Java常用类库
1):StringBuffer类:
String、StringBuffer、StringBuilder的区别
1.String一旦声明,不可改变,StringBuffer与StringBuilder声明的内容可以改变
2.StringBuffer类中提供的方法都是同步方法,属于安全的线程操作,而StringBuilder类中大的方法都是属于异步方法,属于非线程安全的操作。
2):Runtime类
Runtime类是Java中与运行时环境有关的操作类,利用此类可以取得系统的内存信息,也可以利用此类产生新的操作系统进程对象。
Runtime类表示运行时操作类,是一个封装了JVM进程的类,每一个JVM都对应着一个Runtime类的实例,此实例由JVM运行时为其实例化。
Runtime run = Runtime.getRuntime();
package library;
public class RuntimeDemo {
public static void main(String[] args) {
Runtime run = Runtime.getRuntime();//通过Runtime类的静态方法为其进行实例化操作
System.out.println("JVM最大内存量:"+run.maxMemory());//观察最大内存量,根据机器环境会有所不同
System.out.println("JVM空闲内存量:"+run.freeMemory());//取得程序运行时的内存空闲量
String str = "Hello"+"World"+"!!!"+"\t"+"Welcome"+"To"+"MLDN"+"~";
System.out.println(str);
for (int i = 0; i < 100; i++) {//循环修改Sting,产生多个垃圾,会占用内存
str+=i;
}
System.out.println("操作String之后的,JVM空闲内存量:"+run.freeMemory());//观察有多个垃圾空间产生之后的内存空闲量
run.gc();//进行垃圾收集,释放空间
System.out.println("垃圾回收之后的,JVM空闲内存量:"+run.freeMemory());//垃圾收集之后的内存空闲量。
}
}
结果:
JVM最大内存量:66650112
JVM空闲内存量:4934616
HelloWorld!!! WelcomeToMLDN~
操作String之后的,JVM空闲内存量:4877968
垃圾回收之后的,JVM空闲内存量:50158401.GC(Garbage Collector,垃圾收集器)指的是释放无用的内存空间。
2.GC会由系统不定期进行自动回收,或者调用Runtime类中的gc()方法手工回收。
Runtime类与Process类
调用本机可执行程序
package library;
import java.io.IOException;
/**
* 调用本机可以执行程序
* 让记事本进程5s后消失
*/
public class RuntimeDemo2 {
public static void main(String[] args) {
Runtime run = Runtime.getRuntime();//通过Runtime类的静态方法为其进行实例化操作
Process pro = null;//声明一个Process对象,接受启动的进程
try {
pro = run.exec("notepad.exe");//调用本机程序,必须进行异常处理
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();//打印异常信息
}
try {
Thread.sleep(5000);//让此线程存活5s
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();//打印异常信息
}
pro.destroy();//结束此进程
}
}
3):国际化程序
国际化操作是指程序可以同时适应多门语言。
实现国际化光靠Locale类是不够的,还需要属性文件和ResourceBundle类的支持。属性文件是指扩展名为.properties的文件,文件中的内容保存结构是一种“key=value”的形式,因为国际化的程序只显示语言的不同,那么就可以根据不同的国家定义不同的属性文件,属性文件中保存真正要使用的文字信息,要访问这些属性文件,可以使用ResourceBundle类来完成。
实现java程序国际化操作必须通过一下3各类完成:
java.util.Local-----java.util.ResourceBundle---MessageFormat
通过Locale类所指定的区域码,然后ResourceBundle根据Locale类所指定的区域码找到相应的资源文件,如果资源文件(属性文件)中存在动态文本,子使用MesssageFormat进行格式化。
属性文件定义时,必须要按照“名称_国家代码”的形式命名,即所有的相关属性文件的名称全部一样,只有国家的代码不一样,代码如下
(处理动态文本:以中文为例是:”你好,xxx!“,其中“xxx”的内容是由程序动态设置的,那么就需要使用占位符清楚地表示出动态文本的位置,占位符使用“{编号}”的格式出现。使用占位符之后,程序可以使用MessageFormat对信息进行格式化。为占位符动态设置文本的内容。)
1.中文的属性代码文件:Message_zh_CN.propertiesinfo = \u4f60\u597d\uff01
以上信息就是中文:你好,{0}!
