操作系统——Linux进程创建及同步实验
实验题目要求:
1.编写一段程序,使用系统调用fork( )创建两个子进程。当此程序运行时,在系统中有一个父进程和两个子进程活动。让每一个进程输出不同的内容。试观察记录屏幕上的显示结果,并分析原因。
2.修改上述程序,每一个进程循环显示一句话。子进程显示"daughter …"及"son ……",父进程显示"parent ……",观察结果,分析原因。
3.再调用exec( )用新的程序替换该子进程的内容 ,并利用wait( )来控制进程执行顺序。调用Exit()使子进程结束。
4.利用linux的信号量机制实现生产者-消费者问题。(基于进程)
实验1:
先用在终端中输入 vim test01.c 编辑程序(在vim中的编译操作可参见我的前一篇博客: Linux系统添加系统调用 ,其中有具体操作)
我最终的test01.c的程序如下图所示:
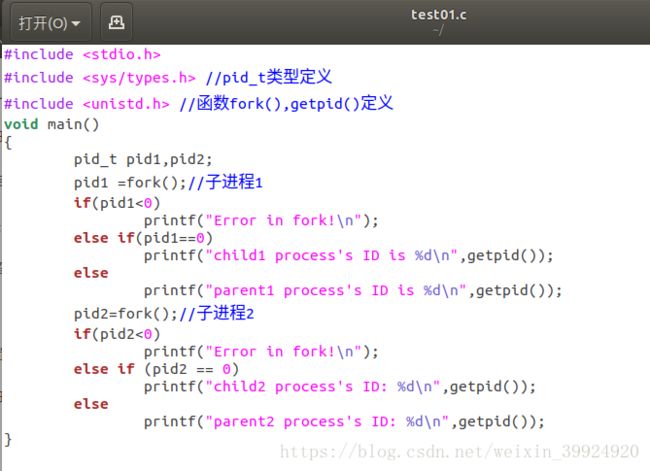
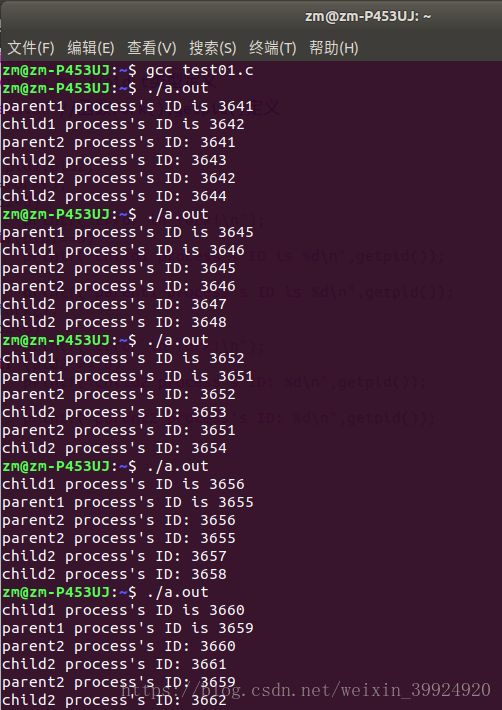
程序结果如下:(我多输出了几次编译后的a.out程序,仔细观察可以发现每次执行结果中进程的执行顺序是不定的,且进程对应的进程标识符 即程序中输出的ID号 也不相同)
分析:
(1)首先了解一下fork()函数:
一个现有进程可以调用fork函数创建一个新进程。该函数定义如下:
#include
pid_t fork(void);// 返回:若成功则在子进程中返回0,在父进程中返回子进程ID,若出错则返回-1 fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
因此,可以通过返回值来判断当前是父进程还是子进程。
(2)其次,关于pid的值在父子进程中不同的原因,其实就相当于链表,进程形成了链表,父进程的pid(p 意味着point)指向子进程的进程ID,因为子进程没有子进程,所以它的pid为0。
(3)这次实验中每次输出结果中的顺序不一样的原因:
一般来说,在fork之后的父进程先执行还是子进程先执行是不确定的,取决于内核的调度算法,相互之间没有任何时序上的关系。所以在没有加入进程同步机制的代码的情况下,父进程与子进程的输出内容会叠加在一起,由此导致每次运行的结果之后出现了不一样的运行结果。
具体fork函数的创建过程及解析可参看:
fork()创建子进程步骤、函数用法及常见考点(内附fork()过程图)
实验2:
因为是在实验1的基础上进行的,所以,操作步骤与实验1差不多。
