StyleGAN2探骊得珠(四):论文解读与注释,二代为什么放弃了Progressive Growing?
我们在前两篇篇文章里分别学习了StyleGAN2是怎样消除液滴伪影,又是怎样利用PPL来提升图像质量的,内容请参考:
StyleGAN2探骊得珠(二):论文解读与注释,一代中的ARTIFACT是怎样产生的,二代网络中又是怎样消除它们的?
上面这篇文章的内容对应于【表1】中的“B +Weight demodulation”。
StyleGAN2探骊得珠(三):论文解读与注释,二代是怎样利用PPL来提升图像质量的?
上面这篇文章的内容对应于【表1】中的“C +Lazy regularization”和“D +Path length regularization”。
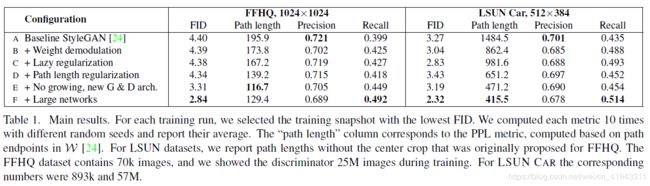
【表1】. 主要(测试)结果。对于每一轮训练,我们选用FID数值最低的训练快照。我们用不同的随机种子计算每个度量值10次,然后取它们的平均值写入报告。“路径长度”(Path length)这一列(数据)对应于PPL度量值,它基于W空间的路径终点进行计算。对于LSUN数据集,我们报告的路径长度没有采用(对图像进行)中心裁剪的方法,该方法最初提出时是为了让FFHQ(数据集)应用它。 FFHQ数据集包含了7万张图像,在训练过程中我们向判别器展示(或者说:投喂)了2500万张图像。对于LSUN CAR数据集,对应的数字是89.3万张与5700万张。
本篇文章将进一步学习StyleGAN2为什么放弃了渐进式生长(Progressive Growing)以及如何改善 1024x1024 分辨率上的图像输出质量,即【表1】中的“E +No growing, new G & D arch.”和“F +Large networks”所对应的内容。
论文的第4节论述了StyleGAN2是怎样对渐进式生长架构进行替换的。


4. 重新考虑渐进式生长
在使得高分辨率图像合成变得稳定这方面,渐进式生长很成功,但也造成了固有的特性伪影。其关键的问题在于,通过渐进式生长构造的生成器似乎对(图像)细节有很强的位置偏好;随附的视频显示:(随着被合成图像的整体外观出现平移,)当像牙齿、眼睛这样的特征理应在图像上平滑地移动时,它们也许并没有跳到下一个被优先考虑的位置上,而是被粘在原来的地方。【图6】显示了一个相关的伪影。我们相信,这个问题是这样产生的:在渐进式生长过程中,每个分辨率都暂时地充当输出分辨率,迫使在每个分辨率上都生成最大化频率的细节(译者注:具备尽可能多局部特征的细节,由于特征很密集,因而可以说频率很高),这就导致被训练的神经网络在中间层有过高频率的细节,从而损害了平移不变性。附录 A 给出了一个例子。这个问题促使我们寻找一个替代的方法,既保留渐进式生长的优点,同时又去除其缺点。

【图6】. 渐进式生长导致“阶段性”伪影。在这个例子中,牙齿(的位置)没有随着姿势改变而改变,而是保持与镜头对齐,如图中蓝线所示。

4.1. 替代的网络架构
论文中说,StyleGAN在生成器(合成网络)和判别器中使用了简单的前馈设计,同时有(其他学者的)大量工作专注于研究更好的网络架构。特别是,跳跃连接、残差网络和层级方法(hierarchical methods)已经证明在生成方法的语境方面也是非常成功的。按照这些方法,我们决定重新评估StyleGAN的网络设计,并寻找一种不使用渐进式生长即可生成高质量图像的架构。
【图7a】展示了MSG-GAN,它使用跳跃连接将生成器和判别器的对应分辨率(网络层)连接起来。MSG-GAN修改了生成器,它不输出图像,而是输出纹理映射(mipmap),对于每一个真实图像也都进行类似的计算。【图7b】中,我们简化了设计,使用上采样,并对不同分辨率上的RGB输出贡献求和。
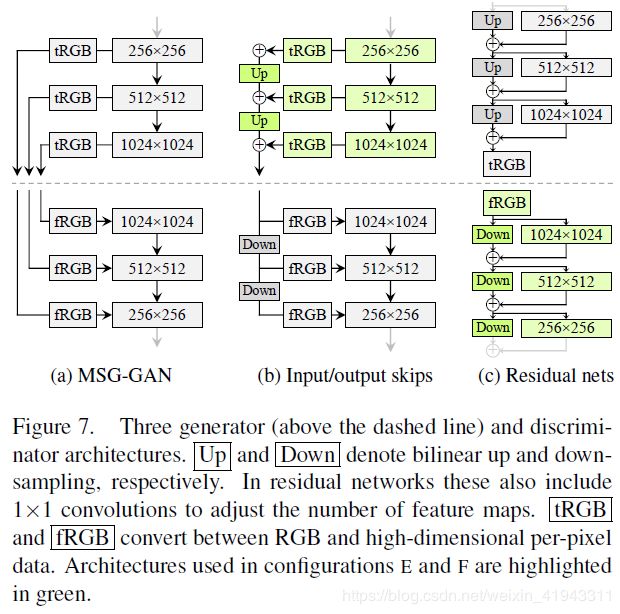
【图7】. 三种生成器(在虚线上方)和判别器架构。Up 和 Down 分别表示双线性上采样和下采样。在残差网络中这些(上采样和下采样)也包括 1x1 卷积以调整特征图的数量。tRGB 和 fRGB 完成 RGB 与高维度(每)像素数据之间的转换。配置 E 和配置 F中使用的架构用绿色高亮标出。