2.英语属性文件:Message_en_US.properties
info = Hello,{0}!
3.法语属性文件:Message_fr_FR.properties
info = Bonjour,{0}!
通过Locale类和ResourceBundle类读取属性文件的内容,代码如下:
package library;
import java.text.MessageFormat;
import java.util.Locale;
import java.util.ResourceBundle;
public class InterDemo {
public static void main(String[] args) {
Locale zhLoc = new Locale("zh","CN");//表示中国地区
Locale enLoc = new Locale("en","US");
Locale frLoc = new Locale("fr","FR");
ResourceBundle zhrb = ResourceBundle.getBundle("Message",zhLoc);//找到中文的属性文件(.getBundle(文件名称,区域码))
ResourceBundle enrb = ResourceBundle.getBundle("Message",enLoc);
ResourceBundle frrb = ResourceBundle.getBundle("Message",frLoc);
String str1 = zhrb.getString("info");
String str2 = enrb.getString("info");
String str3 = frrb.getString("info");
System.out.println("中文:"+MessageFormat.format(str1, "你好"));//通过键值读取属性文件的类容
System.out.println("英文:"+MessageFormat.format(str2, "nihao"));
System.out.println("法文:"+MessageFormat.format(str3, "nihao"));
}
}
结果:
中文:你好,你好!
英文:Hello,Hello!
法文:Bonjour,Hello!多个占位符设置多个动态文本:
MessageFormat.format(str1,"你好",“hello”,"hello")
info = Hello,{0},{1},{2}!
4):System类、
System类是一些与系统相关的属性和方法的集合,而且在System类中所有的书信给都是静态的,要引用这些属性和方法,直接使用System类调用即可。
System.gc():垃圾对象的回收,如果在一个对象被回收之前要进行某些操作,那么该怎么办呢,实际上,在Object类中有一个finalize()方法,此方法定义如下:
protected void finalize() throws Throwable
package library.finalize;
public class Person {
private String name;
private int age ;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "年龄:age=" + age + ",姓名: name=" + name ;
}
public void finalize()throws Throwable{//对象释放空间时默认调用此方法
System.out.println("对象被释放 -->"+this);//直接打印对象调用toString
}
public static void main(String[] args) {
Person per = new Person("张三",30);
per = null;//断开引用释放空间
//以上代码不会在显示器显示输出
System.gc();//强制性释放空间,,会调用fianlize()方法
}
}
结果:
对象被释放 -->年龄:age=30,姓名: name=张三5):日期操作类
Date类:实例化对象 Date date = new Date();------输出当前日期
Calendar类,可以将取得的时间精确到毫秒,但是他是一个抽象类,依靠其子类GregorianCalendar类。
Dateformat类
SimpleDateFormat类
6)Math类
7):Random类
8):NumberFormat类
9):BigInteger类
10):Bigdecimal类
11):对象克隆技术
12):Arrays类
package library;
import java.util.Arrays;
public class ArraysDemo {
public static void main(String[] args) {
int temp[] = {3,5,7,9,1,2,6,8};
Arrays.sort(temp); //数组排序
System.out.println("排序后数组:");
System.out.println(Arrays.toString(temp));//以字符串输出数组
int point = Arrays.binarySearch(temp, 3);//检索数据位置
System.out.println("元素3的位置在:"+point);
Arrays.fill(temp, 3); //填充数组
System.out.println("数组填充:");
System.out.println(Arrays.toString(temp));//一字符串输出数组
}
}
结果:
排序后数组:
[1, 2, 3, 5, 6, 7, 8, 9]
元素3的位置在:2
数组填充:
[3, 3, 3, 3, 3, 3, 3, 3]
13):Comparable接口
比较器主要是针对对象数组的操作
package library.comparabledemo;
import java.util.Arrays;
public class Student implements Comparable {
private String name;
private int age;
private float score;
public Student(String name, int age, float score) {
super();
this.name = name;
this.age = age;
this.score = score;
}
@Override
public String toString() {
return "Student [age=" + age + ", name=" + name + ", score=" + score
+ "]";
}
@Override
public int compareTo(Student o) {
if (this.score>o.score) {
return -1;
}else if (this.scoreo.age) {
return 1;
}else if (this.age 结果:
Student [age=22, name=孙七, score=100.0]
Student [age=20, name=王五, score=99.0]
Student [age=20, name=张三, score=90.0]
Student [age=20, name=赵六, score=70.0]
Student [age=22, name=李四, score=9.0]
分析比较器的排序原理
使用的是二叉树排序方法,即通过二叉树进行排序,然后利用中序遍历的方式把内容依次读取出来。
二叉树排序的基本原理就是:将第1个内容作为根节点保持,如果后面的值比根节点的值小,则放在根节点的左子树,如果后面的值比根节点的值大,则放在根节点的右子树。
找这样的思路,如果给出了一下数字:8、3、10、14、6、4、7、1、13
在根据中序遍历的原理(左子树---根节点---右子树的方式),排序后的结果:1、3、4、6、7、8、10、13、14
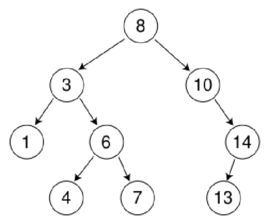
package library.comparabledemo;
public class BinaryTree {
class Node{ //申明一个节点类
private Comparable data; //保存具体类容
private Node left; //保存左子树
private Node right; //保存右子树
public void addNode(Node newNode){
if(newNode.data.compareTo(this.data)<0){
if(this.left==null){ //放在左子树
this.left = newNode;
}else {
this.left.addNode(newNode); //递归
}
}
if(newNode.data.compareTo(this.data)>=0){
if (this.right==null) { //放在右子树
this.right = newNode;
}else {
this.right.addNode(newNode); //递归
}
}
}
public void printNode(){ //输出时采用中序遍历
if(this.left!=null){ //如果左子树有值,则递归调用该方法,该操作会将中序,root.data左边的数字现输出,而且时从小到大的顺序
this.left.printNode();
}
System.out.print(this.data+"\t"); //输出root.data--->根节点
if (this.right!=null) { //如果右子树有值,则递归调用该方法,该操作会将中序,root.data左边的数字现输出,而且时从小到大的顺序
this.right.printNode();
}
}
}
private Node root; //根元素
public void add(Comparable data){
Node newNode = new Node(); //每传入一个数值,就声明一个新的根节点
newNode.data = data;
if (root == null) {
root = newNode; //如果是第1个元素,设置根节点
}else {
root.addNode(newNode); //确定结点是放在左子树还是右子树
}
}
public void print(){ //输出节点
this.root.printNode();
}
public static void main(String[] args) {
BinaryTree bt = new BinaryTree();
bt.add(8);
bt.add(7);
bt.add(14);
bt.add(10);
bt.add(4);
bt.add(1);
bt.add(13);
bt.add(6);
bt.add(3);
System.out.println("排序后的结果:");
bt.print();
}
}
结果:
排序后的结果:
1 3 4 6 7 8 10 13 14 15):Observable类和Observer接口,
他们可实现观察者模式(详情请移步:https://blog.csdn.net/weixin_42476601/article/details/84262436)
16):正则表达式
| 序号 | 规范 | 描述 | 序号 | 规范 | 描述 |
|---|---|---|---|---|---|
| 1 | \\ | 表示反斜线(\)字符 | 9 | \w | 字母、数字、下划线 |
| 2 | \t | 制表符 | 10 | \W | 非字母、数字、下划线 |
| 3 | \n | 换行 | 11 | \s | 所有的空白字符(如:换行,空格等) |
| 4 | [abc] | 字符a、b 或c | 12 | \S | 所有非空白字符 |
| 5 | [^abc] | 除了abc以外的任意字符 | 13 | ^ | 行的开头 |
| 6 | [a-zA-Z0-9] | 由字母、数字组成 | 14 | $ | 行的结尾 |
| 7 | \d | 数字 | 15 | . | 匹配除换行符之外的任意字符 |
| 8 | \D | 非数字 |
| 序号 | 规范 | 描述 | 序号 | 规范 | 描述 |
|---|---|---|---|---|---|
| 1 | X | 必须出现依次 | 5 | X{n} | 必须出现n次 |
| 2 | X? | 出现0或1次 | 6 | X{n,} | 必须出现n次以上 |
| 3 | X* | 出现0、1次或多次 | 7 | X{n,m} | 必须出现n~m次 |
| 4 | X+ | 可以出现1次或多次 |
| 序号 | 规范 | 描述 | 序号 | 规范 | 描述 |
|---|---|---|---|---|---|
| 1 | XY | X规范后跟着Y规范 | 5 | (X) | 作为一个捕获组规范 |
| 2 | X|Y | X规范或Y规范 |
package library.regex;
public class RegexDemo1 {
public static void main(String[] args) {
String info = "LXH:98|MLDN:90|LI:100";
String s[] = info.split("|"); //按照“|”拆分
System.out.println("字符串的拆分:");
for (int i = 0; i < s.length; i++) {
System.out.print(s[i]+"、");
}
}
}
结果:
字符串的拆分:
、L、X、H、:、9、8、|、M、L、D、N、:、9、0、|、L、I、:、1、0、0、package library.regex;
public class RegexDemo2 {
public static void main(String[] args) {
String info = "LXH:98|MLDN:90|LI:100";
String s[] = info.split("\\|"); //按照“|”拆分,需要转义
System.out.println("字符串的拆分:");
for (int i = 0; i < s.length; i++) {
String s2[] = s[i].split(":");
System.out.println("\t|--"+s2[0]+"\t"+s2[1]);
}
}
}
字符串的拆分:
|--LXH 98
|--MLDN 90
|--LI 100
17):定时调度---Timer类、TimerTask类
Timer类是一个线程设施,可以用来实现在某一个时间或某一段时间后按排某一个任务执行一次或定期重复执行。该功能要与TimerTask配合使用。
package library.timer;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.TimerTask;
public class MyTask extends TimerTask { //任务调度类要继承TimmerTask类
@Override
public void run() {
// TODO Auto-generated method stub
SimpleDateFormat sdf = null;
sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSSS");
System.out.println("当前系统时间:"+sdf.format(new Date()));
}
}
package library.timer;
import java.util.Timer;
public class TestTask {
public static void main(String[] args) {
Timer t = new Timer(); //建立Timer对象
MyTask mt = new MyTask(); //定义任务
t.schedule(mt, 1000,2000); //设置任务的执行,1秒后开始,每2秒重复
}
}
部分结果:
当前系统时间:2018-11-22 00:09:27:0842
当前系统时间:2018-11-22 00:09:29:0816
当前系统时间:2018-11-22 00:09:31:0826
当前系统时间:2018-11-22 00:09:33:0840
要点:
- 字符串频繁修改使用StringBuffer类,线程安全
- Runtime表示运行时,在JVM中只有一个Runtime,所以想取得Runtime类的对象,直接使用Runtime类中提供的静态方法getRuntime()即可
- 国际化程序实现的基本原理:所有的语言信息已key-->value的形式保存在资源文件中,程序通过key找到相应的value,根据其所设置国家的Locale对象不同,找到的资源文件也不同,要想实现国际化必须依靠Locale、ResourceBundle两类共同完成
- System是系统类,可以取得系统的相关信息,使用System.gc()方法可以强制性进行垃圾回收操作,调用此方法实际上就是调用Runtime类中的gc()方法
- Format类为格式操作类,主要的3个子类是Messageformat、NumberFormat、DateFormat。
- 使用Date类可以方便的取得时间,但取得时间格式不符合低于的习惯,所有可以使用SimpleDateFormat类进行日期的格式化操作
- 处理大数字可以使用BigInteger、BigDecimal,当需要精确小数点操作位数时,使用Bigdecimal类即可
- 通过Random类可以取得指定范围的随机数字
- 如果一个类的对象要箱被克隆,则此对象所在的类必须实现Cloneable接口
- 要箱对一组对象进行排序,则必须使用比较器。比较器接口Comparable中定义了一个compareTo()的比较方法,用来设置比较规则。
- 正则表达式是在开发中最常使用的一种验证方法,String类中的replaceAll()、split()、matches()方法都是对正则有所支持
- 可以使用Timer类和TimerTask类完成系统的定时操作。