java爬虫工具Jsoup学习
目录
前言
一、基本使用
二、爬取豆瓣电影的案例
三、Jsoup能做什么?
四、Jsoup相关概念
五、Jsoup获取文档
六、定位选择元素
七、获取数据
八、具体案例
前言
JSoup是一个用于处理HTML的Java库,它提供了一个非常方便类似于使用DOM,CSS和jquery的方法的API来提取和操作数据。
一、基本使用
org.jsoup
jsoup
1.13.1
二、爬取豆瓣电影的案例
public class DouBan {
public static void main(String[] args) {
String url = "https://movie.douban.com/top250";
crawlMovies(url);
}
/**
* 爬取的方法
* @param url
* @return
*/
public static void crawlMovies(String url) {
try {
Document doc = Jsoup.connect(url).get(); //模拟浏览器向服务器发起get请求
Elements elements = doc.select("#content > div > div.article > ol > li");
// System.out.println(elements);
for (Element element : elements) {
String rank = element.select("div.pic > em").text();
String name = element.select("div.info > div.hd > a > span:nth-child(1)").text();
String score = element.select("div.info > div.bd > div.star > span.rating_num").text();
System.out.println(rank + " " + name + " " + score);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、Jsoup能做什么?
- 从 URL、文件或字符串中抓取和解析HTML(爬虫)
- 使用DOM 遍历或 CSS 选择器查找和提取数据
- 操作HTML 元素、属性和文本
- 根据安全列表清理用户提交的内容,以防止XSS攻击
- 输出整洁的网页
四、Jsoup相关概念
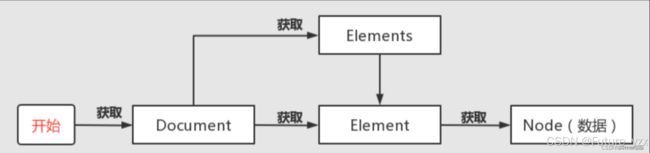
- Document :文档对象。每份HTML页面都是一个文档对象,Document 是 jsoup 体系中最顶层的结构。
- Element:元素对象。一个 Document 中可以着包含着多个 Element 对象,可以使用 Element 对象来遍历节点提取数据或者直接操作HTML。
- Elements:元素对象集合,类似于List。
- Node:节点对象。标签名称、属性等都是节点对象,节点对象用来存储数据。
- 类继承关系:Document 继承自 Element(class Document extends Element) ,Element 继承自 Node(class Element extends Node)。
- 一般执行流程:先获取 Document 对象,然后获取 Element 对象,最后再通过 Node 对象获取数据。
五、Jsoup获取文档
1.导入jsoup的jar包
org.jsoup
jsoup
1.11.3
2.从URL中加载文档对象(常用)
使用 Jsoup.connect(String url).get()方法获取(只支持 http 和 https 协议)
try {
Document document = Jsoup.connect("http://www.baidu.com").get();
System.out.println(document);
} catch (IOException e) {
throw new RuntimeException(e);
}
connect(String url)方法创建一个新的 Connection并通过.get()或者.post()方法获得数据。如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理。
3.设置请求头,模拟浏览器访问服务器
public class ParseUtils {
public static final String url ="https://www.zhaopin.com/sou/jl530/kw01L00O80EO062/p2";
public static void main(String[] args) throws IOException {
Document scriptHtml = Jsoup.connect(url)
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")
.header("Accept-Encoding", "gzip, deflate, br, zstd")
.header("Accept-Language", "zh-CN,zh;q=0.9")//,en-US;q=0.5,en;q=0.3
.header("Cache-Control","max-age=0")
.header("Cookie", "x-zp-client-id=ef9626f5-a52b-4a15-8a12-b0a85e7c218d;")
.header("Priority", "u=0, i")
.header("Sec-Ch-Ua","\"Not/A)Brand\";v=\"8\", \"Chromium\";v=\"126\", \"Google Chrome\";v=\"126\"")
.header("Sec-Ch-Ua-Mobile","?0")
.header("Sec-Ch-Ua-Platform","\"Windows\"")
.header("Sec-Fetch-Dest","document")
.header("Sec-Fetch-Mode","navigate")
.header("Sec-Fetch-Site","same-origin")
.header("Sec-Fetch-User","?1")
.header("Upgrade-Insecure-Requests","1")
.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36")
.timeout(50000)
.get();
System.out.println(scriptHtml);
}
}六、定位选择元素
我们可以利用dom结构的方式,通过标签,id,class等查找到下属元素
1.查找元素-下列方法返回的是Element或Elements
- getElementById(String id):通过id来查找元素
- getElementsByTag(String tag):通过标签来查找元素
- getElementsByClass(String className):通过类选择器来查找元素
- getElementsByAttribute(String key) :通过属性名称来查找元素,例如查找带有href元素的标签。
- siblingElements():获取兄弟元素。如果元素没有兄弟元素,则返回一个空列表。
- firstElementSibling():获取第一个兄弟元素。
- lastElementSibling():获取最后一个兄弟元素。
- nextElementSibling():获取下一个兄弟元素。
- previousElementSibling():获取上一个兄弟元素。
- parent():获取此节点的父节点。
- children():获取此节点的所有子节点。
- child(int index):获取此节点的指定子节点。
2.select(String selector)-下列方法返回的是Element或Elements
- tagname: 通过标签查找元素,例如通过"a"来查找< a >标签。
- #id: 通过ID查找元素,比如通过#logo查找< p id=“logo”>
- .class: 通过class名称查找元素,比如通过.titile查找< p class=“titile”>
- ns|tag: 通过标签在命名空间查找元素,比如使用 fb|name 来查找 < fb:name>
- [attribute]: 利用属性查找元素,比如通过[href]查找< a href=“…”>
- [ ^attribute]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 dataset属性的元素
- [ attribute=value]: 利用属性值来查找元素,比如:[ width=500]
- [attribute^=value], [attribute$=value], [attribute*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如通过[href*=/path/]来查找
- [attribute~=regex]: 利用属性值匹配正则表达式来查找元素,比如通过 img[src~=(?i).(png|jpe?g)]来匹配所有的png或者jpg、jpeg格式的图片
- *: 通配符,匹配所有元素
七、获取数据
attr(String key):获取单个属性值
attributes():获取所有属性值
attr(String key, String value):设置属性值
text():获取文本内容
text(String value):设置文本内容
html():获取元素内的HTML内容
html(String value):设置元素内的HTML内容
outerHtml():获取元素外HTML内容
data():获取数据内容(例如:script和style标签)
id():获得id值
className():获得第一个类选择器值
classNames():获得所有的类选择器值
tag():获取元素标签
tagName():获取元素标签名
八、具体案例
爬取智联招聘网站
public class ParseUtils {
public static final String url ="https://www.zhaopin.com/sou/jl530/kw01L00O80EO062/p1";
public static void main(String[] args) throws IOException {
Document scriptHtml = Jsoup.connect(url)
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")
.header("Accept-Encoding", "gzip, deflate, br, zstd")
.header("Accept-Language", "zh-CN,zh;q=0.9")//,en-US;q=0.5,en;q=0.3
.header("Cache-Control","max-age=0")
.header("Cookie", "x-zp-client-id=ef9626f5-a52b-4a15-8a12-b0a85e7c218d;")
.header("Priority", "u=0, i")
.header("Sec-Ch-Ua","\"Not/A)Brand\";v=\"8\", \"Chromium\";v=\"126\", \"Google Chrome\";v=\"126\"")
.header("Sec-Ch-Ua-Mobile","?0")
.header("Sec-Ch-Ua-Platform","\"Windows\"")
.header("Sec-Fetch-Dest","document")
.header("Sec-Fetch-Mode","navigate")
.header("Sec-Fetch-Site","same-origin")
.header("Sec-Fetch-User","?1")
.header("Upgrade-Insecure-Requests","1")
.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36")
.timeout(50000)
.get();
// System.out.println(scriptHtml);
Elements content = scriptHtml.getElementsByClass("joblist-box__item");
for(Element element:content){
String price = element.getElementsByClass("jobinfo__salary").text();
String company = element.getElementsByClass("companyinfo__name").text();
System.out.println(price+" " + company);
}
}
}