用NLTK创建NLP自然语言处理聊天机器人(一)
前面我们看到用chatterbot创建聊天机器人有两点弊端:
1.反应速度太慢,会遍历整个语言记忆
2.对闲聊式对话正确率在40%左右,但对知识性和应用性对话的正确率为0
注:只有python3才支持中文
后来我们看用aiml搭建机器人也有两个重大难题:
1.不支持中文,需要修改aiml内核
2.版本不兼容,只能在python2上跑
因此我思考用新的开源python库来搭建自己的机器人后端
今天先用NLTK试试:
配环境:
pip install nltk
然后终端输入检验是否安装成功:
python
import nltk
这样表示安装成功:
然后要用nltk下载器下载语言包:
导入NLTK并运行nltk.download().这将打开NLTK下载器,您可以从中选择要下载的语料库和模型。您也可以一次下载所有包。
在终端输入:
python
import nltk
nltk.download()
就会自动弹出下载器界面,然后下载全部即可:

最后下载完毕是这样的:
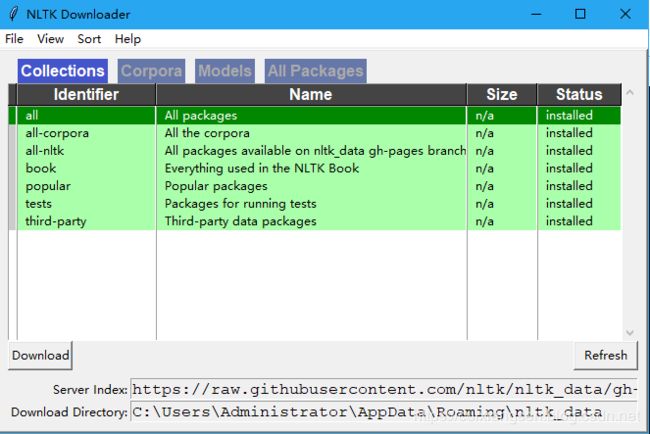
原理部分(摘抄,可直接跳过):
使用NLTK进行文本预处理
文本数据的主要问题是它都是文本格式(字符串)。但是,机器学习算法需要某种数值特征向量才能执行任务。因此,在我们开始任何NLP项目之前,我们需要使用预处理(pre-processing)。基本文字pre-processing包括:
将整个文本转换为大写或小写。因此,算法不会将不同情况下的相同单词视为不同。
符号化(Tokenization):Token化只是用于描述将普通文本字符串转换为Token列表(即我们实际需要的单词)的过程的术语。 Sentence tokenizer可用于查找句子列表,Word tokenizer可用于查找字符串中的单词列表。
NLTK数据包包括用于英语语境的预训练的Punkt标记器。
删除噪声即所有不符合标准数字或字母的东西。
删除停用词(Stop Words)。有时,一些非常常见的单词在帮助选择符合用户需求的文档时似乎没什么价值,完全从词汇表中排除。这些话被称为停用词。
词干:词干是将变形(或有时衍生)的词减少到它们的词干,词根或词形的过程 - 通常是书面文字形式。例如,如果我们对以下次做词干化处理的话:“Stems”,“Stemming”,“Stemmed”,“and Stemtization”,结果将是单字“stem”。
词形还原:词干化的一个轻微变体是词形还原。二者主要区别在于,词干通常可以创建不存在的词,而词词形还原得到的是实际词。词形还原的示例是“run”是诸如“running”或“ran”之类的单词的基本形式,或者单词“better”和“good”有相同的词形,因此它们被认为是相同的。
词袋(Bag of Words)
在初始预处理阶段之后,我们需要将文本转换为有意义的数字向量(或数组)。 bag-of-words是文本的表示,用于描述文档中单词的出现。它涉及两件事:
•已知单词的词汇表。
•衡量已知单词的存在。
为什么称它为词袋(Bag-Of-Words)?这是因为关于文档中单词的顺序或结构的任何信息都被丢弃,而模型只关注已知单词是否出现在文档中,而不是出现在文档中的位置。
Bag of Words背后的直觉是,如果文档具有相似的内容词,则它们是相似的。
例如,如果我们的字典包含单词{Learning,is,the,not,great},并且我们想要对文本“Learning is great”进行矢量化,那么我们将得到以下向量:(1,1,0,0,1)。
TF-IDF方法
Bag of Words方法的一个问题是高频率的单词在文档中开始占主导地位(例如,得分较高),但可能包含的信息量有限。此外,与较短的文档相比,词袋使更长的文档权重更高。
一种方法是通过它们在所有文档中出现的频率来重新调整单词的频率,使得在所有文档中频繁出现的频繁单词(如“the”)的分数受到惩罚。这种评分方法被称为词频率逆文档频率(Term Frequency-Inverse Document Frequency), 即TF-IDF,其中:
单词频率:是当前文档中单词频率的得分。
TF = (Number of times term t appears in a document)/(Number of terms in the document)
逆文档频率:这是该单词在文档中的罕见程度得分。
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.
Tf-idf权重是经常用于信息检索和文本挖掘的权重。此权重是用于评估单词对集合或语料库中的文档的重要程度的统计度量,
例:
考虑一个包含100个单词的文档,其中“phone”一词出现5次。
然后,phone的单词频率(即,tf)是(5/100)= 0.05。现在,假设我们有1000万个文档,其中一千个文字出现“phone”。然后,逆文档频率(即IDF)被计算为log(10,000,000 /1,000)= 4.因此,Tf-IDF权重是这些量的乘积:0.05 * 4 = 0.20。
Tf-IDF可以使用scikit Learn实现:
从sklearn.feature_extraction.text导入TfidfVectorizer
余弦相似度
TF-IDF是应用于文本的变换,以在向量空间中获得两个实数向量。然后我们可以获得余弦:通过获取它们的点积并将其除以它们的标准化的乘积来表示任何一对矢量的相似性。使用以下公式,我们可以找出任何两个文件d1和d2之间的相似性。
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
其中d1,d2是两个非零向量。
干货部分
文本预处理,分词:
# -*- coding: UTF-8 -*-
print('nltk入门实践1,文本预处理,分词:')
import nltk
text = 'I will make the python more than your understand. I really love it'
#第一项:
#将文本拆分成句子列表
sens = nltk.sent_tokenize(text)
print(sens)
#第二项:
#将句子进行分词,nltk的分词是句子级的,因此要先分句,再逐句分词,否则效果会很差.
words = []
for sent in sens:
words.append(nltk.word_tokenize(sent))
print(words)
结果:

