hadoop2.9.0环境下,mysql和伪分布式hive安装
在上一篇文章中,较为详细的讲述了hadoop2.9.0的安装步骤,本篇主要讲解如何在此环境上安装hive组件(Hive是一种以SQL风格进行任何大小数据分析的工具,其特点是采取类似关系数据库的SQL命令。其特点是通过 SQL处理Hadoop的大数据,数据规模可以伸缩扩展到100PB+,数据形式可以是结构或非结构数据)
搭建hive前提:已正常启动的hadoop2.9.0或者其他版本hadoop
(一)mysql安装以及授权远程访问等
(1)sudo apt-get install mysql-server mysql-client 使用此命令后,会在安装过程中让你输入root的密码,输入即可
(2)建立数据库;create database hive;(稍后hive所用的元数据库)
(3)创建用户hive; create user 'hive'@'%' identified by '123456';
(4)配置hive用户权限,进行授权;grant all on hive.* to 'hive'@'%' identified by '123456'; flush privileges ;
(5)配置远程访问(虽然mysql安装在master节点上,但是如果hive配置文件中是以网址+端口而不是localhost+端口形式访问,没有配置远程访问则会出错)
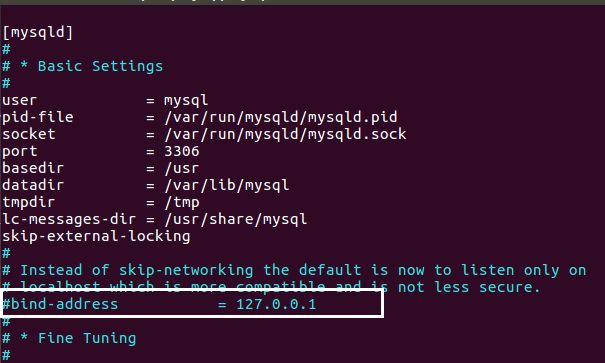
vim /etc/mysql/mysql.conf.d/mysqld.cnf 注释掉bind-address = 127.0.0.1:如下图所示:
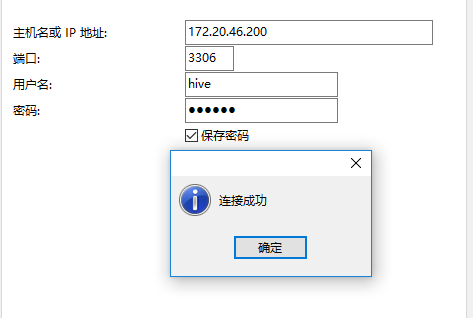
使用navicat进行远程访问配置测试
(二)hive伪分布式安装步骤(只需要装在master节点上即可)
在此步骤中,主要是一些文件的修改,包括hive-env.sh,hive-config.sh,hive-site.xml(如果前三者不存在,则需要从template中复制重命名即可),/etc/profile等
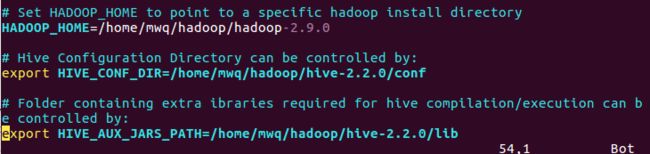
hive-env.sh修改HADOOP_HOME,HIVE_CONF_DIR,HIVE_AUX_JARS
hive-config.sh增加下图中三行

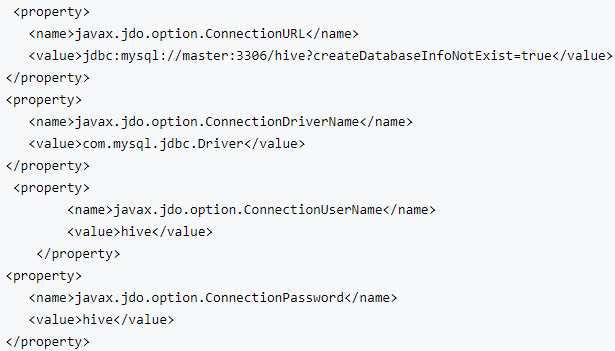
hive-site.xml修改对应的property,最后一项mysql密码应该是你自己设置的hive用户的密码
除了上述mysql的配置之外,还需要建立相应的目录,修改hive-site.xml中对应的文件存储目录
在hdfs中新建一下目录,并修改相应的权限
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -mkdir -p /user/hive/tmp
hadoop fs -mkdir -p /user/hive/log
hadoop fs -mkdir -p /user/hive/repl
hadoop fs -mkdir -p /user/hive/cmroot
hadoop fs -chmod 777 /user/hive/warehouse
hadoop dfs -chmod 777 /user/hive/tmp
hadoop dfs -chmod 777 /user/hive/log
hadoop dfs -chmod 777 /user/hive/repl
hadoop dfs -chmod 777 /user/hive/cmroot



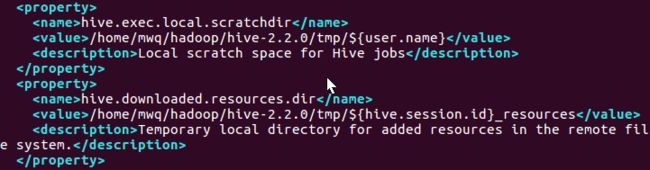
对于hive.exec.local.scratchdir和hive.download.resources.dir属性,需要将${system:java.io.tmpdir}用一个目录
代替,我在这里用的是/home/mwq/hadoop/hive-2.2.0-tmp,当然需要在所在位置新建。
修改/etc/profile文件,并使之生效 export HIVE_HOME=/home/mwq/hadoop/hive-2.2.0 在path中加入:HIVE_HOME/bin
初始化命令schematool -dbType mysql -initSchema,无错则可以
hive命令进入hive