JAVA基础---集合(一)--集合框架概述
为什么用集合如何合理用集合,以及如何实现的和他们的实现原理,如果搞清了对于之后学习其他知识和开发是很有大帮助性的。
什么是集合框架?
集合框架是表示和操作集合的统一体系结构。所有集合框架都包含以下内容:
- 接口:这些是表示集合的抽象数据类型。接口允许独立于集合表示的细节来操作集合。在面向对象的语言中,接口通常形成层次结构。
- 实现:这些是集合接口的具体实现。本质上,它们是可重用的数据结构。
- 算法:这些方法对实现集合接口的对象执行有用的计算,比如搜索和排序。这些算法被认为是多态的:也就是说,相同的方法可以用于适当集合接口的许多不同实现。从本质上讲,算法是可重用的功能。
- 除了Java Collections框架之外,最著名的collection框架示例是c++标准模板库(STL)和Smalltalk的集合层次结构。从历史上看,集合框架一直非常复杂,这使它们以具有陡峭的学习曲线而闻名。Java集合框架打破了这一传统。
Java Collections框架提供了以下好处:
- 减少编程工作:通过提供有用的数据结构和算法,Collections框架使您可以将精力集中于程序的重要部分,而不是使其工作所需的底层“管道”。通过促进不相关api之间的互操作性,Java Collections框架使您不必编写适配器对象或转换代码来连接api。
- 提高程序速度和质量:这个集合框架提供了有用的数据结构和算法的高性能、高质量的实现。每个接口的各种实现都是可互换的,因此可以通过切换集合实现轻松地调优程序。因为您从编写自己的数据结构的苦差事中解脱出来,您将有更多的时间用于提高程序的质量和性能。
- 允许不相关api之间的互操作性:集合接口是api来回传递集合的本地语言。如果我的网络管理API提供了一组节点名,如果您的GUI工具包希望有一组列标题,那么我们的API将无缝地互操作,即使它们是独立编写的。
- 减少学习和使用新api的工作量:许多api自然地接受输入集合并将其作为输出提供。在过去,每个这样的API都有一个用于操作其集合的子API。这些特别的集合子api之间几乎没有一致性,所以您必须从头开始学习它们,并且在使用它们时很容易出错。随着标准集合接口的出现,问题消失了。
- 减少设计新api的工作:这是以前优势的另一面。设计人员和实现人员不必每次创建依赖于集合的API时都要重新发明轮子;相反,它们可以使用标准的集合接口。促进软件重用:符合标准集合接口的新数据结构本质上是可重用的。对实现这些接口的对象进行操作的新算法也是如此。
接口
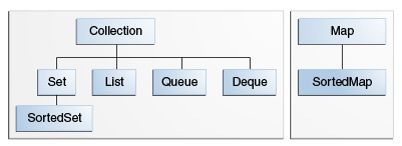
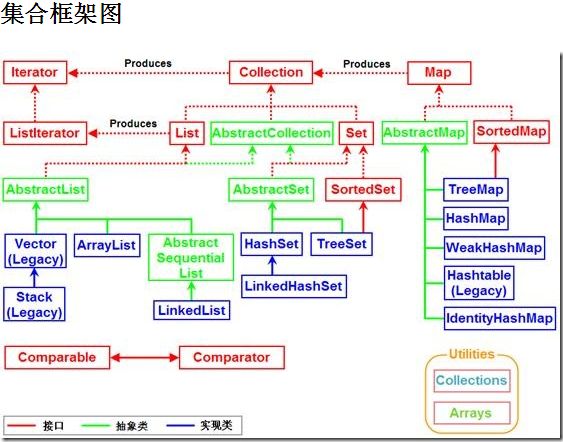
核心的集合接口封装了不同集合的类型,如下图所示:这些接口允许集合独立于他们表现的细节来操作。核心集合接口是Java集合框架的基础。从下图中可以看到,核心集合接口形成了一个层次结构。
集合是一种特殊的集合,SortedSet是一种特殊的集合,等等。还要注意,层次结构由两棵不同的树组成——Map不是一个真正的集合。
注意,所有核心集合接口都是通用的。例如,这是集合接口的声明
public interface Collection...
