- java中校验手机号码的正则表达式
尼采呀
java正则表达式开发语言
一.匹配说明:正则表达式是描述字符串内容格式,使用它来匹配一个字符串的内容是否符合要求1.[]:表示一个字符,该字符可以是[]中指定的内容例如:[abc]:这个字符可以是a或b或c[a-z]:表示任意一个小写字母[a-zA-Z]:表示任意一个字母[a-zA-Z0-9_]:表示任意一个数字字母下划线[^abc]:该字符只要不是a或b或c预定义字符:.:表示任意一个字符,没有范围限制\d:表示任意一个
- 回溯法--力扣第17题“电话号码的字母组合”(java)
27xixi
数据结构与算法leetcodejava算法
力扣第17题“电话号码的字母组合”回溯法(DFS)回溯法通过递归遍历每个数字对应的字母,生成所有可能的组合。核心思想是构建搜索树,每次选择一个字母后进入下一层递归,回溯时撤销选择以尝试其他分支。实现步骤:构建数字到字母的映射表:使用数组或哈希表存储每个数字对应的字母。递归回溯:终止条件:当前路径长度等于输入数字字符串长度时,将结果加入列表。遍历当前数字对应的所有字母,依次选择、递归、撤销选择。Ja
- Java突击小练习--利用正则表达式来简易的校验邮箱与手机号格式
CJH~
java正则表达式mysql
//校验邮箱publicclassTestEmail{publicstaticvoidmain(String[]args){Scannerinput=newScanner(System.in);//*号代表任意数量,放在0-9a-zA-Z后面,代表可以写任意数量的字母和数字//@是邮箱的符号,接在刚刚那串的后面//|代表或,也就是说@后可以跟着qq或163或sina中的任意字符串,代表哪家邮箱//
- Redis 常用数据类型
27xixi
java技术栈redis数据库缓存
Redis常用数据类型的详细介绍及其典型应用场景:String(字符串)描述:最基本的数据类型,可存储文本、数字或二进制数据(最大512MB)。常用命令:SETkeyvalue:设置值GETkey:获取值INCRkey:将值自增1(原子性操作)EXPIREkeyseconds:设置过期时间应用场景:缓存简单键值对(如用户会话、配置项)。计数器(如文章阅读量、库存扣减)。分布式锁(结合SETNX命令
- 正则表达式全解析 + Java常用示例
我真的不想做程序员
算法javajava后端开发语言算法正则表达式
目录一、正则表达式基础(一)元字符(二)字符集(三)量词二、正则表达式常用示例(一)验证邮箱格式(二)验证电话号码格式(三)提取网页中的链接(四)验证日期格式(五)验证URL格式三、正则表达式在Java中的应用(一)匹配操作(二)替换操作(三)分割操作四、总结一、正则表达式基础正则表达式是一种用于匹配字符串的强大工具。它使用特定的语法来定义匹配模式,可以在文本处理、表单验证、数据提取等场景中发挥重
- python中将字符串转换成数字,并且保留两位小数
上趣工作室
pythonpython后端
在Python中,你可以使用float()函数将字符串转换为数字,并使用字符串格式化来保留小数点后两位。下面是一个示例代码:defconvert_to_float(string):try:number=float(string)formatted_number="{:.2f}".format(number)returnformatted_numberexceptValueError:return"
- 131.分割回文串
水代码的程序猿
力扣算法leetcode数据结构python
131.分割回文串力扣题目链接给你一个字符串s,请你将s分割成一些子串,使每个子串都是回文串。返回s所有可能的分割方案。示例1:输入:s="aab"输出:[["a","a","b"],["aa","b"]]示例2:输入:s="a"输出:[["a"]]提示:1List[List[str]]:result=[]path=[]self.backtracking(s,path,result)returnr
