人体模型若干灵感及想法
关于工作的灵感及想法
一. 姿态估计的相关灵感
1. PoseCNN
3D视觉系列:PoseCNN
https://blog.csdn.net/nwu_NBL/article/details/83176353
2. Learning 3D Human Dynamics from Video
从视频中学习smpl模型参数,并可以用于单幅图像生成当前及前后帧预测模型
https://github.com/akanazawa/human_dynamics
二. 人体模型相关想法及灵感
1. SMPL
SMPL采用姿势与体型训练相分离的方法,用两个数据集求解参数空间。
姿势:事先对FAUST数据集中每个人求解出静止模板和关节位置,对每个扫描(每个人有多个扫描)求解出姿势参数,列出目标函数,将变换模型拟合到数据集扫描中,最小化顶点误差,并采用交替优化的方法求解多个参数。
体型:在对数据集姿态归一化处理后,采用PCA算法得到前十个主成分,同时得到模板
2. 线框人体模型
论文:Parametric design for human body modeling by wireframe-assisted deep learning
1.通过DNN深度网络强大的非线性表达能力将基于语义的参数(身高,胸围,腰围等)关联到线框
2.通过线性回归将线框回归到补丁,即以线框作为界线的部件,再将这些patch进行组装得到最终的人体网格
主要贡献: 特征线框定义为中间层,并将整个人体模型划分为小块。每个贴片的形状变化都小得多,并且PCA可以在贴片中
实现高速降维。利用较低的维度空间,应用深度学习
3. 语义参数重塑
论文:Semantic Parametric Reshaping of Human Body Models
1.建立数据集,模板配准以建立点对点的对应关系
2.一种选择是学习语义参数和PCA系数之间的映射,我们称之为全局映射,局部映射是一种线性回归模型,它直接学习语义参数和形状变形矩阵之间的映射,使用测地线距离来判断刚性部分是否会影响这个三角形表面
3.从SCAPE模型学习姿势和形状变形,改全局映射为局部映射,利用人体拓扑约束,使用线性回归方法来学习语义参数和模型参数之间的线性映射
主要贡献: 我们用一种新的回归模型扩展了该方法,我们将其称为局部映射,以探索详细语义属性的空间。对于每个三角形面,学习语义属性参数与相应形状变化之间的线性映射,并引入映射约束以避免过度拟合问题
三. 从图像或视频估计人体模型论文
1. Monocular Total Capture
论文:Monocular Total Capture: Posing Face, Body, and Hands in the Wild
论文概述:
1.在第一个阶段,将每个图像(身体和手边界框)输入到卷积神经网络(CNN)中,以获得人体部位的联合置信度图和3D方向信息,我们将其称为3D零件方向场(POF),即通过向量计算获得方向。同样手采用类似网络方法
2.第二阶段,我们通过在CNN产生的图像测量值上拟合一个可变形的人体网格模型(Total capture 或 SMPL)来估计整体姿势。我们利用嵌入在人体模型中的先验信息来更好地抵抗CNN输出中的噪声。通过能量函数联系CNN输出,减小拟合误差,拟合项包括2D脸部和脚部关键点(OpenPose)。在此阶段,可以为每帧生成对应的3D模型
3.第三阶段,我们还强制跨帧执行时间一致性以减少运动抖动。我们基于第二阶段的拟合输出定义了一个成本函数,以确保网格模型的纹理域中的光度学一致性。此阶段生成精炼的模型参数。此阶段提取出纹理贴图,以计算跨帧光流
2. Octopus
论文:Learning to Reconstruct People in Clothing from a Single RGB Camera
论文概述:
1.提出一个框架,通过单目RGB相机,让人在相机前以标准姿势旋转,并取其中几帧就能够完全重建人体的方法(包括衣服及发型)。使用自下而上方法(CNN)进行预测,并采用自上而下方法进行微调。学习过程采用合成3D数据。
2.采用SMPL模型,并加上偏移量D,代表衣服及发型等。预测器输入为语义分割图像及2D关节点。损失函数包括逐顶点误差(穿与没穿),投影轮廓重叠误差,关节误差
3. 使用线性回归从顶点回归关节位置
3. SMPL-X and SMPLify-X
论文:Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
论文主要工作:提出了SMPL-X,即SMPL模型的扩展,和SMPLify-X,即smplify方法的改进版
论文概述:
1.SMPL-X由SMPL(body),MANO(hand),FLAME(head)三部分组成,将模型拟合到四个3D人体扫描数据集进行训练
2.SMPLify-X采用类smplify的方法,最小化目标函数,包括先验,距离和互穿惩罚的数据项
3.采用变分自动编码器(VAE)训练身体姿势先验,采用了一系列训练公式
4.使用边界体积层次结构(BVH),得出检测自碰撞和渗透的数据项
5.训练性别分类器,该分类器将包含全身和OpenPose关节的图像作为输入,并为检测到的人分配性别标签
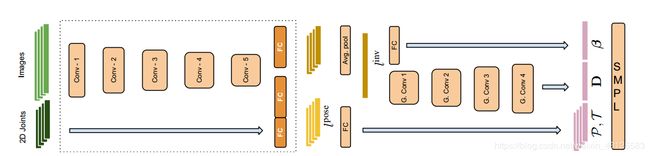
4. Convolutional Mesh Regression
论文:Convolutional Mesh Regression for Single-Image Human Shape Reconstruction
论文主要工作:https://www.jianshu.com/p/32a493d4f482
论文概述:
主要的pipeline为:
给定一张图,用任何一个经典的2D CNN都可以提出到低维的图像特征;
将低纬度的图像特征嵌入到template mesh的各个顶点中;
这样每个顶点都有其坐标位置及对应的feature vector;
通过GCN层来不断迭代进行优化;
最后得到回归后的3D mesh的各个顶点坐标,对应图中的output mesh;
作者:与阳光共进早餐
链接:https://www.jianshu.com/p/32a493d4f482
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。