语法告诉您该接口是通用的。声明集合实例时,可以且应该指定集合中包含的对象的类型。指定类型允许编译器验证(在编译时)放入集合的对象类型是否正确,从而在运行时减少错误。
当您了解如何使用这些接口时,您将了解关于Java集合框架的大部分内容。本章讨论有效使用接口的一般准则,包括何时使用哪个接口。您还将学习每个接口的编程习惯,以帮助您最大限度地利用它。
为了保持核心集合接口的数量是可管理的,Java平台没有为每种集合类型的每个变体提供单独的接口。(这些变体可能包括不可变的、固定大小的和仅追加的。)相反,每个接口中的修改操作被指定为可选的,给定的实现可以选择不支持所有操作。如果调用不支持的操作,集合将抛出不支持的operationexception。实现负责记录它们支持哪些可选操作。Java平台的所有通用实现都支持所有可选操作
核心接口解释如下:
- Collection——集合层次结构的根。集合表示一组称为其元素的对象。集合接口是所有集合实现的最小公分母,用于在需要最大通用性时传递集合并操作它们。有些类型的集合允许重复元素,有些则不允许。有些是有序的,有些是无序的。Java平台不提供该接口的任何直接实现,而是提供了更具体的子接口的实现,比如Set和List。集合——集合层次结构的根。集合表示一组称为其元素的对象。集合接口是所有集合实现的最小公分母,用于在需要最大通用性时传递集合并操作它们。有些类型的集合允许重复元素,有些则不允许。有些是有序的,有些是无序的。Java平台不提供该接口的任何直接实现,而是提供了更具体的子接口的实现,比如Set和List。
- Set——不能包含重复元素的集合。该接口对数学集抽象进行建模,并用于表示集,例如由扑克手组成的纸牌、构成学生时间表的课程或机器上运行的进程。
- List——有序的集合(有时称为序列)。列表可以包含重复的元素。列表的用户通常可以精确控制列表中每个元素的插入位置,并可以通过它们的整数索引(位置)访问元素。与Vector类似
- Queue ——用于在处理之前保存多个元素的集合。除了基本的收集操作外,队列还提供额外的插入、提取和检查操作. 队列通常(但不一定)以先进先出(first-in, first-out)的方式对元素排序。例外情况包括优先队列,优先队列根据提供的比较器或元素的自然顺序对元素排序。无论使用什么顺序,队列的头部都是将通过调用remove或poll删除的元素。在FIFO队列中,所有新元素都插入到队列的尾部。其他类型的队列可能使用不同的放置规则。每个队列实现都必须指定其排序属性
- Deque—用于在处理之前保存多个元素的集合。除了基本的收集操作,Deque还提供附加的插入、提取和检查操作。Deques可以同时使用FIFO(先进先出)和LIFO(后进先出)。在deque中,所有新元素都可以在两端插入、检索和删除。
- Map — 将键映射到值的对象。Map 不能包含重复的键;每个键最多可以映射到一个值。如果您使用过Hashtable,那么您已经熟悉了Map的基本知识
最后两个核心集合接口仅仅是Set和Ma的排序版本- SortedSet —一组按升序保持其元素的集合。还提供了几个额外的操作来利用排序。排序集用于自然排序集,如单词列表和成员名册
- SortedMap —按升序键顺序维护其映射的映射的映射。这是SortedSet的地图模拟。排序映射用于键/值对的自然有序集合,如字典和电话簿。
Collection接口:
集合表示一组称为其元素的对象。Collection接口用于在需要最大通用性的地方传递对象集合。例如,按照惯例,所有通用集合实现都有一个构造函数,该构造函数接受集合参数。这个构造函数称为转换构造函数,它初始化新集合以包含指定集合中的所有元素,无论给定集合的子接口或实现类型是什么。换句话说,它允许您转换集合的类型
例如,假设您有一个集合 c,它可能是一个列表、一个集合或另一种集合。这个习惯用法创建一个新的ArrayList (List接口的实现),最初包含c语言中的所有元素
List list = new ArrayList(c);
或者——如果你使用JDK 7或更高版本——你可以使用菱形操作符:
List list = new ArrayList<>(c);
集合接口包含执行基本操作的方法,如int size()、boolean isEmpty()、boolean contains(对象元素)、boolean add(E元素)、boolean remove(对象元素)和Iterator Iterator()。
它还包含操作整个集合的方法,比如boolean containsAll(Collection c), boolean removeAll(Collection T[] toArray(T[] a
- 在JDK 8及更高版本中,Collection接口还公开了Stream Stream()和Stream parallelStream()方法,用于从底层集合获取顺序流或并行流。(有关使用流的更多信息,请参阅“聚合操作”一课
