一、一句话介绍
聚类通常是指,对于未标记训练样本,根据样本的内在相似性,将样本划分为若干个不相交子集的学习算法。
二、最简单的例子
一个不是很恰当的例子。刚上大学的时候,大家来自天南海北,是一个个单独的个体。过一段时间以后,大家或是因为相同的兴趣爱好,或是因为喜欢打同一个游戏,或是因为同一个宿舍,总之因为某种相似性,会形成不同的团团伙伙。
三、K均值算法(K-Means)
3.1、K均值算法的意义
K均值算法是最简单的聚类算法,也是最能简明地说明聚类思想和聚类过程的聚类算法,凡是讲聚类的教材(大多)都会先讲K均值聚类。
K均值聚类算法也包含了朴素的期望最大化(Expectation Maximization)思想,在吴军博士的著作《数学之美》[1]中,吴军博士就是用K均值算法举例期望最大化算法的。
3.2、算法描述

3.3、K均值算法的缺点
A、是局部最优解,而不是全局最优解。这与初始聚类簇中心有关,也就是说,聚类结果对初始聚类簇中心敏感。
B、对样本分布敏感:对球形分布的数据聚类效果好,对非球形样本聚类效果不好,尤其是带状、环状样本聚类效果很差;对离群点敏感。
C、其他缺点。
四、聚类算法的种类[2]
根据聚类算法实现大的基本原理,聚类算法主要有以下几种:
4.1、顺序算法(Sequential Algorithm)
基本顺序算法方案(Basic Sequential Algorithm Scheme,BSAS)最能说明顺序算法的算法思想:给定相似性度量阈值和最大聚类数,按照顺序给样本分类,根据样本到已有聚类的距离,满足一定条件将其分配到已有聚类中,不满足条件则划分到新生成的聚类中。
4.2、层次聚类算法(Hierarchical Clustering Algorithm)
又分为合并算法和分裂算法。合并算法在每一步减少聚类数量,聚类结果来自于前一步的两个聚类的合并;分裂算法原理正好相反。
4.3、基于代价函数最优的聚类算法(Clustering Algorithm based on Cost Function Optimization)
使用代价函数来量化判断,当代价函数达到局部最优时,算法结束。K均值算法如果采用欧式距离作为相似性度量的话,其代价函数是平方误差和
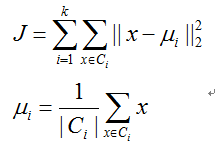
代价函数J不是凸函数。
高斯混合聚类(Mixture-of-Gaussian)是另一个比较有名的此类算法。
4.4、基于密度的算法(Density-based Algorithm)
该类算法把聚类视为空间中数据较为密集的区域。DBSCAN就是一种著名的密度聚类算法。
值得一提的是,2014年6月Alex Rodriguez, Alessandro Laio在《Science》期刊上发表了一篇论文,"Clustering by fast search and find of density peaks",论文中提出了一种非常巧妙的聚类算法。
4.5、其他算法
五、聚类的几个问题
5.1、相似性度量
无论哪种算法,都离不开相似性度量,只有相似性度量可以说明样本之间的相似性。相同的样本集,选择相同的算法,选择不同的相似性度量,可能聚类的结果就会不同。
我在另一篇笔记中整理了一下常用的相似性度量,《相似性度量》。
5.2、聚类准则
如4.3所述,基于代价函数最优的聚类算法都需要一个聚类准则,K均值算法的聚类准则是最小平方误差和;高斯混合聚类聚类准则是最大化样本出现的概率。
5.3、性能度量
聚类性能度量也称为聚类有效性指标(Vadility Index),通过某种度量来评估聚类结果的好坏。[3]
5.4、超参数
超参数,我的理解就是需要先验地假设一些参数值,这些参数是聚类过程的基础参数。
很多聚类算法需要有超参数。K均值算法需要预先设定聚类簇数k;DBSCAN需要预先设定邻域参数和簇内最少样本,等等。
超参数的确定有很多方法,比如K均值算法聚类簇数k可通过称作“肘部法则[4]”的方法确定
六、参考
[1]、《数学之美》,吴军著
[2]、《模式识别(第四版)》,Sergios Theodoridis等著,李晶皎等译
[3]、《模式识别》,周志华著
[4]、《斯坦福大学2014机器学习教程个人笔记完整版v4.21》,黄广海整理