Pandas中汇总统计、处理缺失值、层次化索引超详细介绍!(附实例)
阅读提示
本文将提到Pandas汇总统计和计算方法、处理缺失值操作、层次化索引等内容
目录
- 阅读提示
- 一、pandas汇总统计和计算
- 1、sum()和cumsum()方法
- 2、idxmax() 方法
- 3、unique() 方法
- 4、value_counts() 方法
- 5、isin() 方法
- 二、pandas处理缺失数据
- 1、过滤缺失数据
- 对于Series
- 对于Dataframe
- 2、对缺失值进行填充
- 三、pandas层次化索引
- 层次化索引
- 1、根据索引选择数据子集
- 2、重排分级顺序
- 根据索引交换: swaplevel()
- 根据索引排序:sort_index()
- 根据级别汇总统计

一、pandas汇总统计和计算
1、sum()和cumsum()方法
#sum()
df = DataFrame(np.array([1.4,np.nan,7.5,-4.5,np.nan,np.nan,0.75,-1.3]).reshape(4,2),index = ['a','b','c','d'],columns = ['one','two'])
'''
df
one two
a 1.40 NaN
b 7.50 -4.5
c NaN NaN
d 0.75 -1.3
'''
df.sum() #默认是竖向汇总
'''
one 9.65
two -5.80
dtype: float64
'''
df.sum(axis = 1)
'''
a 1.40
b 3.00
c 0.00
d -0.55
dtype: float64
'''
#cumsum()
df.cumsum() #累加操作 比如b就是 a+b d是a+b+c
'''
one two
a 1.40 NaN
b 8.90 -4.5
c NaN NaN
d 9.65 -5.8
'''
2、idxmax() 方法
df.idxmax() #获取最大值对应的索引(行索引)
'''
one b
two d
dtype: object
'''
3、unique() 方法
obj = Series(['c','d','a','a','d','b','b','c','c','e'])
'''
obj
0 c
1 d
2 a
3 a
4 d
5 b
6 b
7 c
8 c
9 e
dtype: object
'''
obj.unique() #可以理解为去重 返回数据的唯一值
'''
array(['c', 'd', 'a', 'b', 'e'], dtype=object)
'''
4、value_counts() 方法
obj.value_counts() # 统计各个值出现的频率
'''
c 3
b 2
d 2
a 2
e 1
dtype: int64
'''
5、isin() 方法
obj.isin(['a','b']) #判断某个值是否在里面
'''
0 False
1 False
2 True
3 True
4 False
5 True
6 True
7 False
8 False
9 False
dtype: bool
'''
二、pandas处理缺失数据
1、过滤缺失数据
对于Series
dropna()函数返回一个包含非空数据和索引值的Series
from numpy import nan as NA
data = Series([1,NA,3,4,5])
'''
data
0 1.0
1 NaN
2 3.0
3 4.0
4 5.0
dtype: float64
'''
data.dropna()
'''
0 1.0
2 3.0
3 4.0
4 5.0
dtype: float64
'''
对于Dataframe
dropna()函数也会返回一个包含非空数据和索引值的数据
'''
frame3
name gender age weight
0 jackjack mm 40.0 NaN
1 tom tom mm 38.0 NaN
2 marrymarry ww 60.0 NaN
3 NaN NaN NaN NaN
'''
frame3.dropna()
'''
这样操作后 整个dataframe都空了 因为他会删除所有带nan的行
name gender age weight
'''
frame3.dropna(how='all') #添加 how='all'参数 当一整行都为nan时才会删除
'''
name gender age weight
0 jackjack mm 40.0 NaN
1 tomtom mm 38.0 NaN
2 marrymarry ww 60.0 NaN
'''
frame3.dropna(axis = 1,how = 'all') #可以使用 axis=1 操作来对列进行删除
'''
name gender age
0 jackjack mm 40.0
1 tomtom mm 38.0
2 marrymarry ww 60.0
3 NaN NaN NaN
'''
2、对缺失值进行填充
如果不想丢掉缺失值而是想用默认值来代替:
'''
frame3
name gender age weight
0 jackjack mm 40.0 NaN
1 tomtom mm 38.0 NaN
2 marrymarry ww 60.0 NaN
3 NaN NaN NaN NaN
'''
frame3.fillna(0) #用0填充nan的值,可以是任何值 1,2,3,4....
'''
name gender age weight
0 jackjack mm 40.0 0
1 tomtom mm 38.0 0
2 marrymarry ww 60.0 0
3 0 0 0.0 0
'''
如果不想只以某个标量填充,可以传入一个字典,对不同的列填充不同的值:
frame3.fillna({'name':'hahaha','gender':'mm','age':50.0,'weight':90}) #将name列的空值填充为hahaha
'''
name gender age weight
0 jackjack mm 40.0 90
1 tomtom mm 38.0 90
2 marrymarry ww 60.0 90
3 hahaha mm 50.0 90
'''
三、pandas层次化索引
层次化索引
创建
1、 隐式构造
Series
#最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组,Series也可以创建多层索引。
a = Series(np.random.randint(0,100,size=6),index = [['a','a','b','b','c','c'],['期中','期末','期中','期末','期中','期末']])
'''
a 期中 35
期末 44
b 期中 94
期末 83
c 期中 13
期末 98
dtype: int32
'''
df = DataFrame(a, columns = 'Python')
'''
Python
a 期中 2
期末 36
b 期中 85
期末 92
c 期中 33
期末 41
'''
DataFrame
df1 = DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns=[['python','python','math','math','En','En'],['期中','期末','期中','期末','期中','期末']])
'''
df1
python math En
期中 期末 期中 期末 期中 期末
东 72 37 106 105 88 5
男 132 134 57 26 58 99
息 127 94 60 19 20 25
被 53 27 18 40 59 85
'''
2、隐式构造
使用数组构造
df2 = DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns=[['python','python','math','math','En','En'],['期中','期末','期中','期末','期中','期末']])
使用tuple构造
df3 = DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns =pd.MultiIndex.from_tuples([('python','期中'),('python','期末'), ('math','期中'),('math','期末'),('En','期中'),('En','期末')]))
使用produc构造(★)
df4 = DataFrame(np.random.randint(0,150,size=(8,12)),
columns = pd.MultiIndex.from_product([['模拟考','正式考'],
['数学','语文','英语','物理','化学','生物']]),
index = pd.MultiIndex.from_product([['总成绩'],
['期中','期末'],
['雷军','李斌'],
['测试一','测试二']]))

