为什么说元类是你最常使用却也最陌生的Python语言特性之一?
文章目录
- 一、`type`的二义性
- 1. `class type(object)`
- 2. `class type(name, bases, dict)`
- 二、自定义一个元类
- 三、元类的应用
- 1. 用元类验证子类
- 2. 用元类来注册子类
- 四、参考资料
虽然很多人都知道Python是一门纯粹的面向对象语言,这意味着在Python中一切皆为对象,但是很多人可能不了解的一点是类也是一种对象。那么自然地,有人可能会问:类作为一种对象是由什么创建的?
实际上,稍微接触过面向对象编程的人都知道,类是用来创建对象的模板,这对于类作为对象这一点来说也是适用的,只不过此时用来创建类对象的类是元类(metaclass)。所以,只要你在Python代码中使用了class关键字来创建一个类,你就一定会无意识地用到元类。
一、type的二义性
对于type,你很大可能用过它来查看一个对象的类型,如:
In[5]: type("This is a string")
Out[5]: str
In[6]: type(123)
Out[6]: int
In[7]: type(12.3)
Out[7]: float
In[8]: type({"name":"Pythonista", "age":28})
Out[8]: dict
In[9]: type([1, 2, 3])
Out[9]: list
In[10]: type((1, 2, 3))
Out[10]: tuple
但你可能不知道的是,虽然type看起来像是一个Python的普通內置函数,可以用它来查看一个对象的类型,但实际上它就是本文的主角元类。至于为什么大多数人并不知道这一点,这是因为type类根据传入的参数不同可以实现两种不同的功能(实际上,根据传入参数不同让一个函数实现不同功能是很不好的编码习惯,这里type之所以是这样,是Python语言为了考虑向后的兼容性):
1. class type(object)
此时type接收任何一个对象作为参数,其结果和object.__class__完全一样,通常我们所使用的都是type的这一原型,如:
class Foo:
pass
def main():
obj = Foo()
print(obj.__class__)
print(type(obj))
print(obj.__class__ is type(obj))
if __name__ == '__main__':
main()
上述代码的运行结果为:
True
实际上,利用type的这一功能就可以揭露其另一面的神秘面纱,即作为创建类对象的元类,请看下列代码:
class Foo:
pass
def main():
obj = Foo()
print(f"type(obj) = ", type(obj))
print(f"type(Foo) = ", type(Foo))
for cls in int, float, dict, list, tuple:
print(type(cls))
print(type(type))
if __name__ == '__main__':
main()
上述代码的运行结果为:
type(obj) =
type(Foo) =
由上述代码及其运行结果,可知:
- 对于通过
Foo类创建的对象,对其使用type,其结果为本模块中的类Foo,这是大多数人都了解的; - 对于
Foo类,由于其本身也是一个对象,则自然也可以使用type,且结果为类type,即type类创建了类对象Foo; - 进一步地,对于Python的各种內置数据类使用
type,得到的结果依然是类type; - 更进一步地,
type(type)的结果依然是类type。
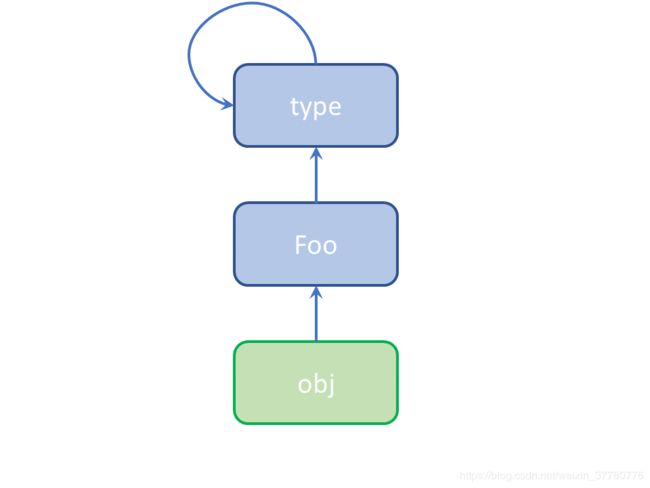
通过以上的分析,你可能对于type是Python中创建所有类对象的元类这一点有了一些认识,且type类和类对象以及由普通类创建的对象之间有如下图所示的关系。
2. class type(name, bases, dict)
此时type接收三个参数,可用来创建一个类对象:
name:该参数用于指定待创建类对象的名字,即该类__class__属性的值;bases:该参数用于以元组形式指定待创建类所继承自的父类,后续可通过该类的__bases__属性获取;dict:该参数用于指定待创建类中的属性、方法等,后续可通过该类的__dict__属性来获取。
通过上述方式调用元类type将创建类的对象,即一个普通的类,如下列几段代码所示。需要指出的是,下面示例代码中,每一段都是先用class关键字创建一个类,然后使用type创建一个类,以显示这两种方式的等价性:
- 案例一:此时参数
bases和dict分别为空元组和空字典,即此时所要创建的类不继承自任何父类(实际上,在Python 3中,type类的源码显示其继承自object类,则type元类继承了所有object类所具有的方法,从而使得所有经由type元类创建的类对象也都具有这些方法,从而实现了在Python 3中,所有的类默认继承object类的效果),且类中未定义任何属性或方法:
class Foo1:
pass
def main():
obj1 = Foo1()
print(obj1)
Foo2 = type("Foo2", (), {})
obj2 = Foo2()
print(obj2)
if __name__ == '__main__':
main()
上述代码的运行结果为:
<__main__.Foo1 object at 0x7f1d4873c4e0>
<__main__.Foo2 object at 0x7f1d4873c5f8>
- 案例二:参数
bases是一个元素仅为Foo的元组,即指定Bar类的父类是Foo,且该类有一个attr的属性:
class Foo:
pass
class Bar1(Foo):
attr = 100
def main():
bar1 = Bar1()
print("bar1.attr = ", bar1.attr)
print("bar1.__class__ = ", bar1.__class__)
print("bar1.__class__.__bases__ = ", bar1.__class__.__bases__)
bar2 = type("Bar2", (Foo,), dict(attr=100))
print("bar2.attr = ", bar2.attr)
print("bar2.__class__ = ", bar2.__class__)
print("bar2.__class__.__bases__ = ", bar2.__class__.__bases__)
if __name__ == '__main__':
main()
上述代码的运行结果为:
bar1.attr = 100
bar1.__class__ =
bar1.__class__.__bases__ = (,)
bar2.attr = 100
bar2.__class__ =
bar2.__class__.__bases__ = (,)
- 案例三:此时,参数
bases仍为空元组,但通过dict参数指定了待创建类中有一个属性和一个方法:
class Foo1:
attr = 100
def attr_val(self):
return self.attr
def main():
foo1 = Foo1()
print("foo1.attr = ", foo1.attr)
print("foo1.attr_val() = ", foo1.attr_val())
# Foo2 = type("Foo2", (), {"attr": 100, "attr_val": lambda obj: obj.attr})
Foo2 = type("Foo2", (), dict(attr=100, attr_val=lambda obj: obj.attr))
foo2 = Foo2()
print("foo2.attr = ", foo2.attr)
print("foo2.attr_val() = ", foo2.attr_val())
if __name__ == '__main__':
main()
上述代码的运行结果为:
foo1.attr = 100
foo1.attr_val() = 100
foo2.attr = 100
foo2.attr_val() = 100
- 案例四:在案例三中,在定义类对象中的方法时使用了lambda表达式,而一般只有定义非常简单的函数时才使用lambda表达式,于是该案例对案例三做了修改,使用
def关键字在type外部定义了一个复杂一点的函数,然后通过引用将函数名传给了type类的dict参数处:
def func(obj):
print('attr =', obj.attr)
class Foo1:
attr = 100
attr_val = func
def main():
foo1 = Foo1()
print("foo1.attr = ", foo1.attr)
foo1.attr_val()
Foo2 = type("Foo2", (), dict(attr=100, attr_val=func))
foo2 = Foo2()
print("foo2.attr = ", foo2.attr)
foo2.attr_val()
if __name__ == '__main__':
main()
二、自定义一个元类
实际上,在Python中当解释器执行到使用class关键字声明类的代码时,就会调用元类type来创建一个类对象(如前文中的Foo),只是此时type类创建类对象时不会做额外的工作,但如果我们的确希望在创建类对象时做一些额外的工作,就需要自定义一个元类。
对于自定义一个元类,我们只要想着元类归根结底也是一个类,既然如此其必定可以被继承,则自定义一个元类的方法是:
- 定义一个类,让其继承自
type类; - 在自定义的类中进行希望创建类对象时要进行的操作。
为了演示自定义元类的方法,下面代码通过自定义元类实现这样一个需求:将某个类对象中的属性转换为全大写形式。
class UpperAttrMetaclass(type):
def __new__(cls, name: str, bases, attrs):
uppercase_attr = {attr if attr.startswith("__") else attr.upper(): value
for attr, value in attrs.items()
}
return type(name, bases, uppercase_attr)
class Foo(metaclass=UpperAttrMetaclass): # 1
bar = 'bip'
def main():
print(hasattr(Foo, 'BAR'))
print(hasattr(Foo, 'bar'))
print(Foo.BAR)
if __name__ == '__main__':
main()
上述代码的运行结果为:
True
False
bip
由于定义一个类时,其默认元类为type,如果希望使用自定义的元类,则需要像# 1处代码一样采用关键字参数的形式显式指定使用自定义元类。
上述代码在语法上没有任何问题,只是我们直接调用了type,实际上因为类对象的创建是由type中的__new__方法完成的,我们只需要调用该方法即可,此时当Python解释器执行完class语句体后会把其中相关内容发送给元类的__new__方法:
class UpperAttrMetaclass(type):
def __new__(cls, name: str, bases: Tuple[Any], attrs: Dict):
uppercase_attr = {attr if attr.startswith("__") else attr.upper(): value
for attr, value in attrs.items()
}
return type.__new__(cls, name, bases, uppercase_attr)
实际上,更加Pythonic的做法是使用super()函数:
class UpperAttrMetaclass(type):
def __new__(cls, name: str, bases: Tuple[Any], attrs: Dict):
uppercase_attr = {attr if attr.startswith("__") else attr.upper(): value
for attr, value in attrs.items()
}
return super(UpperAttrMetaclass, cls).__new__(cls, name, bases, uppercase_attr)
三、元类的应用
1. 用元类验证子类
元类最简单的一种用途,就是验证某个类定义得是否正确。当构建复杂的类体系时,我们可能需要确保类的风格协调一致、确保某些方法得到重写,或是确保类属性之间具备某些严格的关系。元类提供了一种可靠的验证方式,每当开发者定义新的类时,它都会运行验证代码,以确保这个新类符合预定的规范。
例如,现在要用一个父类来表示任意多边形,要求定义一个元类来实现这样一个验证功能:要求继承多边形这个父类的子类,其边数属性sides必须不小于3,即:
class ValidatePolygon(type):
def __new__(cls, name, bases, dict):
if bases != (object,): # 确保验证的是Polygon的子类,即只有Polygon的直接父类才是object
if dict["sides"] < 3:
raise ValueError("Polygon needs 3+ sides")
return super(ValidatePolygon, cls).__new__(cls, name, bases, dict)
class Polygon(object, metaclass=ValidatePolygon):
sides = None
@classmethod
def inferior_angles(cls):
return (cls.sides - 2) * 180
class Triangle(Polygon):
sides = 3
print("Before class definition")
class Line(Polygon):
print("Before sides assignment")
sides = 1
print("After sides assignment")
print("After class definition")
运行上述代码的结果为:
(
,)
Before class definition
Before sides assignment
After sides assignment
Traceback (most recent call last):
File “…/validate_polygon.py”, line 26, in
class Line(Polygon):
File “…/validate_polygon.py”, line 5, in __new__
raise ValueError(“Polygon needs 3+ sides”)
ValueError: Polygon needs 3+ sides
结合上述代码和其运行结果,我们知道:
- 如果开发者尝试定义一个边数少于3的多边形,那么
class语句体刚结束,元类中的验证代码就会拒绝创建这个类对象,那么程序根本就无法运行; - 通过程序的几个打印语句我们还可以知道,Python解释器会在子类
Line的语句体运行完毕之后,才会调用元类中的__new__方法。
2. 用元类来注册子类
元类还有一个用途,就是在程序中自动注册类型。对于需要反向查找的场合,这种注册操作是很有用的,它使我们可以在简单的标识符与对应的类之间,建立映射关系。
例如,我们想按照自己的实现方式,将Python中的对象表示为JSON格式的序列化数据,那么,就需要一种手段,把指定的对象转换成JSON字符串。
在下面的代码中,我们:
- 首先定义了一个通用的基类
Serializable,它可以记录程序调用本类__init__方法时所用的参数,并将其转换为JSON字典; - 其次定义了一个
Point2D类,并继承了Serializable类,使之可以很容易就可以被转换为字符串(关于Point2D中定义的__repr__方法作用,请见对象的字符串表示形式之repr、__repr__、str、__str__)。
import json
class Serializable(object):
def __init__(self, *args):
self.args = args
def serialize(self):
return json.dumps({'args': self.args})
class Point2D(Serializable):
def __init__(self, x, y):
super().__init__(x, y) # 调用父类的__init__方法来初始化继承自父类的self.args属性
self.x = x
self.y = y
def __repr__(self):
return f'Point2D({self.x}, {self.y})'
def main():
point = Point2D(5, 3)
print('point = ', point)
print("Serialized point = ", point.serialize())
if __name__ == '__main__':
main()
上述代码的运行结果为:
point = Point2D(5, 3)
Serialized point = {“args”: [5, 3]}
现在,如果我们需要对这种JSON字符串执行反序列化操作,并构建出该字符串所表示Point2D对象。下面定义了一个Deserializable类,其继承自Serializable类,它可以把Serializable所产生的JSON字符串还原为Python对象。
import json
class Serializable(object):
def __init__(self, *args):
self.args = args
def serialize(self):
return json.dumps({'args': self.args})
class Deserializable(Serializable):
@classmethod
def deserialize(cls, json_data):
params = json.loads(json_data)
return cls(*params['args']) # 使用×对字典键所对应值进行拆包
class EnhancedPoint2D(Deserializable):
def __init__(self, x, y):
super().__init__(x, y) # 调用父类的__init__方法来初始化继承自父类的self.args属性
self.x = x
self.y = y
def __repr__(self):
return f'EnhancedPoint2D({self.x!r}, {self.y!r})'
def main():
enhanced_point = EnhancedPoint2D(5, 3)
print('Before serialization, enhanced_point = ', enhanced_point)
json_data = enhanced_point.serialize()
print('Serialized enhanced_point = ', json_data)
print('After deserialization, enhanced_point = ', EnhancedPoint2D.deserialize(json_data))
if __name__ == '__main__':
main()
上述代码的运行结果为:
Before serialization, enhanced_point = EnhancedPoint2D(5, 3)
Serialized enhanced_point = {“args”: [5, 3]}
After deserialization, enhanced_point = EnhancedPoint2D(5, 3)
上述方案的缺点是,我们必须提前知道序列化的数据是什么类型(例如,是Point2D还是EnhancedPoint2D等),然后才能对其做反序列化操作。
理想的方案应该是:很多类都可以把本类对象转换为JSON格式的序列化字符串,但是只需要一个公用的反序列化函数,就可以将任意的JSON字符串还原成相应的Python对象。
为此,我们:
- 首先,把序列化对象的类名写到JSON数据里面;
- 然后,把类名与类对象的引用之间的映射关系,维护一份到字典中,这样凡是经由
register_class注册的类,就可以拿通用的deserialize函数做反序列化操作。
import json
class EnhancedSerializable(object):
def __init__(self, *args):
self.args = args
def serialize(self):
return json.dumps({
'class': self.__class__.__name__,
'args': self.args
})
registry = dict()
def register_class(target_class):
registry[target_class.__name__] = target_class
def deserialize(json_data):
params = json.loads(json_data)
name = params['class']
target_class = registry[name] # 1
return target_class(*params['args']) # 使用×对字典键所对应值进行拆包
class EvenBetterPoint2D(EnhancedSerializable):
def __init__(self, x, y):
super().__init__(x, y) # 调用父类的__init__方法来初始化继承自父类的self.args属性
self.x = x
self.y = y
def __repr__(self):
return f'EvenBetterPoint2D({self.x!r}, {self.y!r})'
register_class(EvenBetterPoint2D)
def main():
point = EvenBetterPoint2D(5, 3)
print('Before serialization, point = ', point)
json_data = point.serialize()
print('Serialized point = ', json_data)
print('After deserialization, point = ', deserialize(json_data))
if __name__ == '__main__':
main()
Before serialization, point = EvenBetterPoint2D(5, 3)
Serialized point = {“class”: “EvenBetterPoint2D”, “args”: [5, 3]}
After deserialization, point = EvenBetterPoint2D(5, 3)
上述方案也有缺点,那就是开发者很可能会忘记调用register_class函数,此时程序运行至上述代码的# 1处会产生错误。
对于上述缺点,我们应该想个办法,保证开发者在继承EnhancedSerializable定义子类的时候,程序会自动调用register_class函数,并将新的子类注册号,这个功能就可以通过元类来实现:
import json
class EnhancedSerializable(object):
def __init__(self, *args):
self.args = args
def serialize(self):
return json.dumps({
'class': self.__class__.__name__,
'args': self.args
})
def __repr__(self): # __repr__方法可定义在此处,被所有待序列化对象继承之后使用
return f'{self.__class__.__name__}{self.args}'
registry = dict()
def deserialize(json_data):
params = json.loads(json_data)
name = params['class']
target_class = registry[name]
return target_class(*params['args']) # 使用×对字典键所对应值进行拆包
def register_class(target_class):
registry[target_class.__name__] = target_class
class Meta(type):
def __new__(meta, name, bases, dict):
cls = super().__new__(meta, name, bases, dict)
register_class(cls)
return cls
class RegisteredSerializable(EnhancedSerializable, metaclass=Meta):
pass
class Vector3D(RegisteredSerializable):
def __init__(self, x, y, z):
super(Vector3D, self).__init__(x, y, z)
self.x, self.y, self.z = x, y, z
def main():
point = Vector3D(5, 3, 2)
print('Before serialization, point = ', point)
json_data = point.serialize()
print('Serialized point = ', json_data)
print('After deserialization, point = ', deserialize(json_data))
if __name__ == '__main__':
main()
Before serialization, point = Vector3D(5, 3, 2)
Serialized point = {“class”: “Vector3D”, “args”: [5, 3, 2]}
After deserialization, point = Vector3D(5, 3, 2)
四、参考资料
- [1] Python Metaclasses
- [2] What are metaclasses in Python?
- [3] Implementing an Interface in Python
- [4] 两句话掌握 Python 最难知识点:元类
- [5] 编写高质量Python代码的59个有效方法