Java8 Stream 集合 过滤 排序 分组 List转Map
Java8 Stream 集合 过滤 排序 分组 Map
- Stream流
- 什么是流
- 准备数据
- 创建流
- 遍历流
- 流只能使用一次
- 过滤
- 查询age>2的数据:
- 查询有效的(valid = true)数据:
- Stream转List
- 排序
- age升序
- age降序
- 根据性别gender升序排,再以年龄age升序
- 根据性别gender升序排,再以年龄age降序
- 根据性别gender降序排,再以年龄age升序
- 根据性别gender降序排,再以年龄age降序
- Limit
- Count
- Map(映射)
- 获取性别的集合,返回List
- 配合distinct获取去重的性别集合
- 配合toSet获取去重的性别集合
- 拼接字符串
- List转Map
Stream流
什么是流
Stream是Java8新增的API,高深的概念理论不去说了,就像把一个数据集合,放到工厂加工流水线的传送带上,经过不同工种工人的加工,到传送带的尽头得到了你想要的数据。它的写法有点像SQL语句,可以让程序员处理集合数据时,更加简短和明了。
准备数据
public class JavaLambdaTest {
private static List<Pig> pigList = new ArrayList<>();
public static void main(String[] args) {
pigList.add(new Pig(1, "猪爸爸", 27, "M", false));
pigList.add(new Pig(2, "猪妈妈", 28, "F", true));
pigList.add(new Pig(3, "乔治", 2, "M", false));
pigList.add(new Pig(4, "佩奇", 5, "F", false));
}
@Data
@AllArgsConstructor
class Pig {
private int id;
private String name;
private Integer age;
private String gender;
private boolean valid;
}
创建流
Stream<Pig> pigStream = pigList.stream();
遍历流
pigStream.forEach(pig -> System.out.println(pig));
Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)
Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)
Pig(id=3, name=乔治, age=2, gender=M, valid=false)
Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
流只能使用一次
一个流创建好后,只能使用一次,如果需要再次使用,需要从源数据集合再次创建
#第一句可执行
pigStream.forEach(pig -> System.out.println(pig));
#第二句会报错 stream has already been operated upon or closed
pigStream.forEach(pig -> System.out.println(pig));
过滤
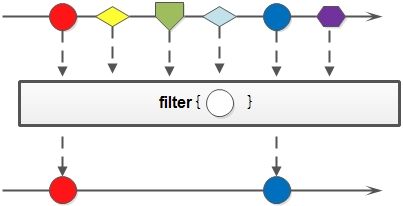
查询age>2的数据:
Stream<Pig> pigStream1 = pigList.stream().filter(pig -> pig.getAge() > 2);
这里的filter方法接收的是Predicate predicate,这个返回boolean类型。
查询有效的(valid = true)数据:
Stream<Pig> pigStream2 = pigList.stream().filter(Pig::isValid);
上面语句Pig::isValid,是行为参数化,isValid是Pig的boolean方法。
Stream转List
上面也说了Stream只能使用一次,加上.collect(toList())后转成List,可继续使用过滤后的数据了
import static java.util.stream.Collectors.toList;
List<Pig> pigList1 = pigList.stream().filter(pig -> pig.getAge() > 2).collect(toList());
排序
想想Java8之前的集合排序多拗口,现在Java8写排序,所写即所想,非常明了
age升序
import static java.util.Comparator.comparing;
pigList.sort(comparing(Pig::getAge));
age降序
pigList.sort(comparing(Pig::getAge).reversed());
根据性别gender升序排,再以年龄age升序
pigList.sort(comparing(Pig::getGender).thenComparing(Pig::getAge));
===Comparator 根据性别升序排,再以年龄升序 ===
Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)
Pig(id=3, name=乔治, age=2, gender=M, valid=false)
Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)
根据性别gender升序排,再以年龄age降序
pigList.sort(comparing(Pig::getGender).thenComparing(comparing(Pig::getAge).reversed()));
===Comparator 根据性别gender升序排,再以年龄age降序 ===
Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)
Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)
Pig(id=3, name=乔治, age=2, gender=M, valid=false)
这个很重要,不能写错,下面是错误的的写法
#错误的写法,这个reversed()会将之前的排序再反转
pigList.sort(comparing(Pig::getGender).thenComparing(Pig::getAge).reversed());
根据性别gender降序排,再以年龄age升序
pigList.sort(comparing(Pig::getGender).reversed().thenComparing(Pig::getAge));
===Comparator 根据性别gender降序排,再以年龄age升序 ===
Pig(id=3, name=乔治, age=2, gender=M, valid=false)
Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)
Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)
根据性别gender降序排,再以年龄age降序
pigList.sort(comparing(Pig::getGender).thenComparing(Pig::getAge).reversed());
===Comparator 根据性别gender降序排,再以年龄age降序 ===
Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)
Pig(id=3, name=乔治, age=2, gender=M, valid=false)
Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)
Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
Limit
通常排序后,希望获取前面几个数据,可以使用Limit
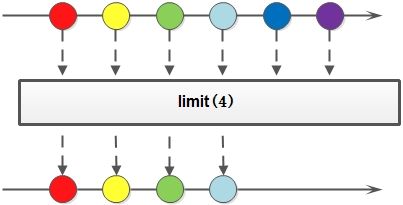
pigList.sort(comparing(Pig::getAge));
Stream<Pig> topPigs = pigList.stream().limit(2);
topPigs.forEach(a -> System.out.println(a));
Count
获取Stream的元素个数
Long count = pigList.stream().filter(a -> a.getAge() > 10).count();
Map(映射)
对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。
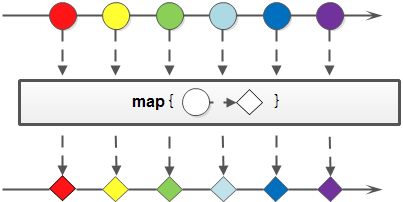
获取性别的集合,返回List
List<String> genderList = pigList.stream().map(Pig::getGender).collect(toList());
M
F
M
F
配合distinct获取去重的性别集合
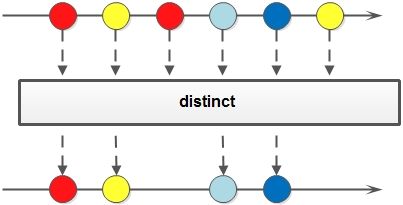
List<String> genderList2 = pigList.stream().map(Pig::getGender).distinct().collect(toList());
===distinct()===
M
F
配合toSet获取去重的性别集合
Set<String> genderSet = pigList.stream().map(Pig::getGender).collect(toSet());
===toSet()===
F
M
拼接字符串
String字符串在java中是不可变的,如果在for循环里用+拼接字符串,会生成很多字符串。 joining在内部使用了StringBuilder来把生成的字符串逐个追加起来。
String names = pigList.stream().map(Pig::getName).collect(joining(","));
System.out.println(names);
List转Map
把id作为key,pig对象作为value存储
Map<Integer, Pig> mapById = pigList.stream().collect(Collectors.toMap(Pig::getId, a -> a, (k1, k2) -> k1));
mapById.forEach((key, value) -> System.out.println(key + " -> " + value.toString()));
=== List转Map<Integer, Object>===
1 -> Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)
2 -> Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)
3 -> Pig(id=3, name=乔治, age=2, gender=M, valid=false)
4 -> Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
List转Map
上面id是唯一的,如果按照性别呢?
如果gender重复就用第一个
Map<String, Pig> mapByGender = pigList.stream().collect(Collectors.toMap(Pig::getGender, a -> a, (k1, k2) -> k1));
mapByGender.forEach((key, value) -> System.out.println(key + " -> " + value.toString()));
=== List转Map<String, Object>===
F -> Pig(id=4, name=佩奇, age=5, gender=F, valid=false)
M -> Pig(id=3, name=乔治, age=2, gender=M, valid=false)
List转Map,用分组(groupingBy)
这个分组功能在工作中非常常用
Map<String, List<Pig>> groupByGender = pigList.stream().collect(groupingBy(Pig::getGender));
groupByGender.forEach((key, value) -> System.out.println(key + " -> " + value.toString()));
=== List转Map<String, List<Object>>===
F -> [Pig(id=4, name=佩奇, age=5, gender=F, valid=false), Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)]
M -> [Pig(id=3, name=乔治, age=2, gender=M, valid=false), Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)]
分区(partitioningBy)
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函
数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,于是它最多可以
分为两组——true是一组,false是一组。
Map<Boolean, List<Pig>> partitioningByGender = pigList.stream().collect(partitioningBy(Pig::isValid));
partitioningByGender.forEach((key, value) -> System.out.println(key + " -> " + value.toString()));
=== partitioningByGender===
false -> [Pig(id=3, name=乔治, age=2, gender=M, valid=false), Pig(id=4, name=佩奇, age=5, gender=F, valid=false), Pig(id=1, name=猪爸爸, age=27, gender=M, valid=false)]
true -> [Pig(id=2, name=猪妈妈, age=28, gender=F, valid=true)]
如果本文对您有帮助,就点个赞吧