我的实验2的程序如下:
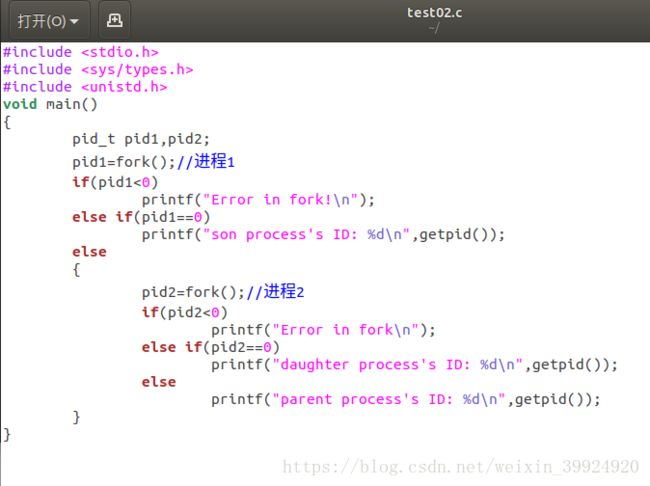
程序执行结果:
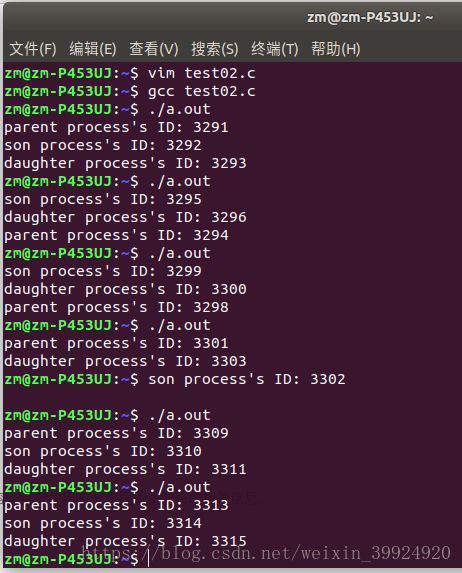
多次输出编译后的a.out程序,同样可以看到执行的顺序也是不定的,且进程的ID号也不相同。
分析:
我认为我的实验2的程序中进程的产生过程如下图所示:(排列不讲顺序)
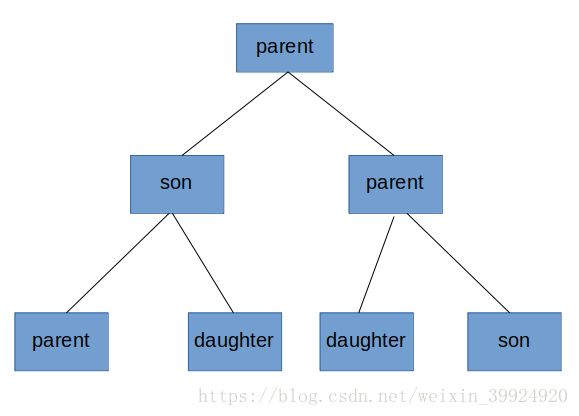
所以,在最终的输出结果中parent,daughter,son进程的顺序不一定。
而由于函数printf( )在输出字符串时不会被中断,所以,字符串内部字符顺序输出不变。但由于进程并发执行的调度顺序和父子进程抢占处理机问题,输出字符串的顺序和先后随着执行的不同而发生变化。
实验3:
(1)exec函数说明:
fork函数是用于创建一个子进程,该子进程几乎是父进程的副本,而有时我们希望子进程去执行另外的程序,exec函数族就提供了一个在进程中启动另一个程序执行的方法。它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新程序的内容替换了。另外,这里的可执行文件既可以是二进制文件,也可以是Linux下任何可执行脚本文件。
(2)在Linux中使用exec函数族主要有以下两种情况:
a. 当进程认为自己不能再为系统和用户做出任何贡献时,就可以调用任何exec 函数族让自己重生。
b. 如果一个进程想执行另一个程序,那么它就可以调用fork函数新建一个进程,然后调用任何一个exec函数使子进程重生。
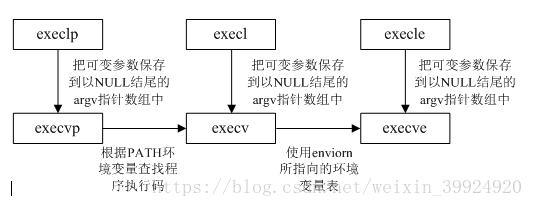
(3)exec函数族语法
实际上,在Linux中并没有exec函数,而是有6个以exec开头的函数族,下表列举了exec函数族的6个成员函数的语法。
所需头文件: #include
函数说明: 执行文件
函数原型:
int execl(const char *path, const char *arg, ...)
int execv(const char *path, char *const argv[])
int execle(const char *path, const char *arg, ..., char *const envp[])
int execve(const char *path, char *const argv[], char *const envp[])
