OpenMP(Open Multi-Processing)
一 什么是OpenMP?
在并行化计算中,远程内存访问的方式主要有三种shared memory, one-sided communication和Mesaage Passing。OpenMP就是基于shared memory的高度抽象的并行化计算API,具有良好移植性和扩展性。它是一种显性的(explict)的编程模式,给予了用户对完全控制并行化的能力。
二 OpenMP执行模式
OpenMP会顺序执行程序知道遇到了并行指令(parallel directive),当前线程会分出支干来并行化执行parallel directive的内容。所以,用户主要通过合理的插入编译指令(compiler directives)去控制各个资源的分分合合,决定什么时候并行concurency,什么时候同步(synchronization)。这种模式就是典型的Fork-join model

Fork:主线程创建多线程任务,eg,这里0就是主线程,一些特殊的指令仅仅会影响主线程。
Join:等待对应的Fork创建的主线程任务结束,同步后回到主线程上(或者说只保留主线程)

特别的,Fork-join model是可以嵌套的。并且嵌套的的fork join是独立于现有的线程的。
嵌套的例子:

三 编程模版
如何加载omp?
| Compiler / Platform |
Compiler |
Flag |
| Intel |
icc |
-openmp |
| icpc |
||
| ifort |
||
| PGI |
pgcc |
-mp |
| pgCC |
||
| pgf77 |
||
| pgf90 |
||
| GNU |
gcc |
-fopenmp |
| g++ |
||
| g77 |
||
| gfortran |
Serial code . . .
#parallel directive {
- Parallel section executed by all threads .
- Other OpenMP directives .
- Run-time Library calls .
- All threads join master thread .
}
Resume Serial code . . .
四 定制线程行为
在编程模版中,还有一个Run-time Library calls,这是干嘛的呢?
用来定制线程,查询当前block下的状态:
- Setting and querying the number of threads
- Setting and querying the dynamic threads feature
- Querying if in a parallel region, and at what level
- Setting, initializing and terminating locks and nested locks
- Setting and querying nested parallelism
除此之外,用户还可以通过设置全局变量Environment Variables去定制:
-
Setting the number of threads
-
Specifying how loop iterations are divided
-
Binding threads to processors
-
Setting thread stack size
-
Setting thread wait policy
具体的设定方式:
| csh/tcsh |
setenv OMP_NUM_THREADS 8 |
| sh/bash |
export OMP_NUM_THREADS=8 |
五 Compiler Directives
理解了运行原理后,剩下的只需要在需要的地方插入Compiler Directives即可。
大概的Compiler Directives可以做:
- Spawning a parallel region
- Dividing blocks of code among threads 将一个或几个分组执行相同任务
- Distributing loop iterations between threads 拆分循环到几个线程
- Serializing sections of code 序列化
- Synchronization of work among threads 设同步点
C / C++ Directives Format:
#pragma omp parallel [clause ...] newline structured_block
#pragmaomp Required for all OpenMPC/C++directives.
directive-name A valid OpenMP directive. Must appear after the pragma and before any clauses.
[clause, ...] Optional. Clauses can be in any order, and repeated as necessary unless otherwise restricted.
Newline Required. Precedes the structured block which is enclosed by this directive
1)working sharing
当主线程遇到compiler directives,创建线程去执行block中的code。working sharing会隐形的为线程创建一个barrier(同步点)。working sharing可以分为:
- DO / for - shares iterations of a loop across the team. Represents a type of "data parallelism". MISD 多个线程执行相同代码在不同的数据
- SECTIONS - breaks work into separate, discrete sections. Each section is executed by a thread. Can be used to implement a type of "functional parallelism". 每个线程可以执行不同的程序在不同的数据上
- SINGLE - serializes a section of code
DO/for directive:
Format:
#pragma omp for [clause ...] schedule (schedule_type , [chunk]) newline
......
for_loop
DO/for directive必须要嵌套在定义好的parall block内部,否则不会并行化运行,只会顺序执行。
Schedule: 描述如何切分循环,Describes how iterations of the loop are divided among the threads in the team. schedule_type:
- STATIC: loop iterations divided in pieces of size chunk and statically assigned to threads,一般用于workload比较平均的case中, 比如 parallel k-means
- DYNAMIC: loop iterations divided in pieces of size chunk and dynamically scheduled,用在不平均的情况,比如Parallel Graph algorithms
- RUNTIME: scheduling decision is deferred until runtime
Other Clauses for Do/for directive:
- NO WAIT: threads do not synchronize at the end of the loop 不在for dirctive中同步,但依然会在嵌套的parallel blocking同步
- ORDERED: the iterations (of a particular statement within loop above which ordered directive used) of the loop executed in the order they would be in a serial program,后面有具体描述。
Restrictions in Do/for directive:
- 必须限定循环次数,while loop就无法运行。
- Chunk size对于每个线程来说需要是一样的。
- It is illegal to branch outside the loop
Example:
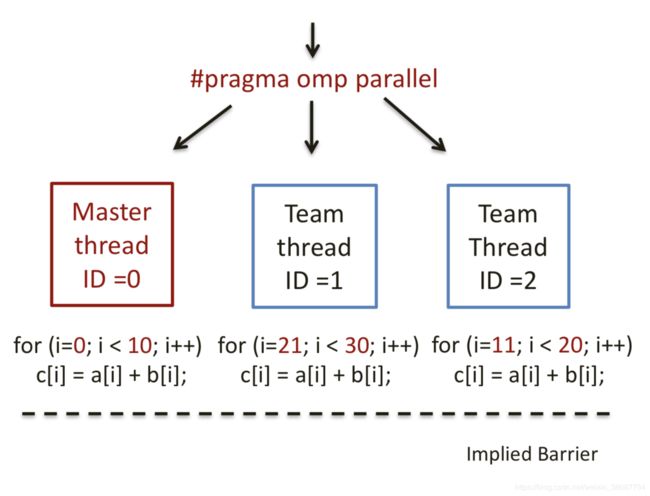
set_num_threads(3);
#pragma omp parallel [clause...]
{
#pragma omp for [chunk = 10...]
for (i=0; i < 30; i++) c[i] = a[i] + b[i];
}
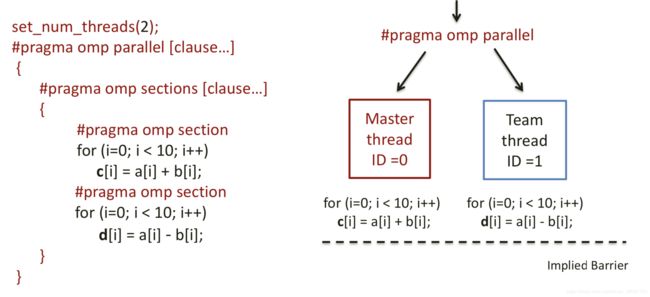
SECTIONS directive:
Format
#pragma sections [clause ...] newline {
#pragma omp section newline
structured_block
#pragma omp section newline
structured_block
}每个线程可以执行不同的内容,一个线程可以执行不止一个section。
SINGLE directive:
Format:
#pragma omp single [clause ...] newline
structured_blocksingle的部分只会被一个线程执行,而且其他线程必须要等待single部分执行完才能继续,除非clause设定了nowait。