- 如果集合表示一组对象,则集合接口执行您所期望的操作。它的方法告诉您集合中有多少元素(size, isEmpty),检查给定对象是否在集合中(contains)的方法,从集合中添加和删除元素的方法(add, remove),以及在集合上提供迭代器的方法(iterator)。
- add方法通常定义得足够多,因此它对于允许复制和不允许复制的集合都是有意义的。它保证集合将在调用完成后包含指定的元素,如果集合由于调用而发生更改,则返回true。类似地,remove方法的设计目的是从集合中删除指定元素的单个实例(假设它包含开始时的元素),如果结果修改了集合,则返回true
- 遍历集合
有三种方法可以遍历集合:
(1)使用聚合操作(参考这里)
(2)for-each构造
(3)使用迭代器
在JDK 8及更高版本中,遍历集合的首选方法是获取一个流并对其执行聚合操作。聚合操作通常与lambda表达式一起使用,以使用更少的代码行使编程更具表现力。下面的代码依次遍历形状集合并打印出红色对象
myShapesCollection.stream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
同样,可以轻松地请求一个并行流,如果集合足够大并且计算机有足够多的内核,这可能是非常有帮助。
myShapesCollection.parallelStream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
使用这个API收集数据有许多不同的方法。例如,您可能希望将集合的元素转换为String对象,然后用逗号将它们连接起来
String joined = elements.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
或者把所有员工的工资加起来
int total = employees.stream()
.collect(Collectors.summingInt(Employee::getSalary)));
集合框架总是提供一些所谓的“批量操作”作为其API的一部分。这些方法包括操作整个集合的方法,如containsAll、addAll、removeAll等。不要将这些方法与JDK 8中引入的聚合操作混淆。新的聚合操作与现有的批量操作(containsAll、addAll等)之间的关键区别在于,旧版本都是可变的,这意味着它们都修改底层集合。相反,新的聚合操作不修改底层集合。当使用新的聚合操作和lambda表达式时,您必须注意避免发生突变,以免将来出现问题,如果您的代码稍后在并行流中运行的话。
Set接口:
Set是不能包含重复元素的集合。它对数学集合抽象建模。Set接口只包含从集合继承的方法,并添加了禁止复制元素的限制。Set还为equals和hashCode操作的行为添加了一个更强的契约,允许对Set实例进行有意义的比较,即使它们的实现类型不同。如果两个集合实例包含相同的元素,则它们是相等的
Java平台包含三个通用的Set实现:HashSet、TreeSet和LinkedHashSet。将其元素存储在哈希表中的HashSet是性能最好的实现;然而,它不能保证迭代的顺序。TreeSet将元素存储在红黑树中,根据元素的值对元素进行排序;它比HashSet慢很多。LinkedHashSet实现为一个哈希表,其中运行一个链表,它根据元素插入集合的顺序(插入顺序)对元素排序。LinkedHashSet将其客户端从HashSet提供的未指定的、通常混乱的顺序中解脱出来,其代价仅略高一些。
假设您有一个集合c,您想要创建另一个集合,其中包含相同的元素,但是要消除所有重复。下面的一行代码就可以做到这一点。
Collection noDups = new HashSet(c);
或者,如果使用JDK 8或更高版本,您可以使用聚合操作轻松地收集到一个集合:
c.stream()
.collect(Collectors.toSet()); // no duplicates
或者这样写
Set set = people.stream()
.map(Person::getName)
.collect(Collectors.toCollection(TreeSet::new));
如何保留了原始集合的顺序,同时删除了重复的元素:
Collection noDups = new LinkedHashSet(c);
下面是封装前一种习惯用法的泛型方法,返回与传递的泛型类型相同的一组泛型类型
public static Set removeDups(Collection c) {
return new LinkedHashSet(c);
}
- Set接口基本操作
import java.util.*;
import java.util.stream.*;
public class FindDups {