int execlp(const char *file, const char *arg, ...)
int execvp(const char *file, char *const argv[])其中,这6个函数之间的调用关系如下图所示:
(4)exec()和fork()联合使用
系统调用exec()和fork()联合使用能为程序开发提供有力支持。用fork( )建立子进程,然后在子进程中使用exec(),这样就实现了父
进程与一个与它完全不同子进程的并发执行。
一般,wait、exec联合使用的模型为:
int status;
............
if (fork( )= =0)
{
...........;
execl(...);
...........;
}
wait(&status);等待子进程运行结束。如果子进程没有完成,父进程一直等待。wait()将调用进程挂起,直至其子进程因暂停或终止而发来软件
中断信号为止。如果在wait()前已有子进程暂停或终止,则调用进程做适当处理后便返回。
系统调用格式:int wait(status)
int *status;其中,status是用户空间的地址。它的低8位反应子进程状态,为0表示子进程正常结束,非0则表示出现了各种各样的问题;高8
位则带回了exit()的返回值。exit()返回值由系统给出。
核心对wait()作以下处理:
- 首先查找调用进程是否有子进程,若无,则返回出错码;
- 若找到一处于“僵死状态”的子进程,则将子进程的执行时间加到父进程的执行时间上,并释放子进程的进程表项;
- 若未找到处于“僵死状态”的子进程,则调用进程便在可被中断的优先级上睡眠,等待其子进程发来软中断信号时被唤醒。
(6)exit()
终止进程的执行。
系统调用格式:
void exit(status)
int status;其中,status是返回给父进程的一个整数,以备查考。
为了及时回收进程所占用的资源并减少父进程的干预,UNIX/LINUX利用exit( )来实现进程的自我终止,通常父进程在创建子进程时,应在进程的末尾安排一条exit( ),使子进程自我终止。exit(0)表示进程正常终止,exit(1)表示进程运行有错,异常终止。
了解相关只是之后开始写程序,我的最终程序如下:
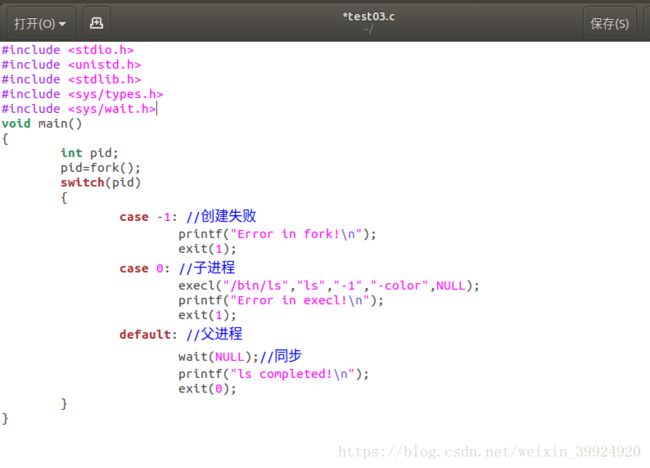
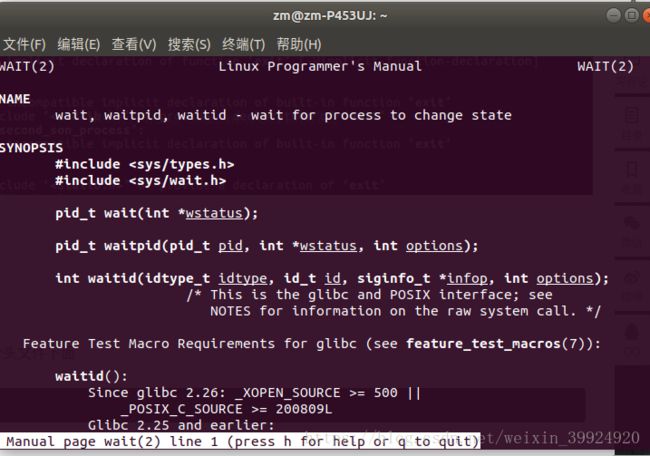