层次化索引指你能在一个数组上拥有多个索引
1、根据索引选择数据子集
可以直接使用列名称来进行列索引
df4['正式考']

使用行索引需要用**ix(),loc()**等函数
推荐使用loc()
注意:按行查找时,若一级行索引有好几个,不能直接使用二级索引。
eg
df4 = pd.DataFrame(np.random.randint(0,150,size=(8,12)),
columns = pd.MultiIndex.from_product([['模拟考','正式考'],
['数学','语文','英语','物理','化学','生物']]),
index = pd.MultiIndex.from_product([['总成绩'],
['期中','期末'],
['雷军','李斌'],
['测试一','测试二']]))

# 对列进行索引时,直接用 [] 就可以
df4['模拟考']['数学']

data = df4.loc['总成绩','期中',['雷军','李斌'],'测试二']['模拟考','数学']

注: 第一个[]是对行进行索引查询,第二个[]是对列进行索引查询
df4.iloc[:4]

2、重排分级顺序
根据索引交换: swaplevel()
df4.index.names = ['sum_grade', 'type','name','text_style']
df4.columns.names = ['style', 'subject']
df4:

交换type和name列
df4.swaplevel('type','name')

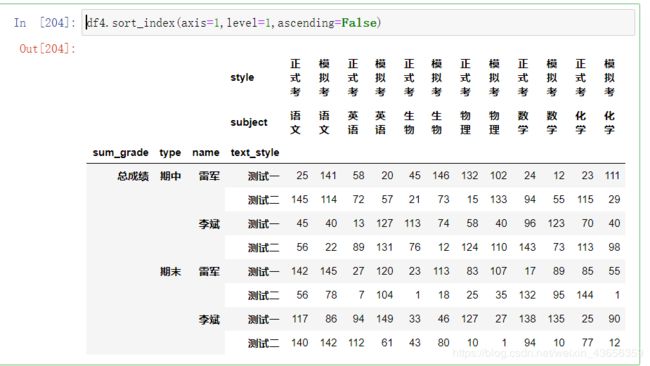
根据索引排序:sort_index()
sort_index()函数根据单个级别的值对数据进行排序,例如:
以行按第一层进行排序:
df4.sort_index(0,ascending=True)

以列按第一层进行排序:
df4.sort_index(axis=1,level=1,ascending=False)
根据级别汇总统计
多层次索引的数据,汇总的时候可以单独按照级别进行
#这里的level是命名后的列名
df4.mean(level='name')

同样的,可以添加axis=1属性按列进行汇总
df4.mean(axis=1,level='style')