- 【正则表达式】
lmk565
工具正则表达式
文章目录1元字符2重复3字符4分支条件5反义6分组6.1捕获分组6.2非捕获分组7零宽断言8注释9贪婪与懒惰10POSIX字符类(仅US-ASCII)11转义12匹配模式1元字符代码说明.匹配除换行符以外的任意字符\w匹配字母或数字或下划线或汉字\s匹配任意的空白符\d匹配数字^匹配字符串的开始$匹配字符串的结束\b匹配字符串的结束举例:8答案:\d2重复代码/语法说明*重复零次或更多次+重复一次
- StringJoiner 详解
蓝白咖啡
Java基础Java
引言在Java8中,StringJoiner是一个用于构建由分隔符分隔的字符序列(如逗号分隔的字符串)的工具类。它提供了一种简洁、灵活的方式来拼接字符串,特别适合处理需要特定分隔符的场景。本文将详细介绍StringJoiner的特性、使用方法、优缺点以及实际应用场景。1.StringJoiner概述StringJoiner是Java8引入的一个工具类,位于java.util包中。它的主要作用是将多
- 软件测试之测试用例详细解读
隐居人家的炊烟
测试用例软件测试自动化测试
一、通用测试用例八要素1、用例编号;2、测试项目;3、测试标题;4、重要级别;5、预置条件;6、测试输入;7、操作步骤;8、预期输出二、具体分析通用测试用例八要素1、用例编号一般是数字和字符组合成的字符串,可以包括(下划线、单词缩写、数字等等),但是需要注意的是,尽量不要写汉语拼音,因为拼音的意义可能有好几种,有可能会导致乱码;用例编号具有唯一性和易识别性。(比如说我们唯一标识一个人:中国-上海市
- Python eval 函数
Python 学习者
Python
Pythoneval函数学习与总结。基本用法简介eval()函数用来执行一个字符串表达式,并返回表达式的值。eval(expression[,globals[,locals]])expression:表达式。globals:变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。locals:变量作用域,局部命名空间,如果被提供,可以是任何映射对象。>>>x=7>>>eval('3*x')21
- Python中的eval函数
a1274646034
python
一、简介:eval函数就是实现list、dict、tuple与str之间的转化,而str函数实现把list、dict、tuple转换成字符串1、字符串转化为列表1#字符串转化为列表2a="[[1,2],[3,4],[5,6],[7,8],[9,10]]"3print(type(a))4b=eval(a)5print(type(b))6print(b)123[[1,2],[3,4],[5,6],[7
- iOS OC使用正则表达式去除特殊符号并加粗文本,适用于接入AI大模型的流模式数据的文字处理
MrZWCui
iOSiosxcodeobjective-c正则表达式学习
1、编写逻辑使用分类(Category)的方法拓展NSString,本文使用NSString(Markdown),NSString的分类来编写一个通用方法,使用正则表达式匹配字符串实现去除特殊字符,并自定义文字属性。在接入AI大模型后,返回的字符串会带有特殊字符用于做文字处理,下面代码简单进行了文字处理展示。2、代码实现1、NSString+Markdown.h#importNS_ASSUME_N
- String类型为什么不可变
27xixi
java高频java
在大多数编程语言(如Java、Python、C#等)中,String类型被设计为不可变(Immutable),这意味着一旦一个字符串对象被创建,它的值就不能被修改。以下是这一设计的原因及具体表现:一、不可变性的表现直接修改字符串会创建新对象Stringstr="Hello";str=str+"World";//实际是创建了一个新字符串对象,而非修改原对象原字符串“Hello”未被修改,而是生成了新
- 数值类型自学引导
Ssaty.