在最终这版之前,我之前少写了wait()函数的头文件,然后编译之后出现了警告,一开始有点慌,以为是导致编译没成功,所以上网搜了下警告里的那个很长的句子(-Wimplicit-function-declaration),然后网上的解决办法是在终端中输入man ×××(其中×××表示警告中上面这句话下面出现的东西),找到×××的头文件之后,在程序中加入即可。然后我在终端中输入man wait ,找到头文件为
(后来,写实验4的时候才意识到警告不影响程序呢运行,可能是太久没有写代码了,连这个都忘记了)
程序运行结果以及编译中出错的地方都如下图所示:
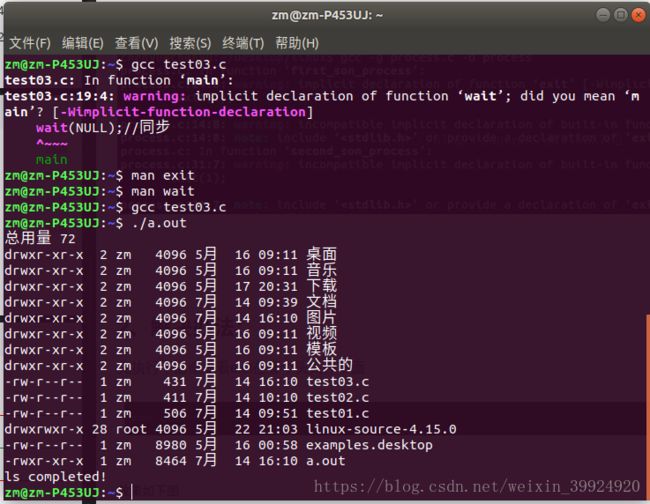
我的程序执行的功能是执行命令ls -l -color ,(按倒序)列出当前目录下所有文件和子目录。
程序在调用fork( )建立一个子进程后,马上调用wait(),使父进程在子进程结束之前,一直处于睡眠状态。子进程用exec()装入命令ls ,exec()后,子进程的代码被ls的代码取代,这时子进程的PC指向ls的第1条语句,开始执行ls的命令代码。其中,wait( )给我们提供了一种实现进程同步的简单方法
关于fork()函数和exec()函数的详解参考:进程控制
实验4:
(1)生产者-消费者问题:
就是生产者和消费者共用一个缓冲区,生产者生产项目放进缓冲区,而消费者则从缓冲区中消费项目。当缓冲区满了的时候,生产者不能对其生产;而当缓冲区为空的时候,消费者不能作消费。
所以生产者与消费者模型是复合321原则:三种关系,两种角色,一种交易场所。
三种关系:
生产者与消费者:互斥,同步
生产者与生产者:互斥
消费者与消费者:互斥
(2)需要的信号量(3个):
第一个信号量用于限制生产者必须在缓冲区不满时才能生产,是同步信号量;
第二个信号量用于限制消费者必须在缓冲区有产品时才消费,是同步信号量;
(3)关于信号量的函数:
初始化信号量 int sem_init (sem_t *sem, int pshared, unsigned int value)
第一个参数是信号量;第二个参数pshared设为0,意思是信号量用于同一进程间同步;第三个参数value是计数器的初始值。
P操作 int sem_wait (sem_t *sem)
V操作 int sem_post (sem_t *sem)
删除信号量 int sem_destory (sem_t *sem)
代码:
#include
#include
#include
#include
#include
#include
#define N 5 // 消费者或者生产者的数目
#define M 10 // 缓冲数目
int in = 0; // 生产者放置产品的位置
int out = 0; // 消费者取产品的位置
int buff[M] = { 0 }; // 缓冲初始化为0,开始时没有产品
sem_t empty_sem; // 同步信号量,当满了时阻止生产者放产品
sem_t full_sem; // 同步信号量,当没产品时阻止消费者消费
pthread_mutex_t mutex; // 互斥信号量,一次只有一个线程访问缓冲
int product_id = 0; //生产者id
int prochase_id = 0; //消费者id
void Handlesignal(int signo)//信号处理函数
{
printf("程序退出\n",signo);
exit(0);
}
void print() //打印缓冲情况
{
int i;
printf("缓冲区队列为");
for(i = 0; i < M; i++)
printf("%d", buff[i]);
printf("\n");
}
void *product() //生产者方法
{
int id = ++product_id;
while(1)//重复进行
{
sleep(2);//用sleep的数量可以调节生产和消费的速度,便于观察
sem_wait(&empty_sem);
pthread_mutex_lock(&mutex);
in= in % M;
printf("生产者%d 在缓冲区中存放第%d个资源\t",id, in);
buff[in]= 1;
print();//转行,控制输入格式
in++;
pthread_mutex_unlock(&mutex);
sem_post(&full_sem);
}
}
void *prochase() //消费者方法
{
int id = ++prochase_id;
while(1) //重复进行
{
sleep(4);//用sleep的数量可以调节生产和消费的速度,便于观察
sem_wait(&full_sem);
pthread_mutex_lock(&mutex);
out= out % M;
printf("消费者%d 从缓冲去中取走第%d个资源\t",id, out);
buff[out]= 0;
print();//转行,控制输入格式
++out;
pthread_mutex_unlock(&mutex);
sem_post(&empty_sem);
}
}
int main()
{
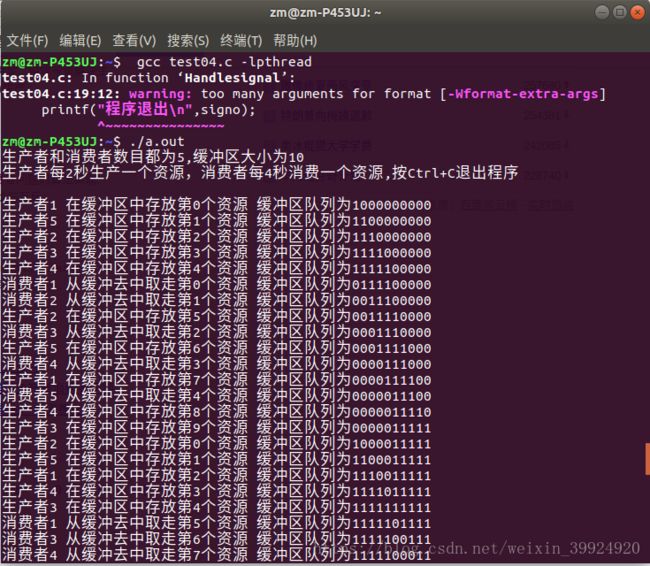