最大硬伤,不支持中文分词,因为原生语料库都是英文的
因此看到另一位老哥的博客用的很好的一个方法:
用结巴库,jieba是优秀的中文分词第三方库
终端输入安装结巴:
pip install jieba

然后用结巴分词:
import jieba
wordlist = jieba.lcut("首先介绍一下jieba库是啥玩意,jieba库是python的中文分词工具,可以将句子精确的分开,对文本进行分析,统计词频、做词云图、构建对象......巴拉巴拉~。最重要的是对我毕业作品的成败有着极大的作用。当然本文仅限对于python初学者,大神一般是不会纠结安装这种小问题的撒!")
print(wordlist)

但这里面有个不好的地方就是,我们分词有很多标点符号在里边,此时我们可以使用停止词来去掉不需要词,这里我们采用简单粗暴的一种方式来处理我们只保留中文。请参考下面代码:
import jieba
import re
word = "首先介绍一下jieba库是啥玩意,jieba库是python的中文分词工具,可以将句子精确的分开,对文本进行分析,统计词频、做词云图、构建对象......巴拉巴拉~。最重要的是对我毕业作品的成败有着极大的作用。当然本文仅限对于python初学者,大神一般是不会纠结安装这种小问题的撒!"
cleaned_data = ''.join(re.findall(r'[\u4e00-\u9fa5]', word))#先剔除句子中的标点符号
print(cleaned_data)
wordlist = jieba.lcut(cleaned_data)#再用结巴分词,就不会有标点符号了
print(wordlist)
运行结果非常理想

