ChatterBot+第三方中文语料库实现在线聊天机器人
设计并实现一个在线聊天机器人案例
1、ChatterBot
ChatterBot是Python自带的基于机器学习的语音对话引擎,可以基于已知的对话库来产生回应。ChatterBot独特的语言设计可以使它可以通过训练来用任何一种语言进行对话。该项目的开源代码链接:https://github.com/gunthercox/ChatterBot
2、应用案例描述
ChatterBot包含的工具有助于简化训练聊天机器人实例的过程。ChatterBot的训练过程涉及将示例对话框加载到聊天机器人的数据库中。这可以创建或构建代表已知语句和响应集的图数据结构。当一个聊天机器人训练师被提供一个数据集时,它会在聊天机器人的知识图中创建必要的条目,以便正确表示语句输入和响应。
2.1 通过列表数据进行训练
chatterbot.trainers.ListTrainer(storage, **kwargs)
允许使用对话字符串列表来训练ChatBot。
对于训练过程,需要传递一个语句列表,其中每个语句的顺序基于其在给定对话中的位置。
例如,如果你使用如下语言进行训练,则当你输入Hi there!或者Greetings!的时候机器人会回复你Hello。
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
chatterbot = ChatBot("Training Example")
chatterbot.set_trainer(ListTrainer)
chatterbot.train([
"Hi there!",
"Hello",
])
chatterbot.train([
"Greetings!",
"Hello",
])
还可以提供更长的训练对话清单。这将在列表中建立每个项目作为响应。
chatterbot.train([
"How are you?",
"I am good.",
"That is good to hear.",
"Thank you",
"You are welcome.",
])
以上介绍来源于:[ ChatterBot聊天机器人 ] ChatterBot训练数据以及使用三方语料库训练数据 - pytorch中文网
下面为原创内容
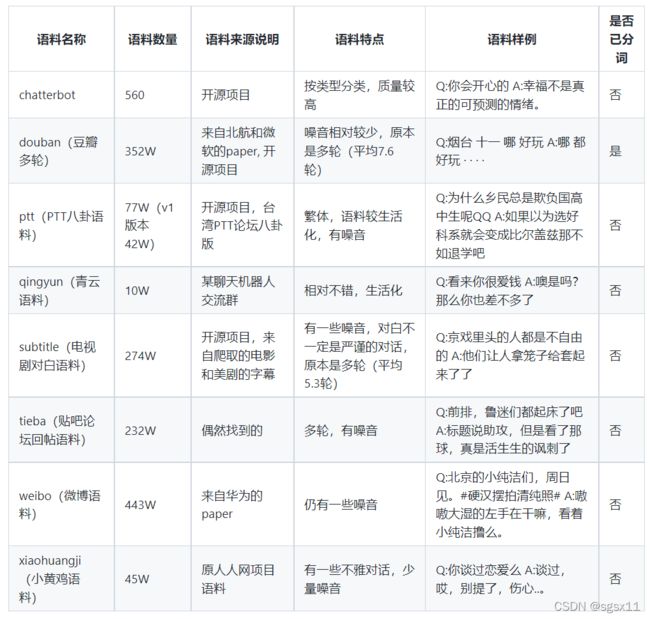
3、使用第三方中文语料库进行训练
大佬整理的语料库地址:https://github.com/codemayq/chinese_chatbot_corpus
chatterbot自带的语料库可以通过以下代码来实现,不需要额外下载:
from chatterbot.trainers import ChatterBotCorpusTrainer
chatterbot = ChatBot("Training Example")
chatterbot.set_trainer(ChatterBotCorpusTrainer)
chatterbot.train(
"chatterbot.corpus.english"
)
我选择了语料数量较少的xiaohuangji语料库:https://github.com/candlewill/Dialog_Corpus
首先下载未分词的语料库

下载解压后将后缀改为.txt
![]()
打开后是这样的:

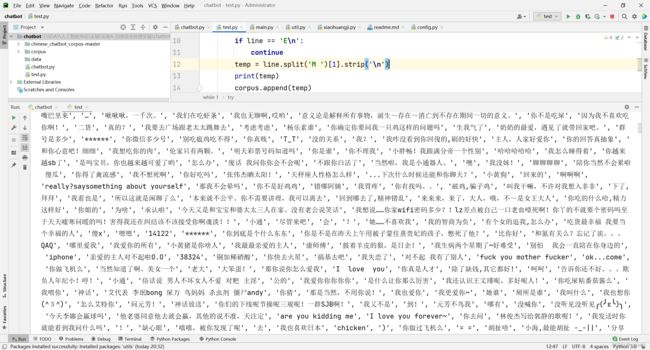
接下来就是把txt文件按行读取并存入列表中,注意要跳过’E’那一行,并且把每句话开头的’M '去掉
具体代码为:
#导入语料库
file = open("./corpus/xiaohuangji50w_nofenci.txt",'r',encoding='utf-8')
corpus = []
print('开始加载语料!')
while 1:
try:
line = file.readline()
if not line:
break
if line == 'E\n':
continue
corpus.append(line.split('M ')[1].strip('\n'))
except:
pass
file.close()
print('语料加载完毕')
处理后效果:
如果出现下面的报错,在将line.split('M ')[1].strip('\n')存入corpus列表前print(line.split('M ')[1].strip('\n'))就好了

4、应用案例实现
4.1 开始训练
我们取前10000条语料进行训练my_bot.train(corpus[:10000])
my_bot = ChatBot("xiaohuangji")
my_bot.set_trainer(ListTrainer)
print('开始训练!')
my_bot.train(corpus[:10000])
print('训练完毕!')
while True:
print(my_bot.get_response(input("user:")))

4.2 训练结果

5、总结
由于第一次使用ChatterBot,也没有过多的时间去研究,还不知道怎么直接训练.tsv文件,于是采取直接读取txt,然后通过列表数据进行训练chatterbot.trainers.ListTrainer(storage, **kwargs)。
经过实践该种方法在训练大量语料时很慢,训练10000条语料后的回答时间大概在一分钟,不过回答的质量是高于chattbot提供的560条中文语料训练的结果的。
6、参考文章
[ ChatterBot聊天机器人 ] ChatterBot训练数据以及使用三方语料库训练数据
[两种开源聊天机器人的性能测试(一)——ChatterBot]