python前端数据库
第1关:计算边长为整数的正方形面积任务描述本关任务:编写一个能计算正方形面积的小程序。相关知识为了完成本关任务,你需要掌握:1.输入函数2.字符串转整数3.数值运算4.输出函数#输入一个正整数,以其数值为正方形的边长,计算并输出正方形的面积width=int(input())print(width**2
- Python字符串
DDD小小小宇宙
python开发语言
字符串1.程序中需要加上双引号或者双引号来表示字符串2.字符串可以存放任意数量的字符,无法修改的数据容器字符串运算:加法:多个字符串按照次序合并为一个字符串在实际使用的时候,数字和字符串的加法通常需要将数字的类型转换成str乘法:1个字符串乘以n,可以得到n个复制的字符串例子:输入一个字符,使用该字符打印一个3层的金字塔x=input(':')print(""+x)print(""+x+x+x)p
- 正则问题-DFS
艾菲尔上的铁塔梦xx
深度优先算法
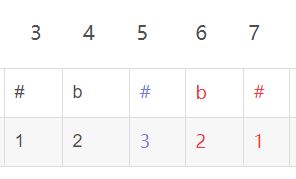
题目描述考虑一种简单的正则表达式:只由x()|组成的正则表达式。小明想求出这个正则表达式能接受的最长字符串的长度。例如((xx|xxx)x|(x|xx))xx能接受的最长字符串是:xxxxxx,长度是6。输入描述一个由x()|组成的正则表达式。输入长度不超过100,保证合法。输出描述这个正则表达式能接受的最长字符串的长度。输入输出样例示例输入((xx|xxx)x|(x|xx))xx输出6运行限制最
- 【JAVA进阶系列】进阶知识 -- Class类 getName()、getCanonicalName()、getSimpleName()、getTypeName()
m0_74823658
面试学习路线阿里巴巴java开发语言
【JAVA进阶系列】进阶知识--Class类getName()、getCanonicalName()、getSimpleName()、getTypeName()方法的异同【1】getName()返回该类对象作为字符串表示的实体(类、接口、数组类、基本数据类型或void)的名称可以理解为返回的是虚拟机中Class对象的表示当动态加载类的时候,会用到该方法的返回值,如:使用Class.forName(
- ArkTs进阶
万事顺心
开发语言鸿蒙typescript
字符串加号两边只要有字符串,就是拼接的作用。模版字符串(`xxx`)主要用于拼接多个变量的字符串拼接letname:string='Tom'console.log(`姓名:${name}`)类型转换1.字符串转数字Number():字符串直接转数字,转换失败返回NaN(字符串中包含非数字)(常用)parseInt():去掉小数部分转数字(取整),转换失败返回NaNparseFloat():保留小数
- html字段最大长度限制,html input 限制输入的长度并提示的方法
朱佳顺
html字段最大长度限制
html中input标签的value值的长度理论上应该是2^32(数据来源于资料,没有测试过),但为了防止一些input的输入数据过长来做一些限制,该如何实现呢?这篇文章就来介绍一下,如何限制input输入数据的长度并且输入的数据超过规定的长度该如何去提示?htmlinput限制输入字符串长度的方法input标签中的maxlength属性,可以用来规定输入字符串的最大长度。示例代码:htmlinp
- C语言字符相加得到什么?字符串相加呢?
GKDf1sh
c语言javaservlet开发语言
#include int main(void){ char d = '1'+'2'; printf("%c",d);//输出结果为c,ASSII码的099恰好是c printf("%d\n",d);//输出结果为99,即ASCII码的十进制数相加(49+50),得出结论两个字符相加的结果为ASCII码相加的结果 //字符串相加的结果又是什么呢? cha
- 代码随想录算法训练营DAY05之栈和队列
失序空间
跟着代码随想录学算法算法c++
题目和链接232.用栈实现队列225.用队列实现栈20.有效的括号1047.删除字符串中的所有相邻重复项150.逆波兰表达式求值239.滑动窗口最大值347.前k个高频元素232.用栈实现队列题意:请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):实现MyQueue类:voidpush(intx)将元素x推到队列的末尾intpop()从
- 《Windows API开发》:(一)Windows编程概述
下雪就该搓雪球
一些小玩意windows
(一)Windows编程概述1、WindowsAPI简介2、Windows应用程序开发入门2.1、第一个实例程序3、WindowsAPI概要3.1、Windows数据类型3.2、WindowsAPI的功能分类4、WindowsAPI核心DLL5、Unicode和多字节5.1、字符串类型与其初始化5.2、W版本和A版本的API5.3、Unicode和ASCII的转换6、Windows程序设计规范的建
- 【第六节】windows sdk编程:Windows 中的资源
攻城狮7号
Windows编程(C++)windowsc++windows编程windowssdk
引言资源是Windows应用程序图形用户界面(GUI)的重要组成部分,它们是应用程序中使用的各类数据,如光标、位图、图标、加速键、菜单、字符串和对话框等。这些数据在编译后会被包含在EXE文件中。虽然无法直接定位和操作资源,但可以通过相关函数来获取和操作这些资源。一、光标资源1.1应用程序操作光标资源的步骤(1)选择或创建光标形式可以使用Windows系统提供的光标,也可以通过图形编辑工具自定义光标
- ruby的命令行选项
lizzywu
工具介绍ruby脚本编译器extensionshellcgi
ruby的命令行选项来源:LUPA开源社区发布时间:2007-06-2117:04版权申明字体:小中大文章来源于http://www.lupaworld.com请使用如下命令行启动Ruby解释器.ruby[option...][--][programfile][argument...]这里的"option"指下文将要提到的命令行选项中的一个。"--"则显式地表明选项字符串到此结束。"program
- Harmonyos开发——TypeScript基础
凌煦
Harmonyostypescriptjavascript
TypeScript基础一、变量类型(1)number型:可以表示int、float、double同时也可表示8、16进制等letnum1:number=0letnum2:number=12.3(2)string型:表示字符串letstr:string="helloworld!"(3)boolean型letfin:Boolean=true(4)any型:可以跳过类型检测(不建议常用)leta:an
- 数据结构 -- 字符串
_安晓
数据结构数据结构
字符串串的定义串,即字符串(String)是由零个或多个字符组成的有限序列,一般记为S=‘a1a2a3a4’(n≥0)其中,S是串名,单引号括起来的是字符序列是串的值;ai可以是字母、数字或是其他字符;串中字符的个数n称为串的长度。n=0时的串称为空串(用∅表示)。例:(不同语言可能使用的边界符不同,Java、c等使用双引号(“”)Python等使用单引号(’‘))S="HelloWorld!"T
