基于hadoop集群的Hive1.2.1、Hbase1.2.2、Zookeeper3.4.8完全分布式安装
写在前边的话:
hadoop2.7完全分布式安装请参考:点击阅读,继任该篇博客之后,诞生了下面的这一篇博客
基本环境:
Hadoop 2.7
Java 1.7.0_51
CentOS 6.5
预安装:
Hive 1.2.1 下载地址
Zookeeper 3.4.8 下载地址
Hbase 1.2.2 下载地址
一:Hive的分布式安装(基于Mysql)
Hive的伪分布安装请参考 :点击阅读
Hive基于Mysql的伪分布部署轻参考:点击阅读
Hive的完全分布式安装的前提安装Mysql数据库,CentOS 6.5下安装Mysql请参考之前的一篇博客:点击阅读
疑问解答1:Hive 是否需要每个datanode都安装?
Hive的安装其实是有两部分组成,分别是Server端和Client端,所谓的服务端就是Hive管理Meta的那个Hive,服务端可以安装在任意节点上,可以是NameNode,也可以是DataNode,至于那个节点做Hive的服务端,由自己决定,不过在Hadoop的HA环境里,我想在两个NameNode里都装成Hive的Server,并且hive.metastore.warehouse.dir配置成hdfs://****,这样其他节点安装的Hive就都是客户端了,并且hive.metastore.uris值可以指向这两个NameNode的Ip
疑问解答2:Hive配置中主要属性都是什么意思?
hive.metastore.uris:指定hive元数据访问路径,如果为空则是本地模式,否则为远程模式
hive.metastore.warehouse.dir:(HDFS上的)数据目录,可以在3个地方保存
hive.exec.scratchdir:(HDFS上的)临时文件目录
hive.metastore.warehouse.dir默认值是/user/hive/warehouse
hive.exec.scratchdir默认值是/tmp/hive-${user.name}
安装:
1:在Mysql中创建hive用户,并赋予足够的权限
[master@master1 hive]$ mysql -uroot -p
Enter password:
......此处省略部分日志......
mysql> create user 'hive' identified by 'hive';
Query OK, 0 rows affected (0.05 sec)
mysql> grant all privileges on *.* to 'hive' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
2:测试hive能否正常连接Mysql,并创建hive数据库
此时报错如下:ERROR 1045 (28000): Access denied for user 'hive'@'localhost' (using password: YES)
解决办法:重新以root用户登录mysql,删除msyql数据库下user表中为空的记录
mysql> delete from user where user is null;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from user where user='';
Query OK, 1 row affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
[master@master1 opt]$ mysql -uhive -p
Enter password:
....省略....
mysql> create database hive;
Query OK, 1 row affected (0.00 sec)
mysql> use hive;
Database changed
mysql> show tables;
Empty set (0.00 sec)
3:解压缩hive到指定目录
我这里使用的是/opt/ :sudo tar -zxvf /home/master/桌面/apache-hive-1.2.1-bin.tar.gz -C /opt/
重命名为hive:sudo mv apache-hive-1.2.1-bin hive
4:下载Mysql驱动程序到 hive目录下的lib目录
sudo cp /home/master/桌面/mysql-connector-java-5.1.39-bin.jar /opt/hive/lib/
5:修改环境变量将hive加入到path
sudo vim /etc/profile
#hive
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
6:修改hive-env.sh
[master@master1 conf]$ sudo cp hive-env.sh.template hive-env.sh
7:修改hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
hive
username to use against metastore database
javax.jdo.option.ConnectionPassword
hive
password to use against metastore database
8:启动hadoop,测试hive
[master@master1 hadoop]$ sbin/start-all.sh
启动hiev报错:
Exception in thread "main" java.lang.RuntimeException: Hive metastore database is not initialized. Please use schematool (e.g. ./schematool -initSchema -dbType ...) to create the schema. If needed, don't forget to include the option to auto-create the underlying database in your JDBC connection string (e.g. ?createDatabaseIfNotExist=true for mysql)
愿意:没有初始化元数据
解决办法:执行 bin/schematool -initSchema -dbType mysql
再次启动hive:bin/hive,报错:
Exception in thread "main" java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
原因:路径不对
解决办法:将含有system:java.io.tmpdir的配置项改为/opt/hive/iotmp (前提是你已经建立了这样一个文件夹)
再次启动hive报错:
Exception in thread "main" java.lang.RuntimeException: java.io.IOException: 权限不够
解决办法:[master@master1 hive]$ sudo chmod 777 iotmp/
再次启动: yes!!!
9:配置hive的web访问页面
hive1.2.1 lib目录下不带hwi文件,所以需要我们自己打包,下载apache-hive-1.2.1-src.bin.tar 解压,进入hwi 目录执行:
jar cvfM0 hive-hwi-1.2.1.war -C web/ .
并将打好的war包cp到hive/lib目录下,此时仍然不能访问 hive的web界面,出现错误:
NO JSP Support for /hwi, did not find org.apache.jasper.servlet.JspServlet
解决办法:下载以下jar包,放到hive/lib目录下(点击下载)
commons-el-1.0.jar
jasper-compiler.jar
jasper-runtime.jar
toos.jar(java/lib 目录下的一个包)
再次启动 OK!
10、hiveserver2的配置使用
http://www.tuicool.com/articles/Bbqaea
参考网上的文章进行配置发现我的hiveserver2一直启动不了,每当执行bin/hive --service hiveserver2 时总是卡在那里不动,折腾了大半天也一直没有找到错误,就先这样吧,各位博友大家如果有什么好的意见欢迎留言
二:Zoookeeper的分布式安装
1:部署说明
ZK官网建议安装在至少3台机器上,故这里将ZK分别安装三台机器组成的集群中
2:解压到指定目录/opt
sudo tar -zxvf /home/master/桌面/zookeeper-3.4.8.tar.gz -C /opt/
重命名:mv zookeeper-3.4.8/ zookeeper
3:设置myid
在dataDir指定的数据目录(/opt/zookeeper/data)下,创建文件myid,文件内容为一个正整数值,用来唯一标识当前机器,因此不同机器的数值不能相同,建议从1开始递增标识,以方便记忆和管理。
IP 标识数值
192.168.48.130 1
192.168.48.131 2
192.168.48.132 3
4:修改conf/zoo.cfg
tickTime=2000
5:启动zk
每台机器上执行:[master@master1 zookeeper]$ sudo bin/zkServer.sh start
我们可以使用 sudo bin/zkServer.sh status 查看状态
sudo bin/zkServer.sh stop 停止服务
6:遇到的问题
[master@master1 zookeeper]$ sudo bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
解决办法:
查看 zookeeper.out 可知是权限问题
在每台机器下给 data ,data/zookeeper_server.pid,zookeeper.out 777 权限即可
7:注意事项
由于zkServer必须三台都启动后才选择leader和follower,故刚开始会出现都是Error contacting service. It is probably not running.的情况
8:验证如下



三:Hbase的分布式安装
1:部署说明
基于hadoop 2.7 ,ZK 3.4.8部署
2:解压hbase 1.2.2到指定目录
tar -zxvf hbase-1.2.2-bin.tar.gz -C /opt/hbase
mv /opt/hbase-1.2.2 /opt/hbase # 重命名3:配置环境变量
sudo vim /etc/profile
加入:
#hbase
export HBASE_HOME=/opt/hbase
export PATH=$HBASE_HOME/bin:$PATH4:配置hbase-env.sh
export JAVA_HOME=/opt/java
export HBASE_CLASSPATH=/opt/hbase/conf
# 此配置信息,设置由zk集群管理,故为false
export HBASE_MANAGES_ZK=false
export HBASE_HOME=/opt/hbase
export HADOOP_HOME=/oopt/hadoop
#Hbase日志目录
export HBASE_LOG_DIR=/opt/hbase/logs5:配置hbase-site.xml
hbase.rootdir
hdfs://192.168.48.130:9000/hbase
hbase.cluster.distributed
true
hbase.master
master1:60000
hbase.zookeeper.property.dataDir
/opt/zookeeper
hbase.zookeeper.quorum
master1,slave1,slave2
hbase.zookeeper.property.clientPort
2181
6:配置regionservers
清空该文件,加入集群的节点,例如我这里是
slave1
slave2
7:将hbase scp到节点
sudo scp /opt/hbase slave1:/opt/hbase
sudo scp /opt/hbase slave1:/opt/hbase
8:启动
启动之前得保证ZK和hadoop已经启动
[master@master1 hbase]$ bin/start-hbase.sh9:错误记录
启动时会报出权限不足的问题,我这里的解决办法是给每个节点的hbase目录赋予777的权限,但这并不是安全的,如果大家有什么好的办法,可以留下
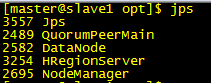
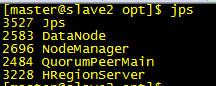
最终jps效果如下:

10:Web界面访问
貌似从1.0版本以后端口改为16010端口了,所以web访问为:http://192.168.48.130:16010/

四:知识点补充和资料参考
1:知识点补充
scp文件: scp name slave1:/path
scp文件夹:scp -r name slave1:/path
2:参考资料
彻底弄清Hive安装过程中的几个疑问点
hbase0.96与hive0.12整合高可靠文档及问题总结
3:一些疑问
这里并不需要将Hive拷贝到各个节点,是因为,这里Hive的底层数据存储为HDFS,而HDFS本身就是分布式的,所以不需要,当然这里也可以把Hive安装到slave节点上,但是出于方便和使用习惯,一般都部署在namenode上
大数据全新视频教程,博主亲自整理,点击查看