public static void main(String[] args) {
Set distinctWords = Arrays.asList(args).stream()
.collect(Collectors.toSet());
System.out.println(distinctWords.size()+
" distinct words: " +
distinctWords);
}
}
使用for-each的例子
import java.util.*;
public class FindDups {
public static void main(String[] args) {
Set s = new HashSet();
for (String a : args)
s.add(a);
System.out.println(s.size() + " distinct words: " + s);
}
}
List接口
- 位置访问——根据元素在列表中的数值位置操作元素。这包括get、set、add、addAll和remove等方法。
- 搜索——搜索列表中指定的对象并返回其数值位置。搜索方法包括indexOf和lastIndexOf。
- 迭代——扩展迭代器语义,利用列表的顺序特性。listIterator方法提供了这种行为。
- 范围视图——子列表方法对列表执行任意范围操作。
Java平台包含两个通用列表实现。ArrayList通常是性能更好的实现,LinkedList在某些情况下提供更好的性能
- 集合操作:
list1.addAll(list2);
下面的也没有破坏语法,它生成第三个列表,其中第二个列表附加到第一个列表。
List list3 = new ArrayList(list1);
list3.addAll(list2);
jdk8+,可以使用聚合操作
List list = people.stream()
.map(Person::getName)
.collect(Collectors.toList());
- 位置访问和搜索操作
基本的位置访问操作是get/set/add/remove。这个set和remove操作返回被重写或移除的原值(old value).其他indexOf,lastIndexOf返回当前数组里面指定位置的值
交换索引的小方法
public static void swap(List a, int i, int j) {
E tmp = a.get(i);
a.set(i, a.get(j));
a.set(j, tmp);
}
这是一种多态算法:它在任何列表中交换两个元素,无论其实现类型如何。下面是另一个多态算法,它使用前面的swap方法
public static void shuffle(List list, Random rnd) {
for (int i = list.size(); i > 1; i--)
swap(list, i - 1, rnd.nextInt(i));
}
该算法包含在Java平台的Collections类中,使用指定的随机性源随机遍历指定列表。
它从底部向上运行列表,反复将随机选择的元素交换到当前位置。与大多数简单的洗牌尝试不同,它是公平的(假设随机的无偏来源,所有排列发生的可能性都是相同的),并
且速度快(需要list.size()-1互换)。
下面的程序使用这个算法按随机顺序打印参数列表中的单词
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List list = new ArrayList();
for (String a : args)
list.add(a);
Collections.shuffle(list, new Random());
System.out.println(list);
}
}
数组类有一个名为asList的静态工厂方法,它允许将数组视为列表。
此方法不复制数组。列表中的更改写入数组,反之亦然。
结果列表不是一个通用的列表实现,因为它没有实现(可选的)添加和删除操作:数组是不可调整大小的。
利用数组。asList和调用shuffle的库版本(它使用默认的随机性源),
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List list = Arrays.asList(args);
Collections.shuffle(list);
System.out.println(list);
}
}
- 迭代器
主要包含了 hasNext, next,和remove
下面是向后遍历列表的标准习惯用法
for (ListIterator it = list.listIterator(list.size()); it.hasPrevious(); ) {
Type t = it.previous();
...
