Postgres主从库配置操作文档
PostgreSQL数据库本身提供三种HA模式:
1. 基于日志文件的复制
Master库向Standby库异步传输数据库的WAL日志,Standby解析日志并把日志中的操作重新执行,以实现replication功能。缺点在于Master库必须等待每个WAL日志填充完整后才能发给Standby,如果在填充WAL日志的过程中Master库宕机,未发送的日志内的事务操作会全部丢失。
2. 异步流复制模式
Master库以流模式向Standby库异步传输数据库的WAL日志,Standby解析收到的内容并把其中的操作重新执行,以实现replication功能。这种方式和“基于日志文件的复制”相比不需要等待整个WAL日志填充完毕,大大降低了丢失数据的风险,但在Master库事务提交后,Standby库等待流数据的时刻发生Master宕机,会导致丢失最后一个事务的数据。同时备库可以配置成HOT Standby,可以向外提供查询服务,供分担负载。
3. 流同步复制模式(Synchronous Replication)
顾名思义,是流复制模式的同步版本。向Master库发出commit命令后,该命令会被阻塞,等待对应的WAL日志流在所有被配置为同步节点的数据库上提交后,才会真正提交。因此只有Master库和Standby库同时宕机才会丢数据。多层事务嵌套时,子事务不受此保护,只有最上层事务受此保护。纯读操作和回滚不受此影响。同时备库可以配置成HOT Standby,可以向外提供查询服务,供分担负载。采用这种模式的性能损耗依据网络情况和系统繁忙程度而定,网络越差越繁忙的系统性能损耗越严重。
postgres在9.0之后引入了主从的流复制机制,所谓流复制,就是从库通过tcp流从主库中同步相应的数据。大概效率为3w多事务qps
可以依据实际情况权衡以上三种数据库复制模式的优缺点决定使用哪一种数据库高可用模式。这里推荐使用第二种高可用方式(异步流复制模式)实现数据库高可用
测试实现:
master数据库:192.168.200.241 5432
slave数据库:192.168.200.243 5433 (5432端口已经在运行另外一个库)
注意: 操作之前,一定要先进行数据库手动备份
master主库配置:
1、登陆Master库,创建具有用于传递数据的具有replication权限的用户

CREATE ROLE replicator login replication password '123456';
2、修改pg_hba.conf,把Master库和Standby库的IP地址添加进Master库网络策略白名单中,使Standby库可以连上Master库,同时便于主备切换:

host replication replicator 192.168.200.241/32 md5
host replication replicator 192.168.200.243/32 md5
3、修改Master库的配置文件postgresql.conf,在原配置文件postgresql.conf的基础上修改,修改内容如下:

wal_level = hot_standby # 这个是设置主为wal的主机
max_wal_senders = 32 # 这个设置了可以最多有几个流复制连接,差不多有几个从,就设置几个
wal_keep_segments = 256 # 设置流复制保留的最多的xlog数目
wal_sender_timeout = 60s # 设置流复制主机发送数据的超时时间
max_connections = 100 # 这个设置要注意下,从库的max_connections必须要大于主库的
4、重启主库服务
slave从库配置:
1、创建数据库目录,完全备份一次主库数据:
![]()
这里使用了pg_basebackup这个命令,postgressql_data_241这个目录可以先创建空目录,成功之后,就可以看到这个目录中现有的文件都是一样的了
pg_basebackup -F p --progress -D /home/postgressql_data_241 -h 192.168.200.241 -p 5432 -U replicator --password
2、数据库目录下,创建/修改 recovery.conf,这个文件可以从pg的安装目录的share文件夹中获取;
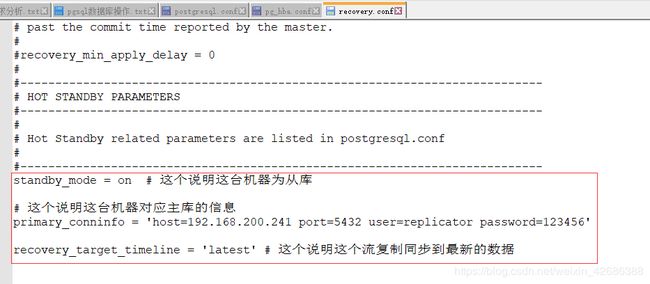
standby_mode = on # 这个说明这台机器为从库
# 这个说明这台机器对应主库的信息
primary_conninfo = 'host=192.168.200.241 port=5432 user=replicator password=123456'
recovery_target_timeline = 'latest' # 这个说明这个流复制同步到最新的数据
3、修改配置文件postgresql.conf,在原配置文件postgresql.conf的基础上修改,修改内容如下
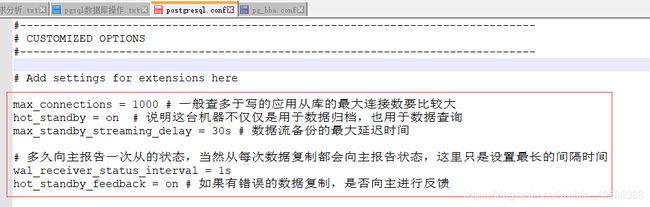
max_connections = 1000 # 一般查多于写的应用从库的最大连接数要比较大
hot_standby = on # 说明这台机器不仅仅是用于数据归档,也用于数据查询
max_standby_streaming_delay = 30s # 数据流备份的最大延迟时间
# 多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,这里只是设置最长的间隔时间
wal_receiver_status_interval = 1s
hot_standby_feedback = on # 如果有错误的数据复制,是否向主进行反馈
4、postgres用户获取从库的权限,启动从库(配置的5433端口):

chown -R postgres:postgres /home/postgressql_data_241/
chmod 0700 /home/postgressql_data_241/
确认结果
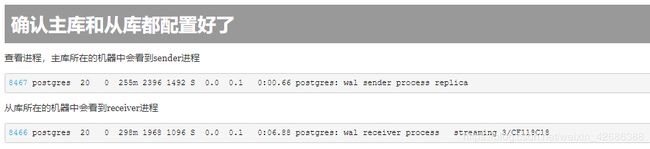
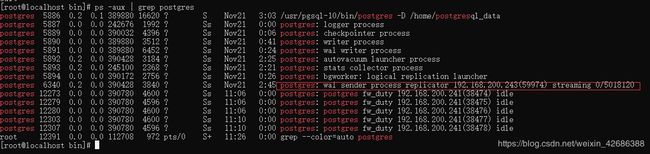


select * from pg_stat_replication;
修改参数 synchronous_standby_names = walreceiver ;重启之后才能转化为 同步模式
同时打开主库跟从库,从主库编辑一条数据,查看数据是否自动同步到从库;
在从库操作数据,查看是否提示只读权限;
参考资料:
https://www.cnblogs.com/yjf512/p/4499547.html
https://www.cnblogs.com/aegis1019/p/8870251.html
https://www.cnblogs.com/chjbbs/p/5833414.html