地图中的语义理解 | 硬创公开课
今年8月,雷锋网将在深圳举办一场盛况空前,且有全球影响力的人工智能与机器人创新大会。届时雷锋网(公众号:雷锋网)将发布“人工智能&机器人Top25创新企业榜”榜单。目前,我们正在拜访人工智能、机器人领域的相关公司,从中筛选最终入选榜单的公司名单。如果你也想加入我们的榜单之中,请联系:[email protected]。
编者按:本文整理自搜狗公司王砚峰在雷锋网硬创公开课上的演讲。王砚峰是搜狗公司桌面事业部高级总监,桌面研究部和语音交互技术中心负责人。承担输入法、号码通、个性化新闻等搜狗桌面产品在大数据和算法研究方面的工作,通过研究能力提升产品核心品质推动产品创新。同时负责搜狗智能语音交互技术,带领语音和语义技术团队实现了业内顶尖的语音交互能力,并致力于智能语音技术的产品化创新。个人主要研究领域为:自然语言处理、机器学习、推荐系统、语义理解、机器智能等。

▎什么是机器语义理解?
语义理解简述
所谓语义理解简而言之就是让机器懂得人的话语,理解人的意图,并且返回给用户相应的答案或者内容,来解决用户需求。如果我们把语音识别作为机器的耳朵,那么语义理解就是机器的大脑。
比如用户问“怎么去天安门”,语义理解需要得到的结果是用户有出行需求,并且出行的目的地是天安门;如果用户问“周围有没有好吃的川菜”,那么用户此时的目的是找餐馆,并且对餐馆的类型有要求,菜系是川菜;如果用户说“我想看一些湖人队最新的消息”,那么此时用户的需求是看一些新闻资讯,主体限定在NBA的湖人队上。
因此可以看到语义理解技术至少有两个关键的因素,第一是自然语言处理技术,利用统计自然语言处理算法提取文本中的实体词以及依存关系;第二是要有全面而丰富的知识库,配合自然语言处理技术,才能得到用户的准确意图。
结合到上面的例子,如果知识库中“天安门”是作为一个地名,那么“怎么去天安门”,就可以被以很高的准确率划分为用户出行意图。但如果地名库中有一个数据叫“黑眼圈”,那么“怎么去黑眼圈”就非常有可能被划分到出行,而不是一个知识问答。

语义理解的三个层次
从大的范畴来讲,我会把语义理解划分为三个层次。
第一个层次,是限定在一个已有服务相对成熟的垂直领域来解决用户的实际需求。比如导航、餐饮、旅馆、天气、音乐等领域,这类问题的特点是用户需求相对收敛,知识库也相对成熟,并且经过了多年的整理和沉淀已经具有一定的结构化特性,知识之间已经不是孤立的知识点,而是通过知识之间的关系连成了网络。“知识图谱”其实就是某种这样的网络。限定在垂直领域的语义理解问题因为用户需求的收敛性和知识库的成熟,技术上会更容易,同时也会更有能力实际的解决用户的问题和需求。据统计,在车内通用安吉星或者丰田GBOOK这种车内call center提供的服务中,80%的需求都是问路或者导航,至少这是可以很大程度上通过机器语义理解解决的。在垂直领域下的语义理解,考验的更多是构建知识库本身的能力。
第二个层次,就是仍然在解决用户的实际问题,但是问题本身已经偏长尾,需求本身更加离散,并且知识也没有很好的结构化。比如“天空为什么是蓝色的”。往往这个时候各个语义理解引擎会借助于搜索引擎,但实际上结果相对能够保证的也只有搜索引擎整理出来的百科和问答资源。尤其对于问答,目前大部分的语义理解引擎仍然是靠搜索方式来解决,通过搜索技术寻找问答库中和用户问题最匹配的问题。而且无论是百度知道还是搜狗问问,问答库中大部分的问答内容其质量本身也不能得到好的判断,更不用说需要从大量文本中抽取整理答案了。这对于自然语言理解技术是非常大的考验,并且目前国内做语义理解的公司整体上都没有很好的效果,也是搜狗目前正在尝试突破的话题。
最高的层次,就是做到跟人一样的交谈。现在市面上的对话机器人,以“小冰”为代表,都在渲染这方面的能力。但实际上目前是做不到的。因为人类在自然对话中,会带入大量的历史信息,场景信息,感情信息以及预先的认知信息,实际上计算机目前从根本上都没有一个好的建模方法来描述人类的思想和认知过程,更不要提在思想活动和认知过程之后产生的语言。因此当前机器在这方面的能力,不要说解决用户实际问题,就连闲聊的对话几轮下来也经不住用户的考验。目前这个能力唯一实际一些的用途的就是在儿童产品中,给没有逻辑能力和判断能力的小朋友带来欢乐。而对于成人,此类产品的用户留存率从来低的可怜。
因此整体上,语义理解这个领域仍然是刚刚开始,虽然经历了不错的发展,但是从技术本质上目前还没有突破。距离很多公司鼓吹的强人工智能,还有很长的路要走。
▎多对话解析
Q:“结合上下文的‘多对话解析’”是如何做到的?其中的难点是什么?