论文中说,(在判别器中,)我们类似地为判别器的每个分辨率块提供下采样图像。在所有的上采样和下采样运算中我们使用双线性滤波。【图7c】中,我们进一步修改设计,使用了残差连接³(译者注:论文在这里有一个小注,见下面的说明)。这个设计与LAPGAN相似,但没有用到Denon等人使用的每分辨率(对应的)判别器。

论文中的小注:残差网络架构中,两条路径求和(作为特征图输入)导致信号方差加倍,我们通过乘以1/√2予以消除。这对于我们的网络是至关重要的,而在分类resnet中,这个问题通常被批归一化运算所掩盖。
论文继续说,【表2】比较了三种生成器和三种判别器架构:StyleGAN使用的原始前馈网络、跳跃连接和残差网络,均不使用渐进式生长进行训练。我们提供了九种组合中的每一种的FID值和PPL值。我们可以看到两个一般性的趋势:在所有配置中生成器中的跳跃连接都大幅度地改善了PPL值,而残差判别器网络显然对(改善)FID值更有利。后者也许并不令人意外,因为判别器的结构与分类器相似,而残差架构在分类器中有用是众所周知的。但是,生成器中的残差架构却是有害的——唯一的例外是当(生成器与判别器)二者都是残差(网络)时,在LSUN CAR数据集上的FID值(得到了改善)。
论文中说,在本文的其余部分,我们使用跳跃(连接)生成器和残差(网络)判别器,不再使用渐进式生长。它对应于【表1】中的配置 E,正如表中所示,切换到这个设置显著改进了FID值和PPL值。
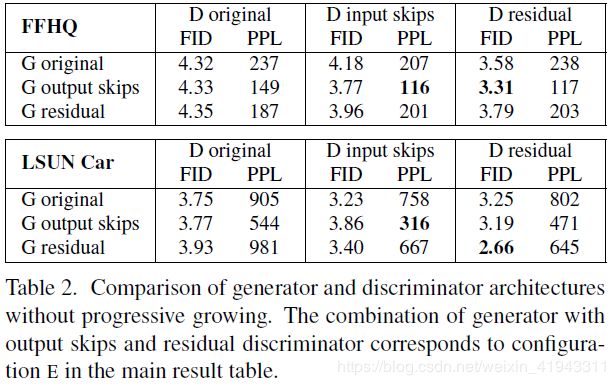
【表2】.对比没有渐进式生长的生成器和判别器架构。使用输出跳跃(连接)的生成器与使用残差(网络)的判别器二者的组合,对应于主(实验)结果表(译者注:【表1】)中的配置 E。
在大部分实验中,作者均改进了生成图像的 FID 和 PPL,似乎 StyleGAN2 的优化故事已经讲完了。但我们回顾一下【表1】,配置 F似乎还没有讲到,那么,配置 F 到底解决了什么问题呢?我们接着往下看。