注:
用nltk可以用来处理任何符号语言。只是对其他语言来说,你需要有标注数据集,训练自己的分词器,词性标注器等等。后面我们会一点一点的展开
干货知识原理:
分词、命名实体识别和词性标注这三项技术如果达不到很高的水平,是难以建立起高性能的自然语言处理系统,也就难以实现高质量的聊天机器人。
分词是对句子进行拆解,分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记。
命名实体识别是NLP里的一项很基础的任务,就是指从文本中识别出命名性指称项,为关系抽取等任务做铺垫。狭义上,是识别出人命、地名和组织机构名这三类命名实体(时间、货币名称等构成规律明显的实体类型可以用正则表达式等方式识别)。当然,在特定的领域中,会相应地定义领域内的各种实体类型。

词性标注:词性是帮助计算机理解语言含义的关键
常说的词性包括:名、动、形、数、量、代、副、介、连、助、叹、拟声。但自然语言处理中要分辨的词性要更多更精细,比如:区别词、方位词、成语、习用语、机构团体、时间词等,多达100多种。
汉语词性标注最大的困难是“兼类”,也就是一个词在不同语境中有不同的词性,而且很难从形式上识别。
聊天机器人是怎么工作的?
大致上有两种类型的聊天机器人: 基于规则的和自学习的。
-
基于规则的:根据训练的规则哎回答问题。定义的规则可以非常简单,也可以非常复杂。机器人可以处理简单的查询,但不能处理复杂的查询。
-
自学习机器人:使用一些基于机器学习的方法,它比基于规则的机器人更有效率。这些机器人还可以有两种类型:基于检索或生成性
(一)基于检索的模型:聊天机器人使用一些启发式方法从预定义响应库中选择响应。Chatbot使用会话的消息和上下文从预定义的bot消息列表中选择最佳响应。上下文可以包括对话框树中的当前位置、会话中的所有先前消息、先前保存的变量(例如用户名)。选择响应的启发式方法可以通过多种不同的方式进行,从基于规则的if-否则条件逻辑到机器学习分类器。
(二)生成性机器人可以生成答案,而不是总是从一组答案中生成一个答案。这使得他们更聪明,因为他们从查询中逐字逐句地获取并生成答案。
最后根据今天写的先上一个简单的只是基于分词的机器人吧,没有学习能力,只能死扣语料库:
# -*- coding: utf-8 -*-
import jieba
import re
import nltk
import random
#输入输出数据可以从文件里读到内存,这里只是举一个静态例子
INPUT_DATA = ("你是","你是谁","名字","你好","介绍自己","你来自","如何称呼","name","hello","你谁","是谁","你的名字","你叫","你叫什么","你谁啊","你怎么称呼","称呼")
RESPONSES_DATA = ("你好呀,我叫小森","嘿,我是小森,很高兴认识你","hi,我叫小森,怎么称呼你呢","我的名字是小森,见到你很开心","我是小森机器人,开开心心每一天")
#返回消息方法
'''
def response_bot(word):
if word in INPUT_DATA:
flag = 1 #表示已经回复
return random.choice(RESPONSES_DATA)
'''
while True:
flag = 0
try:
sentence = input("请输入:")
#print("你说:"+sentence)
cleaned_data = ''.join(re.findall(r'[\u4e00-\u9fa5]', sentence))#先剔除句子中的标点符号
wordlist = jieba.lcut(cleaned_data)#再用结巴分词,就不会有标点符号了
for word in wordlist:
if word in INPUT_DATA:
flag = 1 #表示已经回复
response = random.choice(RESPONSES_DATA)
break
if sentence in INPUT_DATA:
flag = 1 #表示已经回复
response = random.choice(RESPONSES_DATA)
if flag == 1:
print(response)
else :
print("我还太年轻,理解不了你说的啥")
except(KeyboardInterrupt, EOFError, SystemExit):
break
执行效果如下:
