Druid集群QuickStart
文章目录
- Install
- 配置文件目录规划
- 修改Druid使用
- Extension 插件安装
- Druid 监控
- 安装和启用对应的Graphite插件
- Help Command
- Druid Query查询测试
- 单独测试
- 压测
- Optimization and Tuning
- Segment Compact
- 开启Segment 自动合并
- 手动compact datasource
- Troubleshoot
- Historical 服务启动失败,报错"Cannot allocate memory"
Install
Download
wget http://apache.mirrors.hoobly.com/incubator/druid/0.16.0-incubating/apache-druid-0.16.0-incubating-bin.tar.gz
配置文件目录规划
.
├── broker
│ ├── jvm.config
│ ├── main.config
│ └── runtime.properties
├── _common
│ ├── common.runtime.properties
│ ├── core-site.xml
│ ├── graphite_whitelist.json
│ ├── hdfs-site.xml
│ └── log4j2.xml
├── coordinator
│ ├── jvm.config
│ ├── main.config
│ └── runtime.properties
├── historical
│ ├── jvm.config
│ ├── main.config
│ └── runtime.properties
├── middleManager
│ ├── jvm.config
│ ├── main.config
│ └── runtime.properties
└── router
├── jvm.config
├── main.config
└── runtime.properties
修改Druid使用
Druid 本身有很多插件支持,先把我们的metadata 元数据存储修改使用mysql存储
_common/common.runtime.properties
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://mysql_host:3306/druid
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=password
下载mysql driver jar到 $/extensions/mysql-metadata-storage/ 目录
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.38/mysql-connector-java-5.1.38.jar
创建Mysql数据库
CREATE DATABASE druid CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
grant all on druid.* to 'druid'@'127.0.0.1' identified by 'druid_password';
grant all on druid.* to 'druid'@'%' identified by 'druid_password';
Extension 插件安装
在 xtensions 目录下,默认已经安装来很多Druid插件,但是我们仍然可以根据我们的需要,安装自己想要的插件
java -classpath "./lib/*" org.apache.druid.cli.Main tools pull-deps -c org.apache.druid.extensions.contrib:graphite-emitter
pssh -h sbin/all_nodes -i “rm -rf /opt/druid-0.15.0/extensions/graphite-emitter”
pssh -h sbin/all_nodes -i “ls /opt/druid-0.15.0/extensions/graphite-emitter”
pssh -h sbin/all_nodes -i “cd /opt/druid-0.15.0 && java -classpath ‘./lib/*’ org.apache.druid.cli.Main tools pull-deps -c org.apache.druid.extensions.contrib:graphite-emitter”
Druid 监控
Druid 本身开发了很多监控插件接口,直接输出Druid内部的Metrics到各监控系统中,这里将监控数据输出到Graphite,并通过Grafana来做报表展示。
插件的安装方法参考前面的插件安装
安装和启用对应的Graphite插件
修改 /opt/druid-0.16.0/conf/druid/_common/common.runtime.properties
其中,graphite_whitelist.json 这个配置文件copy源码里的配置
“org.apache.druid.java.util.metrics.SysMonitor” 和 “org.apache.druid.java.util.metrics.JvmThreadsMonitor” 这两个监控插件监控的东西更加偏底层,暂时没有启用
druid.extensions.loadList=["druid-histogram", "druid-datasketches", "druid-lookups-cached-global", "mysql-metadata-storage", "druid-kafka-indexing-service", "druid-avro-extensions", "druid-hdfs-storage", "graphite-emitter"]
druid.monitoring.monitors=["org.apache.druid.java.util.metrics.JvmMonitor"]
druid.emitter=graphite
#use 2004 if using pickle , which is default else use 2003 for plaintext refer to 'druid.emitter.graphite.protocol'
druid.emitter.graphite.protocol=plaintext
druid.emitter.graphite.port=2003
druid.emitter.graphite.hostname=${graphite_host_name}
#### if you want to send all metrics then use this event convertor
#druid.emitter.graphite.eventConverter={"type":"all", "namespacePrefix": "druid", "ignoreHostname":false, "ignoreServiceName":false}
##else if you want to have a whitelist of metrics sent -- the full whitelist available in this repo for your convenience.