}
注意前面习语中listIterator的参数。List接口有两种形式的listIterator方法。没有参数的表单返回位于列表开头的ListIterator;带有int参数的表单返回位于指定索引处的ListIterator。索引引用将由对next的初始调用返回的元素。对previous的初始调用将返回索引为index-1的元素。在长度为n的列表中,索引有n+1个有效值,范围从0到n
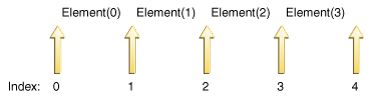
直观地说,游标总是在两个元素之间——一个元素将由对previous的调用返回,另一个元素将由对next的调用返回。n+1有效索引值对应于元素之间的n+1个间隙,从第一个元素之前的间隙到最后一个元素之后的间隙。下图显示了包含四个元素的列表中的五个可能的光标位置
对next和previous的调用可以混合使用,但是必须小心一点。对previous的第一个调用返回与对next的最后一个调用相同的元素。类似地,在对previous进行一系列调用之后,对next的第一个调用与对previous的最后一个调用返回相同的元素
获取下标的实现
public int indexOf(E e) {
for (ListIterator it = listIterator(); it.hasNext(); )
if (e == null ? it.next() == null : e.equals(it.next()))
return it.previousIndex();
// Element not found
return -1;
}
修改元素
public static void replace(List list, E val, E newVal) {
for (ListIterator it = list.listIterator(); it.hasNext(); )
if (val == null ? it.next() == null : val.equals(it.next()))
it.set(newVal);
}
移除添加元素
public static
void replace(List list, E val, List newVals) {
for (ListIterator it = list.listIterator(); it.hasNext(); ){
if (val == null ? it.next() == null : val.equals(it.next())) {
it.remove();
for (E e : newVals)
it.add(e);
}
}
}
- 范围视图操作
范围视图操作subblist (int fromIndex, int toIndex)返回列表中索引范围从包含的fromIndex到排除的toIndex的部分的列表视图。这个半开的范围反映了典型的for循环
for (int i = fromIndex; i < toIndex; i++) {
...
}
从列表中删除一系列元素
list.subList(fromIndex, toIndex).clear();
可以构造类似的习惯用法来搜索范围中的元素
int i = list.subList(fromIndex, toIndex).indexOf(o);
int j = list.subList(fromIndex, toIndex).lastIndexOf(o);
ArrayList,从列表末尾删除元素的性能要比从列表开始删除元素的性能好得多。
public static List dealHand(List deck, int n) {
int deckSize = deck.size();
List handView = deck.subList(deckSize - n, deckSize);
List hand = new ArrayList(handView);
handView.clear();
return hand;
}
如下简单例子移除某些元素
import java.util.*;
public class Deal {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println("Usage: Deal hands cards");
return;
}
int numHands = Integer.parseInt(args[0]);
int cardsPerHand = Integer.parseInt(args[1]);
// Make a normal 52-card deck.
String[] suit = new String[] {
"spades", "hearts",
"diamonds", "clubs"
};
String[] rank = new String[] {
"ace", "2", "3", "4",
"5", "6", "7", "8", "9", "10",
"jack", "queen", "king"
};
List deck = new ArrayList();
for (int i = 0; i < suit.length; i++)
for (int j = 0; j < rank.length; j++)
deck.add(rank[j] + " of " + suit[i]);
// Shuffle the deck.