MASTER Directive
顾名思义,只会被主线程执行的部分。
CRITICAL Directive
规定一个时间内只能有一个线程执行该部分。
ATOMIC Directive
实现EW(exclusive write)的操作,memory location只能被原子的更新。
BARRIER Directive
设定同步点。等待所有线程一起到达。

ORDERED Directive
一个循环被分成多份执行,每一个线程必须等待前一个线程执行完毕后才能执行。

Data Scope Attribute Clauses:
- • PRIVATE 对于block中thread,val是private的
- • FIRSTPRIVATE 将firstprivate中声明的变量,从初始化的定义中拷贝到每一份线程的私有变量中(覆盖)
- • LASTPRIVATE: 将LASTPRIVATE中声明的变量,从前一次loop 中执行完的结果复制到下一个中。
- • SHARED
- • DEFAULT 定义一个默认的环境,可以适用所有设置为default的block
- • REDUCTION 将每个线程的私有变量进行reduction操作,然后保存到shared variable中
FirstPrivate vs LastPrivate:
最主要的区别,前一个从定义中来,后一个从中间过程的结果中来。
Firstprivate Example:

LastPrivate:

关于在Eclipse中添加链接库,因为链接库是-fopenmp而不是-l openmp,所以不能直接在link library中添加openmp。需要在c++ builder和 C++ link中分别添加。