druid.emitter.graphite.eventConverter={"type":"whiteList", "namespacePrefix": "druid", "ignoreHostname":false, "ignoreServiceName":false, "mapPath":"/opt/druid-0.16.0/conf/druid/_common/graphite_whitelist.json"}
druid.emitter.logging.logLevel=info
对于 broker 和 historical 节点可以单独启用更加详细的Monitor来监控自己的指标
broker:
# Graphite emitter
druid.monitoring.monitors=["org.apache.druid.client.cache.CacheMonitor","org.apache.druid.server.metrics.QueryCountStatsMonitor", "org.apache.druid.java.util.metrics.JvmMonitor"]
druid.emitter=graphite
#use 2004 if using pickle , which is default else use 2003 for plaintext refer to 'druid.emitter.graphite.protocol'
druid.emitter.graphite.protocol=plaintext
druid.emitter.graphite.port=2003
druid.emitter.graphite.hostname=${graphite_host_name}
#### if you want to send all metrics then use this event convertor
#druid.emitter.graphite.eventConverter={"type":"all", "namespacePrefix": "druid", "ignoreHostname":false, "ignoreServiceName":false}
##else if you want to have a whitelist of metrics sent -- the full whitelist available in this repo for your convenience.
druid.emitter.graphite.eventConverter={"type":"whiteList", "namespacePrefix": "druid", "ignoreHostname":false, "ignoreServiceName":false, "mapPath":"/opt/druid-0.16.0/conf/druid/_common/graphite_whitelist.json"}
historical:
# Graphite emitter
druid.monitoring.monitors=["org.apache.druid.client.cache.CacheMonitor","org.apache.druid.server.metrics.HistoricalMetricsMonitor", "org.apache.druid.java.util.metrics.JvmMonitor"]
druid.emitter=graphite
#use 2004 if using pickle , which is default else use 2003 for plaintext refer to 'druid.emitter.graphite.protocol'
druid.emitter.graphite.protocol=plaintext
druid.emitter.graphite.port=2003
druid.emitter.graphite.hostname=${graphite_host_name}
#### if you want to send all metrics then use this event convertor
#druid.emitter.graphite.eventConverter={"type":"all", "namespacePrefix": "druid", "ignoreHostname":false, "ignoreServiceName":false}
##else if you want to have a whitelist of metrics sent -- the full whitelist available in this repo for your convenience.
druid.emitter.graphite.eventConverter={"type":"whiteList", "namespacePrefix": "druid", "ignoreHostname":false, "ignoreServiceName":false, "mapPath":"/opt/druid-0.16.0/conf/druid/_common/graphite_whitelist.json"}
Help Command
pssh -h ~/all_nodes "sudo su - root -c 'useradd druid'"
pssh -h ~/all_nodes "sudo su - root -c '(echo druid_password && echo druid_password) | passwd druid'"
同步druid 安装配置脚本
alias sync_druid='prsync -h /opt/druid-0.16.0/sbin/follow_nodes -a -r /opt/druid-0.16.0 /opt/'
集群管理脚本[more sbin/cluster.sh]
#!/bin/bash -eu
PWD="$(dirname "$0")"
DRUID_HOME=/opt/druid-0.16.0
usage="Usage: cluster.sh (start|stop|status)"
if [ $# -le 0 ]; then
echo $usage
exit 1
fi
command=$1
echo "========== broker nodes ===================="
pssh -h ${PWD}/broker_nodes -i "${DRUID_HOME}/bin/broker.sh ${command}"
echo "========== coordinator nodes ===================="
pssh -h ${PWD}/coordinator_nodes -i "${DRUID_HOME}/bin/coordinator.sh ${command}"
echo "========== historical nodes ===================="
pssh -h ${PWD}/historical_nodes -i "${DRUID_HOME}/bin/historical.sh ${command}"
echo "========== middleManager nodes ===================="
pssh -h ${PWD}/middleManager_nodes -i "${DRUID_HOME}/bin/middleManager.sh ${command}"
echo "========== router nodes ===================="
pssh -h ${PWD}/router_nodes -i "${DRUID_HOME}/bin/router.sh ${command}"
Druid Query查询测试
单独测试
curl -X POST -d @query.json -H 'Content-Type:application/json' http://prd-zbdruid-001:8082/druid/v2/sql/
query.json
{
"query": "SELECT TIMESTAMP_TO_MILLIS(__time) as time_ms, device_id, store_id, assistant_nick, yellow_light_count, dialogue_dispatch_count, marketing_heap_size, marketing_dispatch_count, conversation_job_avg_delay_time_ms, marketing_job_avg_delay_time_ms, sync_message_job_avg_delay_time_ms, contact_closing_job_avg
_delay_time_ms FROM druid_cia_metrics WHERE TIMESTAMP_TO_MILLIS(__time) = 1572327280000",
"header": "false"
}
压测
压测工具: locust
工具安装
pip install requests urllib3 pyOpenSSL --force --upgrade
pip install setuptools requests --upgrade
pip install --ignore-installed locust
压测脚本
import random
import json
from locust import HttpLocust, TaskSet, task
HOST = "http://druid-001:8082"
def rr(file_name):
with open(file_name, 'r') as f:
l = json.load(f)
return l
class Tasks(TaskSet):
@task(1)
def sql(self):
req = rr('query2.json')
# 24 hours random
i = random.randint(0, 360 * 24)
req['body']['query'] = req['body']['query'].format(ts=1572327290000 + i * 10 * 000)
#print(req['body'])
#print(req['header'])
r = self.client.post("/druid/v2/sql/", json.dumps(req['body']), headers=req['header'])
# print(r)
class User(HttpLocust):
task_set = Tasks
host = HOST
query2.json
{
"body": {
"query": "SELECT TIMESTAMP_TO_MILLIS(__time) as time_ms, device_id, store_id, assistant_nick, yellow_light_count, dialogue_dispatch_count, marketing_heap_size, marketing_dispatch_count, conversation_job_avg_delay_time_ms, marketing_job_avg_delay_time_ms, sync_message_job_avg_delay_time_ms, contact_closing_job_a
vg_delay_time_ms FROM druid_cia_metrics WHERE TIMESTAMP_TO_MILLIS(__time) = {ts}",
"header": "false"
},
"header": {
"Content-Type": "application/json"
}
}
启动测试程序: locust -f locustfile.py ,然后进入 http://host:8089 页面设置测试的并发个数,然后开启测试
Optimization and Tuning
Segment Compact
刚接手Druid,每台机器数据目录下面放了40万+个文件,而且每天数据量还在疯狂的的增长,平均segment size 才几十K,根据经验,小文件是一定要compact的,否则,后果灰常严重~~
![]()
查询Segment大小
SELECT
"start",
"end",
version,
COUNT(*) AS num_segments,
AVG("num_rows") AS avg_num_rows,
SUM("num_rows") AS total_num_rows,
AVG("size") AS avg_size,
SUM("size") AS total_size
FROM
sys.segments A
WHERE
datasource = 'druid_recommend_ctr' AND
is_published = 1
GROUP BY 1, 2, 3
ORDER BY 1, 2, 3 DESC;
开启Segment 自动合并
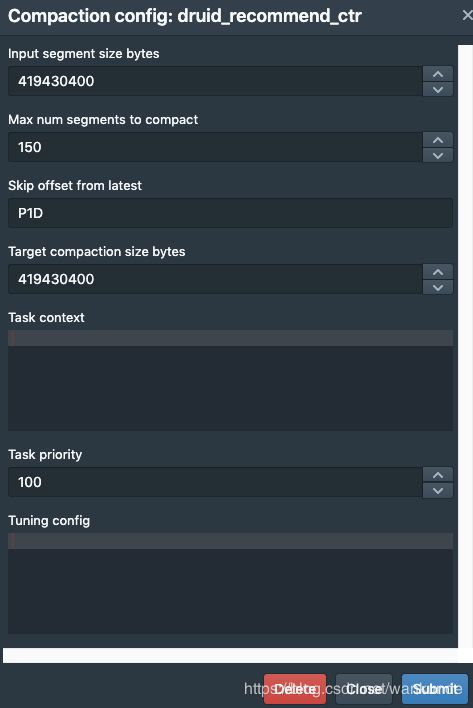
手动compact datasource
- 命令行开启 compact 配置
curl -X POST -d @compact.json --header “Content-Type: application/json” http://coordinator_node:8081/druid/coordinator/v1/config/compaction
{
"dataSource": "druid_recommend_ctr"
}
查看compact所有配置
curl -X GET http://coordinator_node:8081/druid/coordinator/v1/config/compaction| jq
{
"compactionConfigs": [
{
"dataSource": "druid_recommend_items_ctr",
"keepSegmentGranularity": true,
"taskPriority": 25,
"inputSegmentSizeBytes": 419430400,
"targetCompactionSizeBytes": 419430400,
"maxRowsPerSegment": null,
"maxNumSegmentsToCompact": 150,
"skipOffsetFromLatest": "P1D",
"tuningConfig": null,
"taskContext": null
}
],
"compactionTaskSlotRatio": 0.1,
"maxCompactionTaskSlots": 2147483647
}
这些操作在前台页面上也可以直接操作。
- 手动提交compact task
bin/post-index-task --file ~/compact.json --url http://coordinator_node:8081
{
"type": "compact",
"dataSource": "druid_recommend_ctr",
"interval": "2019-10-30/2019-10-31"
}
Before compact

After compact

Troubleshoot
Historical 服务启动失败,报错"Cannot allocate memory"

#
# There is insufficient memory for the Java Runtime Environment to continue.
# pthread_getattr_np
# An error report file with more information is saved as:
# /opt/druid-0.16.0/hs_err_pid26261.log
- 这个问题看上去像是堆外内存不足导致的,但是我们机器是128G内存,当前系统仍然有很多的剩余内存可用,尝试了把堆外内存调大,取消堆外内存限制,都没有效果。
- 通过和其他机器上的 Historical 服务做了内存使用量对比,发现使用的堆外内存才几百兆,所以排查堆外内存使用过多的因素。
- 测试发现,服务启动过程中,VIRT Memory 使用可以达到一百多G,所以怀疑是否是因为Virtual Memory使用过大,导致程序shutdown的。通过pmap -d 可以到处进程的Virtual Memory 使用分析,发现主要原因是因为进程打开了非常多的问题,而这些文件会使用到Virtaul Memory. 但是通过限制堆外内存参数,Virtual Memory 的使用可以降下来,但是程序仍然会shutdown。
- 通过Grep 日志,返现程序每次都是打开了6万多个文件后,直接Down掉,SER同事凭借经验,怀疑是系统参数导致。但是当前Linux用户的 ulimit -a 没有限制文件打开个数。
- 通过搜索网上资料,原因是因为Linux 虚拟内存区域打开的文件个数的限制导致的。修改系统参数并生效,程序恢复正常。
操作步骤:
echo "vm.max_map_count=200000" > /etc/sysctl.d/99-druid.conf
sysctl -p /etc/sysctl.d/99-druid.conf
关于虚拟内存区域,个人理解是 Java使用了NIO 的 MappedByteBuffer 技术,将文件映射到内存中,用于加速文件操作,但是linux操作系统中max_map_count限制一个进程可以拥有的VMA(虚拟内存区域)的数量,所以修改参数就好了。
参考资料:
- druid.io问题记录
- 虚拟内存