Collections.shuffle(deck);
if (numHands * cardsPerHand > deck.size()) {
System.out.println("Not enough cards.");
return;
}
for (int i = 0; i < numHands; i++)
System.out.println(dealHand(deck, cardsPerHand));
}
public static List dealHand(List deck, int n) {
int deckSize = deck.size();
List handView = deck.subList(deckSize - n, deckSize);
List hand = new ArrayList(handView);
handView.clear();
return hand;
}
}
运行结果:
% java Deal 4 5
[8 of hearts, jack of spades, 3 of spades, 4 of spades,
king of diamonds]
[4 of diamonds, ace of clubs, 6 of clubs, jack of hearts,
queen of hearts]
[7 of spades, 5 of spades, 2 of diamonds, queen of diamonds,
9 of clubs]
[8 of spades, 6 of diamonds, ace of spades, 3 of hearts,
ace of hearts]
- List算法
- sort—使用合并排序算法对列表进行排序,该算法提供了一种快速、稳定的排序。(一个稳定的排序是不重新排序相等的元素。)
- shuffle —随机打乱列表中的元素
- reverse —反转列表中元素的顺序
- rotate — 将列表中的所有元素旋转指定的距离
- swap —交换列表中指定位置的元素
- replaceAll — 将一个指定值的所有匹配项替换为另一个指定值。
- fill —用指定的值覆盖列表中的每个元素。
- copy —将源列表复制到目标列表中。
- binarySearch —使用二进制搜索算法搜索有序列表中的元素
- indexOfSubList — 返回一个列表中与另一个列表相等的第一个子列表的索引。
- [ ]lastIndexOfSubList —返回一个列表的最后一个子列表的索引
队列接口
队列是用于在处理之前保存元素的集合。除了基本的收集操作之外,队列还提供额外的插入、删除和检查操作
public interface Queue extends Collection {
E element();
boolean offer(E e);
E peek();
E poll();
E remove();
}
每个队列方法都以两种形式存在:(1)如果操作失败,一个抛出异常;(2)如果操作失败,另一个返回一个特殊值(null或false,取决于操作)。接口的规则结构如下表所示。
在FIFO队列中,所有新元素都插入到队列的尾部。其他类型的队列可能使用不同的放置规则。每个队列实现都必须指定其排序属性
队列实现可以限制它所持有的元素的数量;这样的队列称为有界队列。juc中的一些队列实现。并发是有界的,但实现是用java.util中不是。
队列实现通常不允许插入空元素。LinkedList实现是一个例外,它经过了改造以实现Queue。由于历史原因,它允许空元素,但是您应该避免使用它,因为null被poll和peek方法用作特殊的返回值
队列实现通常不定义equals和hashCode方法的基于元素的版本,而是从对象继承基于标识的版本。
队列接口不定义阻塞队列方法,这在并发编程中很常见。这些方法在接口java.util.concurrent中定义,它们等待元素出现或空间可用。BlockingQueue,它扩展队列。
在下面的示例程序中,使用队列实现倒计时计时器。队列预先加载了从命令行指定的数字到0的所有整数值,按降序排列。然后,从队列中删除这些值,并每隔一秒打印一次。这个程序是人为的,因为在不使用队列的情况下做同样的事情会更自然,但是它演示了在后续处理之前使用队列存储元素。

import java.util.*;
public class Countdown {
public static void main(String[] args) throws InterruptedException {
int time = Integer.parseInt(args[0]);
Queue queue = new LinkedList();
for (int i = time; i >= 0; i--)
queue.add(i);
while (!queue.isEmpty()) {
System.out.println(queue.remove());
Thread.sleep(1000);
}
}
}
在下面的示例中,优先队列用于对元素集合进行排序。同样,这个程序是人为的,因为没有理由使用它来支持集合中提供的sort方法,但是它演示了优先级队列的行为
static List heapSort(Collection c) {
Queue queue = new PriorityQueue(c);
List result = new ArrayList();
while (!queue.isEmpty())
result.add(queue.remove());
return result;
}
Deque 接口
deque通常读作deck,是一个双端队列。双端队列是支持在两端插入和删除元素的元素的线性集合。Deque接口是比堆栈和队列更丰富的抽象数据类型,因为它同时实现堆栈和队列。Deque接口定义了访问Deque实例两端元素的方法。方法用于插入、删除和检查元素。像ArrayDeque和LinkedList这样的预定义类实现了Deque接口。
注意,Deque接口既可以用作后进先出堆栈,也可以用作先进先出队列。Deque接口中给出的方法分为三个部分
insert插入:
addfirst和offerFirst方法在Deque实例的开头插入元素。方法addLast和offerLast在Deque实例末尾插入元素。当Deque实例的容量受到限制时,首选的方法是offerFirst和offerLast,因为如果addFirst已满,则可能无法抛出异常
