式需要投入大量资金,有些同学在刚接触云计算时往往申请不到该资金,当然有收入的同学也可以选择自己购买。
-
采用开源的云计算集群模拟平台,如Cloudsim。这种方式好像做通信方向的使用的较多,有兴趣的可以移步官网查看。
-
采用Docker容器部署集群。容器具有轻量级、易部署的特点,已被广泛应用于大规模云数据中心,同时也受到学术界的欢迎,因此,前期的研究可以使用该方式进行集群搭建和部署。
搭建了云计算平台之后,接下来要做的工作是部署云集群上运行的上层服务。由于单个服务器运行一种负载的部署方式资源利用率较低,谷歌和阿里等大型云服务提供商采用在离线负载混部的方式为终端用户提供服务,该部署策略在一定程度上提升了云计算集群的资源利用率,减少了云服务提供商的运营成本。
然而,由于企业对提供应用的保密性和实验室集群规模的限制,我们无法使用真实的应用负载去测试与评估。用于测试和研究的benchmark应运而生。
Benchmark定义
In computing, a benchmark is the act of running a computer program, a set of programs, or other operations, in order to assess the relative performance of an object, normally by running a number of standard tests and trials against it. The term benchmark is also commonly utilized for the purposes of elaborately designed benchmarking programs themselves. wiki
Benchmark是计算机界用以测试和衡量计算机程序的性能的一套组件标准,我们可以将其部署在云计算集群中模拟真实的应用负载,从而研究在不同配置的集群、不同的混部模式等条件下,负载执行时的应用级特征和系统层特征,进而指导云集群的资源规划和调度管理。目前国内在该方面做的比较好的是中科院计算所詹剑锋课题组,他们已经开源了多个针对不同场景的benchmark。当然,还有其他研究团队对benchmark开源也做出了非常大的贡献。下面我将对目前国内外已有的benchmark进行梳理。
Benchmark的分类
1. 面向web应用的benchmark
TPC-W:TPC-W是一个网上交易测试平台,模拟了图书网站的交易流程。TPC-W测试系统的结构如图1所示:

TPC-W采用的是Client/Server结构,由三部分组成:
- a.被测部分(SUT) 由测试所需的模拟电子商务网站、配套的专用数据库和应用程序构成,它将在集群超级网络服务器上运行一个按照TPC-W规范的要求构建的模拟售书电子商务网站,是整个测试系统中的服务器端;
- b.付钱网关系统(PGE),这一部分辅助主体测试部分完成网上付款时银行的认证和划拨;
- c.远程模拟浏览器(RBE),它从客户端往服务器发请求,收集测试指标,从而得出系统的性能参数。整个测试系统中最重要的三个部分分别为按照TPC-W规范设计的模拟售书的电子商务网站、与网站配套的专用数据库以及客户端的应用测试程序。
由此衍生出了一系列benchmark:
TPC-C is an On-Line Transaction Processing Benchmark
TPC-DI is a benchmark for Data Integration
TPC-DS is a Decision Support Benchmark
TPC-E is an On-Line Transaction Processing Benchmark
TPC-H is a Decision Support Benchmark
TPC-VMS is a Data Virtualization Benchmark 等等。
2. 面向数据库服务的benchmark
YCSB:
YCSB是Yahoo公司的一个用来对数据库服务进行基础测试的工具,已在github开源。主要用来测试四个被广泛使用的数据库系统:Cassandra、HBase、PNUTS和一个简单的片式MySQL。
YCSB特点:可扩展的,除了很容易对新系统进行基准测试,支持新定义的简单工作负载。
3. 面向大数据平台的benchmark
Hibench:
HiBench是一个大数据基准组件,可以评测不同大数据平台的性能、吞吐量和系统资源利用率。它包含一组Hadoop、Spark和Streaming测试模式,包含Sort、WordCount、TeraSort、Sleep、SQL、PageRank、Nutch index、Bayes、Kmeans、NWeight和增强型的DFSIO等负载。
CloudSuite:
CloudSuite是用于测试scale-out应用程序性能的标准测试程序集。这个标准测试程序集基于真实环境的软件栈,代表了真实环境的系统配置。主要包含8种类型的负载,分别是:Data Analytics,Data Caching, Data Serving, Graph Analytics, In-memory Analytics, Media Streaming, Web Search, Web Serving。该benchmark已经开源了其docker部署方式,可直接参考github。
BigBench:
TPCx-BB Express Benchmark BB(TPCx-BB)衡量基于Hadoop的大数据系统系统的性能。它通过在具有实体店和在线商店的零售商的环境中执行30次频繁执行的分析查询,来测量硬件和软件组件的性能。查询以SQL表示结构化数据,以机器学习算法表示半结构化和非结构化数据。SQL查询可以使用Hive或Spark,而机器学习算法则使用机器学习库,用户定义的函数和过程程序。
BigBench实际上就是TPCx-BB的前身,它于2016年2月被TPC委员会接受以后被命名为TPCx-BB,在此之前叫BigBench。TPCx-BB是业界领先的基于端到端的大数据分析领域应用级测试基准,由Intel领衔发起,并作为主要开发和大力推广。
LinkBench:
LinkBench是一个社交图谱数据库基准测试程序,旨在评估类似于Facebook生产的MySQL部署的负载的数据库性能。 LinkBench具有高度的可配置性和可扩展性。可以将其重新配置为模拟各种工作负载,并且可以编写插件来对其他数据库系统进行基准测试。
BigdataBench:
它覆盖5个典型的应用领域(搜索引擎、电子商务、社交网络、多媒体、生物信息学),包含结构化、半结构化、非结构化的数据类型,涵盖离线分析、交互式分析、在线服务、NoSQL这4种负载类型.目前包含14个真实数据集、3种类型的数据生成工具以及33个负载的不同软件栈实现。

4. 面向AI应用程序的benchmark
近年来人工智能被广泛应用于工业界的各个领域,学术界对于人工智能领域的研究也越来越火热。因此各种各样的面向AI应用程序的benchmark也开始涌现。
AIBench:由中科院计算所高婉玲等共同研发,通过对三个重要的互联网领域:搜索引擎,社交网络和电子商务中挑选出典型的AI应用场景,抽象出6个典型的AI问题域:classification, image generation, text-to-text translation, imageto-text, image-to-image, speech-to-text, face embedding, 3D face recognition, object detection, video prediction, image compression, recommendation, 3D object reconstruction, text summarization, spatial transformer, and learning to rank。该Benchmark主要包含三种类型:Application benchmarks:E-commerce Search是一种基于web的电子商务负载;DCMix是模拟当前云计算集群中的混部方式而构建的混部负载,并提供了Docker部署方式(我在自己的服务器上尝试部署,但未成功,会出现各种小问题)。Component Benchmarks:主要包含图像分类,图像生成,文本转换等AI类型的负载。Micro Benchmark:主要是机器学习中用到的一些数学方法如卷积,全连接,激活函数Relu、Tanh等。
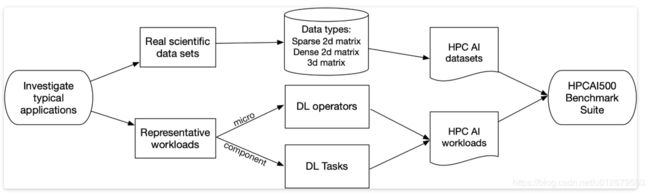
HPC AI500:我们关注这些应用领域中的典型DL(deep learning)工作负载和数据集。为了涵盖工作负载的多样性,提取了代表现代HPC AI的4个重要组件基准:图像识别,对象检测,图像生成和序列预测。在每个组件中,都选择了最先进的软件堆栈和模型。还选择了热点DL运算符作为评估系统上限性能的微型基准。从上述科学领域中选择了5个代表性的科学数据集,并从数据格式的角度考虑了它们的多样性。因此,我们将这些矩阵分为三种格式:2D稀疏矩阵,2D密集矩阵和3维矩阵。在每种矩阵格式中,我们还考虑科学数据中的独特特征(例如,超过RGB的多通道,高分辨率)。HPC AI5000的方法如图2所示:
Edge AIBench:
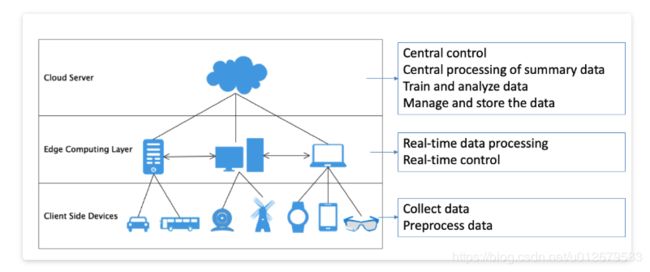
Edge AIBench是用于端到端边缘计算的基准组件,包括四个典型的应用场景:ICU患者监护仪,监控摄像头,智能家居和自动驾驶汽车,它们考虑了所有边缘计算AI场景的复杂性。此外,Edge AIBench还提供了一个端到端的应用程序基准测试框架,包括训练,验证和推断阶段。Edge AIBench使用通用的三层边缘计算框架提供了端到端应用程序基准测试,包括训练,推理,数据收集和其他部分。
AIoT Bench:
AIoT Bench是一个全面的基准套件,用于评估移动和嵌入式设备的AI能力。该基准测试:
- 涵盖了不同的应用领域,例如图像识别,语音识别和自然语言处理;
- 涵盖不同的平台,包括Android设备和Raspberry Pi;
- 涵盖了不同的开发工具,包括TensorFlow和Caffe2;
- 提供端到端应用程序工作负载和微型工作负载。
AIoT Bench中的工作负载是使用Android和Raspberry Pi平台上的TensorFlow Lite和Caffe 2来实现的。由于训练通常是在数据中心上进行的,因此该benchmark仅包含预测过程。AIoT Bench主要包含以下几类负载:
- 图像分类工作负载:视觉域的端到端应用程序工作负载。该负载将图像作为输入并输出图像标签。该负载用于图像分类的模型是MobileNet,这是专为移动和嵌入式设备设计的轻型卷积网络。
- 语音识别工作负载:语音域的端到端应用程序工作负载。该负载以口语中的单词和短语作为输入并将它们转换为文本格式。该负载使用的模型是DeepSpeech 2,它由2个卷积层,5个双向RNN层和一个完全连接的层组成。
- 转换翻译工作负载:NLP域的端到端应用程序工作负载。该负载将一种语言的文本作为输入并转换为另一种语言。该负载使用的模型是Transformer Translation Model,该模型使用注意机制解决了序列到序列问题,而无需使用传统神经seq2seq模型中使用的递归连接。
- 微型工作负载。该基准测试同时提供了微型工作负载,包括卷积运算,逐点卷积,深度卷积,矩阵乘法,逐点加法,ReLU激活,S型激活,最大池化,平均池化。
参考文献
[1] 谢夏, 李胜利, 金海. 基于集群服务器性能的TPC-W基准测试[J]. 华中科技大学学报(自然科学版), 2003, 31(2):26-27.
[2] 詹剑锋, 高婉铃, 王磊, et al. BigDataBench:开源的大数据系统评测基准[J]. 计算机学报, 2016, v.39;No.397(01):198-213.
[3] Ferdman M, Adileh A, Kocberber O, et al. Clearing the clouds: a study of emerging scale-out workloads on modern hardware[C]//ACM SIGPLAN Notices. ACM, 2012, 47(4): 37-48.
[4] Palit T, Shen Y, Ferdman M. Demystifying cloud benchmarking[C]//2016 IEEE international symposium on performance analysis of systems and software (ISPASS). IEEE, 2016: 122-132.
[5] Cooper B F, Silberstein A, Tam E, et al. Benchmarking cloud serving systems with YCSB[C]//Proceedings of the 1st ACM symposium on Cloud computing. ACM, 2010: 143-154.
[6] Ghazal A, Rabl T, Hu M, et al. BigBench: towards an industry standard benchmark for big data analytics[C]//Proceedings of the 2013 ACM SIGMOD international conference on Management of data. ACM, 2013: 1197-1208.
[7] Armstrong T G, Ponnekanti V, Borthakur D, et al. LinkBench: a database benchmark based on the Facebook social graph[C]//Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. ACM, 2013: 1185-1196.
[8] Gao W, Tang F, Wang L, et al. AIBench: an industry standard internet service AI benchmark suite[J]. arXiv preprint arXiv:1908.08998, 2019.
[9] Hao T, Huang Y, Wen X, et al. Edge AIBench: towards comprehensive end-to-end edge computing benchmarking[C]//International Symposium on Benchmarking, Measuring and Optimization. Springer, Cham, 2018: 23-30.