4.2. 分辨率的使用
论文中说,渐进式生长的关键方面,也是我们情愿保留它的原因,在于生成器最初聚焦于低分辨率特征,然后慢慢把注意力转移到更为精细的细节上。【图7】中的架构使得生成器可以首先输出低分辨率图像,并且低分辨率图像不会被高分辨率网络层显著影响;然后,随着训练的进行,生成器将焦点转移到更高分辨率的网络层上。既然从任何方面看这都不是强制性的,那么生成器就只有在对生成结果有利时才会这么做。为了分析(训练)实践中(生成器)的行为,我们需要对生成器在整个训练过程中对特定分辨率的依赖程度进行定量分析。
既然跳跃(连接)生成器(【图7b】)是通过对多个分辨率上的RGB值的显式求和来生成图像的,那么我们就可以通过测量每一个网络层对最终图像的贡献大小来评估对应网络层的相对重要性。在【图8a】中我们画出了每个tRGB网络层产生的像素值的标准差,它是训练时间的函数。我们计算了1024个 w 向量随机样本的标准差,并把这些值进行归一化使得他们的和是100%。
也就是说,跳跃(连接)生成器并不是一定要先输出低分辨率图像,然后再逐步输出高分辨率图像,而是说这种架构能够基于训练优化的目标自然而然地从生成低分辨率特征开始,然后一步步生成更多的细部特征,最终在高分辨率上生成令人满意的图像。
为什么要用标准差来测量各分辨率网络层的贡献呢?这是因为,标准差越小,意味着同一个图像中各像素之间的差异越小,说明该网络层最终在输出图像呈现上的细节表达越少,即:贡献越小。反之,标准差越大,则细节表达越丰富,贡献也越大。
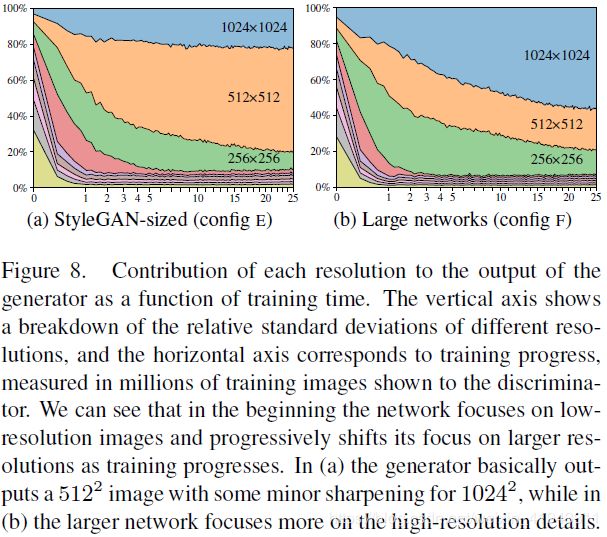
【图8】. 每一个分辨率对生成器输出的贡献,它是训练时间的函数。纵轴显示的是不同分辨率(网络层)的相对标准差的(比例)分解,而横轴对应的是训练进度,训练进度用展现给判别器的训练图像的百万级数量来度量。我们可以看到一开始网络聚焦于低分辨率图像,然后随着训练的推进,渐渐地将焦点转移到更大的分辨率上。在(a)图里,生成器大体上输出了一个 512x512 的图像,在 1024x1024 分辨率上有较小的锐化;在(b)图中,更大的网络更多地聚焦在高分辨率(译者注:1024x1024)的细节上。


论文中说,在训练的开始,我们可以看到新的跳跃(连接)生成器的表现与渐进式生长相似——现在,我们不用改变网络拓扑就实现了这一点(译者注:对应于不同的lod,渐进式生长所使用的学习率、小批量大小、甚至于正则化项会有所不同,说明训练神经网络的方法在不同lod是不同的,因此说需要“改变网络拓扑”,而跳跃连接生成器不需要改变网络拓扑)。因而在趋向于训练终点时我们期望最高分辨率(的贡献)占据优势是合理的。但是绘图显示在(训练)实践中这个情况并没有发生,这表明生成器也许不能充分利用目标分辨率。为了证实这一点,我们手工检查了生成的图像,注意到它们普遍缺少像素级细节,而这些细节在训练数据中都是存在的——这些图像可以描述为锐化版的 512x512 图像,而不是真正的 1024x1024 图像。
这促使我们假设在我们的网络中存在容量问题,我们通过将(生成器和判别器)两个网络最高分辨率网络层中的特征图数量加倍来进行测试。这使得(生成器)的表现与期望更为一致:【图8b】显示出最高分辨率网络层的贡献有了显著的提升,【表1】F 行显示 FID和召回率也大大地改善了。
【表3】在几个LSUN分类上,对StyleGAN和我们的改进变体进行了比较,再次显示出对 FID 显而易见的改进以及在PPL上极为显著的进步。进一步增大(神经网络的)尺寸有可能带来额外的益处。
但是,增大容量是有代价的,这意味着我们至少需要拥有11GB显卡内存的 NVIDIA GeForce RTX 2080Ti 才能把 StyleGAN2 真正跑起来,而官网推荐的是:16GB内存的NVIDIA GPU(即:NVIDIA Tesla V100)。至于这些显卡的价格,大家到网上查一下就知道了。

【表3】. 在LSUN数据集上的改进,用 FID 和 PPL 进行测量。我们训练CAR(小汽车)用了5700万张图像,训练CAT(猫)用了8800万张图像,CHURCH(教堂)用了4800万张图像,训练HORSE(马)用了1亿张图像。
至此,我们就通过四篇《StyleGAN2探骊得珠》系列文章,大体完整地对StyleGAN2的论文进行了解读,说明 StyleGAN2 从配置 B 到配置 F 是怎样一步步进行优化和发展的。
StyleGAN2论文的第5节主要讲的是如何将图像投射到潜码空间,这个问题在《轻轻松松使用StyleGAN2》系列文章里已经有较为详细的研究,这里就不再赘述了。
StyleGAN2论文的下载地址是:http://arxiv.org/abs/1912.04958
也可以到百度网盘下载:https://pan.baidu.com/s/15jv2hVVrcC-dsPjqZ_p9Xw 提取码: rvir
(完)