谈多轮对话,先要从单轮对话讲起。单轮对话完全不需要考虑到用户的历史问题,只针对用户当前问题做答。一般是先对问题进行实体词识别,然后再结合实体词上下文对问题进行分类,判断用户的意图分类,然后结合意图分类和实体词,得到用户精确的意图。所以本质上单轮对话的核心是线性分类问题,随着类别的增加,问题本身没有变的更加复杂。并且随着用户数据的累积,分类的训练数据就会不停增加,分类的准确率就会不断提升,这是一个很经典的机器学习的问题。
而多轮对话在单轮对话的基础上引入了上下文,因此当前的状态不仅取决于上文,而且可能取决于上上文或者更远的上文。因此多轮对话实际上是一个有限状态机(简单的说就是是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。),用户从一个状态跳到另一个状态的过程,其实就是一轮交互,而且交互反馈是根据上一个状态生成的。随着类别的增大,状态机的规模会非常大的膨胀起来。如果实现一个静态的状态机,假定用户行为是可预测的,那更多是工程能力上的问题。但实际环境下用户行为往往是不可预测的,会产生出很多新的行为范式,反映出来的就是状态机会增加更多的状态以及状态之间的边,那么如何根据用户产生出来的数据,动态的不停的构建或者调整状态机,这是多轮交互里面最大的难点。因为每自动生成一个状态节点,都需要同时生成一个在这个节点上用户可理解的反馈方式以及抽象概念。
这是我认为多轮对话中最难的部分,也是即使是当前很流行的一些助手类产品都不支持多轮对话的原因。主要是很难根据用户数据自动的把多轮交互的能力构建出来。这部分搜狗目前也不能做到自动,仍然需要人的抽象总结能力的介入,尤其是交互话术,还需要人为来定义。
▎语义理解的准确率
Q:语义理解的准确率,整个行业目前最高能达到多少?如何提高?
这里谈到的准确率主要就是指单轮交互而言了。结合到我在第一个问题中的阐述,语义理解在垂直场景和领域下的准确率已经有了一定的可用性,但是在更开放的场景中以及对话流中,准确率还是低得可怜。
在垂直场景中,假设知识库以及对应的分类模型已经比较完善,在用户常见问题上达到80%以上的准确率是可以的。提高的路径也是比较明确,就是一方面完善知识库的数据能力,另一方面用更多的用户语料提升模型的准确度。
▎ 中英文混合语义的解析
Q:如何解决中英文混合语句的语义分析问题(比如,“帮我呼叫Stephen William Hawking”)?中英文区分的难点在哪?
我认为中英文混合语句的语音分析比纯粹的中文技术上甚至还更容易,因为英文已经是非常好的断句了,而不需要中文还要对分词有所依赖。
目前中英文语义分析问题主要的两个实际难点,一方面目前的语义产品形态上多和语音相结合,语义拿到的是语音识别的结果。然而中英文混合语音识别错误率目前仍然偏高,主要是受到中英文发音建模方式的不同以及语料本身的缺失。错误的中英文语音识别结果会加大语义理解的难度。
另一方面语义理解会非常重的依赖知识和对应的服务,而这方面中国互联网公司和国际上的内容服务商的对接成本和困难要高于国内,但是这个困难不本质。
▎机器对情绪语义的理解
Q:在深度学习的状态下,机器能够对用户的语言习惯适应到什么程度?能理解用户的一些情绪上的语言习惯吗(如讽刺等话语)?
深度学习在语音图像方面取得了重大突破,这些年在自然语言处理方面也取得了可观的进展,体现出来更强的语言理解能力。但是需要强调的是,深度学习比起传统的机器学习模型,主要是通过提升模型的复杂度来增加模型能力。但是模型本身并不能对人类产生语言的方式进行好的建模,本质上还是统计机器学习的范畴,所以会非常大的依赖数据。实际上深度学习本身也是在大数据这个背景下才得以发挥。因此只要有足够的用户话语数据,深度学习还是有能力给出更好的结果。
但是往往用户的语言还是会取决于对话历史,而不是单纯的只看一句话。因此训练一个模型,需要大量的对话数据,深度学习的优势才能体现出来。但目前受限于用户对话内容的隐私保护,业界拿不到足够“大”的数据,因此取得的效果也会很有限。
▎搜狗的技术差异
Q:与科大讯飞、思必驰等同行技术的差异化(包括语音识别、语义/逻辑分析)?
语音识别方面,因为我们具有搜狗输入法这样大的用户产品,因此在获得真实用户语音语料方面,尤其是噪音环境和口音,我们都具有非常大的优势。科大讯飞有自己的输入法,比起来我们的优势还没有那么明显,而相对思必驰云知声这种用户量小的公司而言这个优势是巨大的。
相比科大讯飞,搜狗主要的优势还是在语义理解以及背后的服务上。如前所述,语义理解能力一方面是考验垂直场景的知识能力,另一方面考验搜索问答能力。而这方面搜狗的能力是完备的,具有网页搜索,各类垂搜以及搜狗地图等产品,而这些都是讯飞不具备的。以导航中的多轮交互为例,如果拿不到地图核心的结构化数据,多轮交互是无从谈起的。
比如北京的用户要去化工大学昌平校区,首先化工大学在北京有多个分校,其次每个分校都有多个对应的POI,以及用户很多时候并不具备“化工大学北校区就是昌平校区”这样的知识,只能通过地标的方式“我想去昌平的那个”来描述。因此如果语音交互模块不能深度的理解地图的结构化数据以及地标信息,那么是很难做到智能交互的。
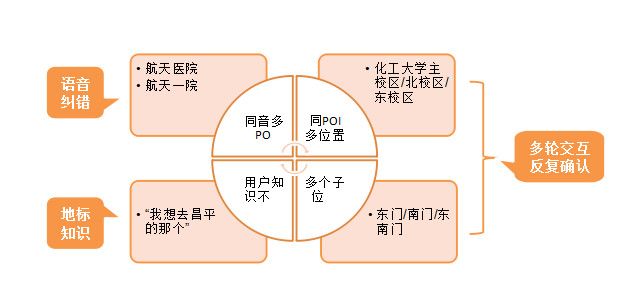
另外搜狗是一个互联网产品公司,用户的理解和产品能力相比起来也会更强,因此在做从技术到产品的转换过程中,我们更有机会做出来用户体验更好价值更大的产品。
▎语音检索功能
Q:有没有机会实现 Google Now 那样的功能?比如语音调取应用,检索其它应用内的信息,自动给出答案。
这个问题不是技术问题而是系统问题。只要从系统权限上可以调用应用,那从语义理解上来讲是非常容易的事情,只是简单地命令识别。
至于检索其他应用内信息,也是主要是否可以拿到应用服务的数据或者借口。比如目前国内餐饮方面的语义理解和服务,大众点评就是非常好的服务方。可以通过合作拿到餐厅的元数据,也可以通过数据协议访问其平台和搜索,这样餐饮的需求就可以直接给出答案。技术上目前都是相对已经很成熟的。
▎对人工智能未来的看法
Q:今年8月,雷锋网将在深圳举办“全球人工智能与机器人创新大会”(简称:GAIR)。想了解下,您对人工智能的未来趋势怎么看?
从大的趋势上来看,人工智能的未来一定是乐观的。目前人工智能有些过热,行业以及媒体对人工智能的期望以及概念的炒作已经远远大于其本身的能力了,不过当一个新兴行业或者产业在被催生的时候,堆泡沫的过程也是必要的。
我个人是个理性的乐观派,我相信未来机器一定能替代人去做更多的事情,但是我比较同意Google吴军老师的观点,所谓的人工智能其实只是机器智能,因为目前机器对事物的理解和人对事物的理解是不一样的。机器智能多数依靠大数据才能完成工作,而人不需要大数据就能去感知、理解和判断事物。但是只要给你机器足够多的数据,机器就能创造出无限的可能。当下我们每天在手机上制造的大量数据,未来的物联网的时代,传感器、camera和mic会进一步带来数据上的爆发。那么机器智能就能借着大数据在各个方面达到更高的高度。就像我们刚才讲的语义理解的问题,之所以在人机对话方面处在这么低的智商水平,也是因为语料库不够大,如果未来大数据充足,我相信,机器智能在语义理解方面一定也能解决更多的问题。
众所周知,在信息处理方面,人工智能主要解决两个问题, 第一个是交互和感知,第二个是信息的获得。交互和感知方面,语音和图像的识别已经取得了长足进步,错误率会越来越低,最终会在技术上彻底解决的。而信息获取方面,我们都在努力让信息有更好的表示以及索引方式,让互联网上的杂乱信息变得更加知识化结构化,甚至会通过语音和图像来索引信息触达信息。 我心目中人工智能的价值就是在于提升我们获取信息的能力和效率、让人与机器的交互更容易、知识获取更容易。在这个方向上,人工智能也一定能取得稳定的健康的发展,逐渐改变我们的生活。
至于让机器有人类的思维包括情感,这与我们目前所讲的机器智能其实本质上不是一码事。这个方向我整体上不看好,也不是我们应该努力的方向,从哲学上说,机器和人只有相互不可替代,才能持续发展。
本文作者:赵青晖
本文转自雷锋网禁止二次转载,原文链接