- 779. 最长公共字符串后缀(Acwing)
十九587
算法数据结构考研c++
题目描述:给出若干个字符串,输出这些字符串的最长公共后缀。输入格式由不超过5组输入组成。每组输入的第一行是一个整数N。N为0时表示输入结束,否则后面会继续有N行输入,每行是一个字符串(字符串内不含空白符)。每个字符串的长度不超过200。输出格式每组数据输出一行结果,为N个字符串的最长公共后缀(可能为空)。数据范围1≤N≤200输入样例:3babaabacba2aacc2aaa0输出样例:baa解题
- Flask-ORM方式操作Mongodb
Enougme
Flaskmongodbflask
前言在实际项目中,我们有时需要存储一些json类型的字符串,这种类型的数据写入到关系型数据库,会比较麻烦。一般我们将其写入到非关系型数据库中,例如MongoDB,同样我们也可以用操作关系型数据库的ORM方式操作MongoDB。1:配置文件的(settings.py)MONGODB_SETTINGS=[{'db':'api_params','host':MONGO_DB,'port':27017,"
- 438. 找到字符串中所有字母异位词
Zannnne
leetcode
438.找到字符串中所有字母异位词题号:力扣438知识点:字符串,滚动窗口目标完成度:59/150总结题干:思路:1.如果s的长度小于p,则s中必然找不到与p是异位词的子串。2.异位词的特点是每个字母出现的次数一直,但是出现的顺序不一定相同。因此我们建立两个容器,来记录p中和滚动窗口中每个字母出现的次数,由于字母一共只有26个,所以容易大小为26。3.第一个for循环相当于是对scount进行初始
- Java实现的简单双向Map,支持重复Value
superlxw1234
java双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
- PL/SQL触发器基础及例子
百合不是茶
oracle数据库触发器PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
- [时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
- easy ui datagrid上移下移一行
商人shang
js上移下移easyuidatagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
- Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
- springMVC 使用JSR-303 Validation验证
杨白白
springmvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
- log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
- 使用ajax和history.pushState无刷新改变页面URL
agevs
jquery框架Ajaxhtml5chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
- centos中文乱码
AILIKES
centosOSssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
- 触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
- JS正则表达式的i m g
bijian1013
JavaScript正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
- HTML5模式和Hashbang模式
bijian1013
JavaScriptAngularJSHashbang模式HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
- [Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
- 【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
- 记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
- 巧用视错觉-UI更有趣
brotherlamp
UIui视频ui教程ui自学ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
- 线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构算法线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
- HTTP协议详解
chicony
http协议
引言
- Scala设计模式
chenchao051
设计模式scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
- 安装mysql
daizj
mysql安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
- HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
- asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
- C语言中,关键字static的作用
e200702084
C++cC#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
- win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
- Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
- Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转递归反转二分交换反转java字符串反转栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
- 代码实现任意容量倒水问题
home198979
PHP算法倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
- Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
- 两种启动监听器ApplicationListener和ServletContextListener
spjich
javaspring框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
- JavaScript Rounding Methods of the Math object
何不笑
JavaScriptMath
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen