(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning
计划完成深度学习入门的126篇论文第十八篇,Andrew Y. Ng和Jeff Dean合作研究使用大量数据模型的无监督学习方式。
ABSTRACT&INTRODUCTION
摘要
我们考虑仅从未标记的数据构建高级的、特定于类的特征检测器的问题。例如,是否可以只使用未标记的图像来学习人脸检测器?为了解决这个问题,我们训练了一个9层局部连接的稀疏自动编码器,它具有对一个大的图像数据集(模型有10亿个连接,数据集有1000万张从互联网上下载的200x200像素图像)进行池化和局部对比度规范化。我们使用模型并行性和异步SGD在一个包含1000台机器(16000个核心)的集群上训练这个网络三天。与人们普遍持有的直觉相反,我们的实验结果表明,训练人脸检测器是有可能的,而不需要将图像贴上是否包含人脸的标签。控制实验表明,该特征检测器不仅对平移具有较强的鲁棒性,而且对缩放和平面外旋转也具有较强的鲁棒性。我们还发现,同样的网络对猫脸和人体等其他高级概念也很敏感。从这些学习到的特性开始,我们训练我们的网络在从ImageNet识别22,000个对象类别时获得了15.8%的准确率,比以前的最先进水平提高了70%
介绍
这项工作的重点是从未标记的图像构建高级的、特定于类的特征检测器。例如,我们想知道是否有可能仅从未标记的图像构建人脸检测器。这种方法的灵感来自于神经科学的猜想,即人类大脑中存在高度的类特异性神经元,通常被非正式地称为祖母神经元。”class-specificity程度的大脑神经元的调查是一个活跃的领域,但目前的实验证据表明颞叶皮层的一些神经元可能是高度选择性的脸或手等对象类别(Desimone, et al ., 1984),甚至特定的人(Quiroga et al ., 2005)。
现代计算机视觉方法通常强调标记数据的作用,以获得这些类特定的特征检测器。例如,要构建人脸检测器,需要大量标记为包含人脸的图像集合,通常在人脸周围有一个包围框。对大型标记集的需求对标记数据很少的问题提出了一个重大挑战。虽然使用廉价的未标记数据的方法通常是首选的,但是它们在构建高级特性方面并没有显示出很好的效果。
这项工作研究了仅从未标记的数据构建高层特性的可行性。对这个问题的积极回答将产生两个重要的结果。实际上,这为从未标记的数据开发特性提供了一种廉价的方法。但也许更重要的是,它回答了一个有趣的问题,即祖母神经元grandmother neuron的特异性“是否可能从未标记的数据中学到”。非正式地说,这意味着婴儿至少在原则上有可能学会把脸分成一个班级因为它看到了很多,而不是因为它受到监督或奖励的引导。
无监督特征学习和深度学习已经成为机器学习中从无标记数据构建特征的方法。使用野外未标记的数据来学习特性是自学学习框架背后的关键思想(Raina et al., 2007)。成功的特征学习算法及其应用可以在最近的文献中发现,使用各种方法,如RBMs (Hinton et al., 2006), autoencoders (Hinton &Salakhutdinov, 2006;Bengio等,2007),稀疏编码(Lee等,2007)和K-means (Coates等,2011)。到目前为止,这些算法中的大多数只成功地学习了底层特性,比如\edge“或\blob”检测器。超越这些简单的特性并捕获复杂的不变性是这项工作的主题。
最近的研究发现,训练深度学习算法以获得最先进的结果是相当耗时的(Ciresan et al., 2010)。我们推测,较长的训练时间是文献报道缺乏高水平特征的部分原因。例如,研究人员通常会减少数据集和模型的大小,以便在实际时间内训练网络,而这些减少会破坏对高级特性的学习。
我们通过扩展训练深度网络涉及的核心组件来解决这个问题:数据集、模型和计算资源。首先,我们使用从随机YouTube视频中随机抽取帧生成的大数据集。我们的输入数据为200x200张图像,远远大于深度学习和无监督特征学习中使用的典型32x32张图像(Krizhevsky, 2009;Ciresan等,2010;Le et al., 2010;Coates等,2011)。我们的模型是一个带有池和局部对比度标准化的深度自动编码器,通过使用大型计算机集群将其扩展到这些大图像。为了支持这个集群上的并行性,我们使用了局部接受域的概念,例如(Raina et al., 2009;Le et al., 2010;2011 b)。这个想法减少了机器之间的通信成本,因此允许模型并行性(参数分布在机器之间)。异步SGD用于支持数据并行性。该模型在一个拥有1000台机器(16,000个核心)的集群上进行了为期三天的分布式培训。
使用分类和可视化的实验结果证实了从未标记的数据构建高层特征是可能的。特别是,使用由人脸和干扰物组成的保留测试集,我们发现了一个对人脸具有高度选择性的特性。这与(Lee et al., 2009)的工作不同,他们将模型训练在一个类的图像上。通过数值优化得到可视化结果。控制实验表明,该检测器不仅对平移不变性,而且对平面外旋转和缩放也不变性。
类似的实验表明,该网络还能学习猫脸和人体的概念。
学习表征也是有区别的。利用所学习的特征,我们在ImageNet的目标识别方面取得了显著的飞跃。例如,在包含22,000个类别的ImageNet上,我们的准确率达到了15.8%,相对于目前的水平提高了70%。注意,对于这个数据集,随机猜测的准确率低于0.005%。
2. Training set construction
我们的训练数据集是通过从1000万个YouTube视频中抽取帧来构建的。为了避免重复,每个视频只向数据集提供一个图像。每个示例都是一个200x200像素的彩色图像。附录A中显示了训练图像的子集。为了检查数据集中人脸的比例,我们在数据集中随机采样的60x60个补丁上运行OpenCV人脸检测器(http://opencv.willowgarage.com/wiki/)。本实验表明,OpenCV人脸检测器检测到的人脸斑块在10万个样本斑块中所占比例不足3%。
3. Algorithm
在本节中,我们将描述用于从未标记的训练集中学习特性的算法。
3.1. Previous work
我们的工作受到最近成功的无监督特征学习和深度学习算法的启发(Hinton et al., 2006;Bengio等,2007;Ranzato等,2007;Lee等人,2007)。它深受(Olshausen & Field, 1996)稀疏编码的影响。根据他们的研究,稀疏编码可以在未经标记的自然图像上训练,产生类似于V1简单细胞(Hubel & Wiesel, 1959)。
早期方法如稀疏编码(Olshausen ;Field, 1996)是他们的架构是浅层的,通常捕获低级的概念(例如edge \Gabor“过滤器”)和简单的不变性。解决这个问题是最近深度学习研究的一个重点(Hinton et al., 2006; Bengio et al., 2007; Bengio & LeCun, 2007; Lee et al., 2008; 2009),它构建特性表示的层次结构。尤其是Lee等(2008)的研究表明,堆叠稀疏RBMs可以对皮层V2区的某些简单功能进行建模。他们也证明了这一点体积DBNs (Lee et al., 2009)通过训练人脸的对齐图像,可以学习人脸检测器。这个结果很有趣,但不幸的是,在数据集构建过程中需要一定程度的监督:它们的训练图像(即。)是对齐的,同质的,属于一个选定的类别。
3.2. Architecture
我们的算法建立在这些思想的基础上,可以看作是一个稀疏的深层自动编码器,它有三个重要的组成部分:局部接受域、池和局部对比度标准化。首先,为了将自动编码器扩展到大型图像,我们使用了一个简单的概念,称为局部接受域(LeCun et al., 1998; Raina et al., 2009; Lee et al., 2009; Le et al., 2010)。这个受生物学启发的想法提出,自动编码器中的每个特性只能连接到底层的一个小区域。其次,为了实现局部形变的不变性,我们使用了局部L2池(Hyv¨arinen et al., 2009; Gregor & LeCun, 2010; Le et al., 2010)和局部对比归一化(Jarrett et al., 2009)。尤其是L2池,它允许学习不变的特性(Hyv¨arinen et al., 2009; Le et al., 2010)。
我们的深度自动编码器是通过复制三次相同的阶段组成的本地过滤,本地池和本地对比度正常化。一个阶段的输出是下一个阶段的输入,整个模型可以解释为一个九层的网络(见图1)。
![(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning_第1张图片](http://img.e-com-net.com/image/info8/93e9abd720dd442d82136c8d8de3cb29.jpg)
第三个子层执行局部减法和分裂归一化,其灵感来自生物学和计算模型(Pinto et al., 2008; Lyu & Simoncelli, 2008; Jarrett et al., 2009)。如上所述,我们研究方法的核心是使用神经元之间的局部连接。
在我们的实验中,第一个子层的接受域为18x18像素,第二个子层池超过5x5个重叠的特征邻域(即池的大小)。第一个子层中的神经元连接到所有输入通道(或映射)中的像素,而第二个子层中的神经元只连接到一个通道(或映射)的像素。当第一个子层输出线性滤波器响应时,池层输出其输入平方和的平方根,因此称为L2池。
我们堆叠一系列统一模块的风格,在选择性和耐受性层之间切换,让人想起新认知(Neocognition)和HMAX(Fukushima & Miyake, 1982; LeCun et al., 1998; Riesenhuber &Poggio, 1999)。它也被认为是大脑使用的一种架构(DiCarlo et al., 2012)。
虽然我们使用局部接受域,但它们不是卷积的:参数不会在图像中的不同位置共享。这是我们的方法和以前的工作(LeCun et al., 1998;Jarrett et al., 2009;Lee,2009)。除了在生物学上更合理之外,未共享权重还允许学习更多的不变性,而不是平移不变性(Le et al., 2010)。
就规模而言,我们的网络可能是迄今为止已知的最大的网络之一。它有10亿个可训练参数,这比文献中报道的其他大型网络要大一个数量级,例如(Ciresan et al., 2010;Sermanet,(LeCun, 2011),大约有1000万个参数。值得注意的是,与人类视觉皮层相比,我们的网络仍然很小,人类视觉皮层的神经元和突触数量是人类的106倍(Pakkenberg et al., 2003)。
3.3. Learning and Optimization
Learning:在学习过程中,将第二子层的参数(H)固定为统一的权值,而使用第一子层的编码权值W1和解码权值W2进行调整,优化问题为
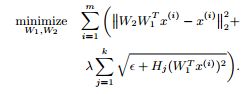
这里,λ是一个权衡参数之间的稀疏重建;m,k分别为一层中实例数和池单元数;Hj是第j个池单元的权向量。在我们的实验中,我们设置λ= 0.1。
该优化问题也称为重构地形独立分量分析(Hyv¨arinen et al., 2009; Le et al., 2011a)。目标中的第一项确保表示对数据的重要信息进行编码,即它们可以重建输入数据;而第二项则鼓励使用功能池将类似的功能组合在一起,以实现不变性。
Optimization:我们的模型中所有的参数都是联合训练的,目标是三层目标的总和。
为了训练模型,我们通过将局部权值W1、W2和H分配给不同的机器来实现模型的并行性。模型的一个实例将神经元划分为多个分区,并在169台机器(其中每台机器有16个CPU核心)上分配权重。一组共同组成模型单一副本的机器称为\模型副本。”我们已经建立了一个软件框架称为DistBelief管理所有必要的模型副本内不同机器之间的通信,这样用户的框架仅仅需要编写所需的向上和向下计算功能的神经元模型,而不需要处理跨机器的底层通信数据。
通过使用核心模型的多个副本实现异步SGD,我们进一步扩展了培训。对于这里描述的实验,我们将训练分为5个部分,并在每个部分上运行模型的副本。模型通过一组集中的\parameter服务器进行更新通信,“这些服务器将模型的所有参数的当前状态保存在一组分区服务器中(我们使用256个parameter server分区来训练本文描述的模型)。在最简单的实现中,在处理每个小批处理之前模型副本请求中央参数服务器提供其模型参数的更新副本。然后,它处理一个小批处理来计算一个参数梯度,并将参数梯度发送到适当的参数服务器,然后将每个梯度应用于模型参数的当前值。我们可以减少通信开销,每个模型复制请求更新参数P每一个步骤,通过发送更新后的梯度值参数服务器每G步骤(G可能不等于P)。我们的DistBelief软件框架自动管理分区之间的参数和梯度转移模型和参数服务器,释放层功能的实现者必须处理这些问题。
与标准(同步)SGD相比,异步SGD对故障和慢度具有更强的鲁棒性。具体来说,对于同步SGD,如果其中一台机器速度较慢,整个训练过程就会延迟;而对于异步SGD,如果一台机器很慢,那么只有一个SGD副本被延迟,而其余的优化仍然可以继续。
在我们的训练中,在SGD的每一步,梯度都是在100个样本的小批量上计算的。我们在一个拥有1000台机器的集群上对网络进行了为期三天的培训。有关优化实现的更多细节,请参见附录B、C和D。
4. Experiments on Faces
在这一部分中,我们描述了我们对人脸识别中学习表示的分析(\the face detector"),并给出了理解人脸检测器不变性的控制实验。下一节将介绍其他概念的结果。
4.1. Test set
该测试集由来自两个数据集的37,000张图像组成:野生数据集中的标记人脸(Huang et al., 2007)和ImageNet数据集(Deng et al., 2009)。在野外从未对齐的标记人脸中随机抽取13026张人脸,其余是从ImageNet中随机抽取的干扰物。这些图像被调整大小,以适应顶部神经元的可见区域。附录A中显示了一些示例图像。
4.2. Experimental protocols
训练后,我们使用这个测试集来测量每个神经元在区分人脸和干扰物时的表现。对于每个神经元,我们找到它的最大和最小激活值,然后平均选择20个中间间隔的阈值。所报道的分类精度是20个阈值中最好的。
4.3. Recognition
令人惊讶的是,网络中最好的神经元在识别人脸方面表现得非常好,尽管在训练过程中没有给出监控信号。网络中最好的神经元对人脸的检测准确率达到81.7%。测试集中有13026张脸,所以所有的猜测都是阴性,只得到64.8%。单层网络中最好的神经元只能达到71%的准确率,而从训练集中随机抽取的100,000个滤波器中选出的最佳线性滤波器只能达到74%。
为了理解它们的贡献,我们删除了局部对比归一化子层,并对网络进行了再训练。结果表明,最佳神经元的精度下降到78.5%。这与先前显示局部对比正常化的重要性的研究一致(Jarrett et al., 2009)。我们在图2中可视化了人脸图像和随机图像的激活值直方图。
![(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning_第2张图片](http://img.e-com-net.com/image/info8/077e262639ac441bb123b0dfebd14368.jpg)
我们可以看到,即使只有未标记的数据,神经元也能学会区分人脸和随机干扰物。具体来说,当我们把一张脸作为输入图像时,神经元的输出值往往大于阈值0。相反,如果我们将随机图像作为输入图像,神经元的输出值往往小于0。
4.4. Visualization
在本节中,我们将介绍两种可视化技术来验证神经元的最佳刺激是否确实是一张脸。第一种方法是将测试集中反应性最强的刺激可视化,由于测试集较大,该方法能够可靠地检测到被测神经元的最优刺激。第二种方法是通过数值优化来寻找最优的刺激(Berkes &Wiskott, 2005;Erhan等,2009;Le et al., 2010)。特别地,通过求解,得到了使被测神经元输出f最大的正态有界输入x
![]()
在这里,f (x;W;H)为给定学习参数W的被测神经元的输出;在我们的实验中,这个约束优化问题是通过线搜索的投影梯度下降来解决的。这些可视化方法各有优缺点。例如,视觉化最具反应性的刺激可能会影响对噪音的适应。另一方面,数值优化方法容易受到局部极小值的影响。结果如图3所示,证实了被测神经元确实学习了人脸的概念。
![(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning_第3张图片](http://img.e-com-net.com/image/info8/e49403b951b84997a84520fa3d4ac7f8.jpg)
4.5. Invariance properties
我们想评估人脸检测器对常见对象转换的鲁棒性,例如平移、缩放和面外旋转。首先,我们选择了一组10张人脸图像,对它们进行变形,例如缩放和平移。对于outof-plane的旋转,我们使用了10张在3D (\out- plane”)中旋转的人脸图像作为测试集。为了检验神经元的鲁棒性,我们绘制了它在小测试集上的平均响应,包括尺度变化、3D旋转(图4)和平移(图5)。
![(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning_第4张图片](http://img.e-com-net.com/image/info8/cfb415a1e9314fe088d2836c793500ad.jpg)
结果表明,该神经元具有较强的抗平面外旋转和缩放等复杂的、难以处理的invariances。
Control experiments on dataset without faces:如上所述,在对随机干扰物进行人脸分类时,最佳神经元的准确率达到81.7%。如果我们从训练集中删除所有有人脸的图像呢?
我们在OpenCV中运行人脸检测器,去除至少包含一张人脸的训练图像,进行了控制实验。最佳神经元的识别精度下降到72.5%,与4.3节报道的简单线性滤波器一样低。
5. Cat and human body detectors
我们已经实现了对人脸敏感的神经元,我们想了解网络是否也能够检测到其他高级概念。例如,猫和身体部位在YouTube上很常见。网络也学习了这些概念吗?
为了回答这个问题并量化网络对这些概念的选择性,我们构建了两个数据集,一个用于根据随机背景对人体进行分类,另一个用于根据其他随机干扰物对猫的脸进行分类。为了便于解释,这些数据集具有与人脸数据集相同的正负比。
从数据集de中收集猫的人脸图像(Zhang et al., 2008)。在这个数据集中,有10,000张正面图像和18,409张负面图像(因此正负比与人脸的情况相似)。负像是从ImageNet数据集中随机选取的。我们的人体数据集中的消极和积极的例子是从基准数据集中随机抽样的(Keller et al., 2009)。在原始数据集中,每个示例都是一对立体黑白图像。但是为了简单起见,我们只保留左边的图像。总的来说,就像人类的脸一样,我们有13026个正面的例子和23974个负面的例子。
![(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning_第5张图片](http://img.e-com-net.com/image/info8/7f5fa61b23b04aecb8ba7dfb481b1b4f.jpg)
然后,我们遵循与之前相同的实验协议。结果如图6所示,证实了该网络不仅学习人脸的概念,还学习了猫脸和人体的概念。我们的高水平探测器在识别率上也超过了标准基线,对猫和人体的识别率分别达到74.8%和76.7%。相比之下,最好的线性滤波器(从训练集中采样)只能分别达到67.2%和68.1%。在表1中,我们总结了以前所有比较最佳神经元与其他基线(如线性滤波器和随机猜测)的数值结果。为了了解训练的效果,我们还测量了同一网络中最佳神经元在随机初始化时的表现。我们还将该方法与其他一些算法进行了比较,如深层自动编码器(Hinton &Salakhutdinov, 2006;Bengio等,2007)和Kmeans (Coates等,2011)。这些基线的结果报告在表1的底部。
6. Object recognition with ImageNet
![(18)[ICML12] Building High-level Features Using Large Scale Unsupervised Learning_第6张图片](http://img.e-com-net.com/image/info8/ecbdf935b65345ddac3552ffb74a9195.jpg)
7. Conclusion
在这项工作中,我们使用未标记的数据模拟了高级特定于类的神经元。我们将最近开发的算法的思想结合起来,从未标记的数据中学习不变性,从而实现了这一点。由于模型并行性和异步SGD,我们的实现可以扩展到拥有数千台机器的集群。
我们的研究表明,利用完全未标记的数据,训练神经元对高级概念具有选择性是可能的。在我们的实验中,我们通过在YouTube视频的随机帧上训练,获得了具有人脸、人体和猫脸探测器功能的神经元。
这些神经元自然地捕捉复杂的不变性,如面外不变性和尺度不变性。学习的表现形式也适用于有区别的任务。从这些表征入手,我们在ImageNet上对20000个类别的目标识别准确率达到了15.8%,相对于最先进的水平有了70%的飞跃。