printf("生产者和消费者数目都为5,缓冲区大小为10\n");
printf("生产者每2秒生产一个资源,消费者每4秒消费一个资源,按Ctrl+C退出程序\n\n");
pthread_t id1[N];
pthread_t id2[N];
int i;
int ret[N];
if(signal(SIGINT,Handlesignal)==SIG_ERR)//按ctrl+C产生SIGINT信号,进程结束
printf("信号输入出错\n");
// 初始化同步信号量
int ini1 = sem_init(&empty_sem, 0, M);//缓冲区同步
int ini2 = sem_init(&full_sem, 0, 0);//线程运行同步
if(ini1 && ini2 != 0)
{
printf("同步信号量初始化失败!\n");
exit(1);
}
int ini3 = pthread_mutex_init(&mutex, NULL);//初始化互斥信号量
if(ini3 != 0)
{
printf("线程同步初始化失败!\n");
exit(1);
}
for(i = 0; i < N; i++) // 创建N个生产者线程
{
ret[i]= pthread_create(&id1[i], NULL, product, (void *) (&i));
if(ret[i] != 0)
{
printf("生产者%d 线程创建失败!\n", i);
exit(1);
}
}
for(i = 0; i < N; i++) //创建N个消费者线程
{
ret[i]= pthread_create(&id2[i], NULL, prochase, NULL);
if(ret[i] != 0)
{
printf("消费者%d 线程创建失败!\n", i);
exit(1);
}
}
for(i = 0; i < N; i++)//等待线程销毁
{
pthread_join(id1[i], NULL);
pthread_join(id2[i],NULL);
}
exit(0);
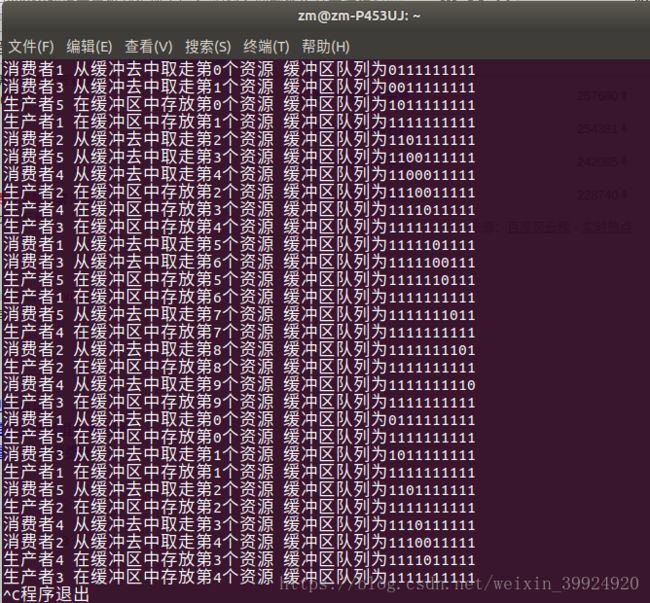
} 运行结果:
参考:
OS: 生产者消费者问题(多进程+共享内存+信号量)
Linux下利用信号量函数和共享内存函数和C语言实现生产者消费者问题
总结:
此次实验,相较与上次实验而言,我觉得更难了一些,可能是这次用到了很多之前没怎么接触过的函数,不过还是很开心能接触到这些函数,并对这些函数进行学习和实际操作。