remove移除:
removeFirst和pollFirst方法从Deque实例的开始删除元素。removeLast和pollLast方法从末尾删除元素。如果Deque为空,方法pollFirst和pollLast返回null;如果Deque实例为空,方法removeFirst和removeLast抛出异常。
Retrieve检索:
getFirst和peekFirst方法检索Deque实例的第一个元素。这些方法不会从Deque实例中删除值。类似地,getLast和peekLast方法检索最后一个元素。如果deque实例为空,getFirst和getLast方法抛出异常,而peekFirst和peekLast方法返回NULL

除了这些用于插入、删除和检查Deque实例的基本方法之外,Deque接口还有一些预定义的方法。其中之一是removeFirstOccurence,如果指定元素存在于Deque实例中,该方法将删除指定元素的第一次出现。如果元素不存在,则Deque实例保持不变。另一个类似的方法是removelastence;此方法移除Deque实例中指定元素的最后一次出现。这些方法的返回类型是boolean,如果Deque实例中存在元素,则返回true
Map接口
Map是一个将键映射到值的对象。映射不能包含重复的键:每个键最多可以映射到一个值。它对数学函数抽象建模。Map接口包括用于基本操作(如put、get、remove、containsKey、containsValue、size和empty)、批量操作(如putAll和clear)和集合视图(如keySet、entrySet和values)的方法。
Java平台包含三个通用的映射实现:HashMap、TreeMap和LinkedHashMap。它们的行为和性能完全类似于HashSet、TreeSet和LinkedHashSet,如Set接口部分所述。
详细讨论Map接口之前首先看下使用JDK 8聚合操作收集到映射的示例。在面向对象编程中,对真实对象建模是一项常见的任务,因此一些程序可能会按部门对员工进行分组
// Group employees by department
Map> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
或按部门计算所有薪金总额:
Map totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.summingInt(Employee::getSalary)));
或者通过或不通过分数来分组学生,把学生分成及格和不及格
Map> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade()>= PASS_THRESHOLD));
按城市将人们分组:
Map> peopleByCity
= personStream.collect(Collectors.groupingBy(Person::getCity));
或者甚至是级联两个收集器,按州和城市对人进行分类
Map>> peopleByStateAndCity
= personStream.collect(Collectors.groupingBy(Person::getState,
Collectors.groupingBy(Person::getCity)))
其他聚合操作可以参考官网
Map接口的基本操作:
Map的基本操作(put、get、containsKey、containsValue、size和isEmpty)的行为与Hashtable中的对应操作完全相同。下面的程序生成一个频率表,其中包含在它的参数列表中找到的单词。频率表将每个单词映射到它在参数列表中出现的次数。
import java.util.*;
public class Freq {
public static void main(String[] args) {
Map m = new HashMap();
// Initialize frequency table from command line
for (String a : args) {
Integer freq = m.get(a);
m.put(a, (freq == null) ? 1 : freq + 1);
}
System.out.println(m.size() + " distinct words:");
System.out.println(m);
}
}
这个程序唯一棘手的地方是put语句的第二个参数。
该参数是一个条件表达式,如果单词之前从未出现过,
则其频率设置为1,如果单词已经出现,
则其频率设置为当前值的1倍。
java Freq if it is to be it is up to me to delegate
程序生成以下输出。
8 distinct words:
{to=3, delegate=1, be=1, it=2, up=1, if=1, me=1, is=2}
按字母顺序看频率表。
将映射的实现类型从HashMap更改为TreeMap。
进行此四字符更改将导致程序从同一命令行生成以下输出。
8 distinct words:
{be=1, delegate=1, if=1, is=2, it=2, me=1, to=3, up=1}
类似地,只需将映射的实现类型更改为LinkedHashMap,
程序就可以按单词第一次出现在命令行上的顺序打印频率表。
8 distinct words:
{if=1, it=2, is=2, to=3, be=1, up=1, me=1, delegate=1}
与Set和List接口相似,但是Map加强了对equals和hashCode方法的要求,
这样就可以比较两个Map对象的逻辑相等性,而不必考虑它们的实现类型。如果两个映射实例表示相同的键值映射,则它们是相等的。
按照惯例,所有通用映射实现都提供构造函数,构造函数接受映射对象并初始化新映射,以包含指定映射中的所有键值映射。这个标准映射转换构造函数与标准集合构造函数完全类似:它允许调用者创建所需实现类型的映射,该实现类型最初包含另一个映射中的所有映射,而不管另一个映射的实现类型如何。例如,假设您有一个名为m的映射。下面的一行程序首先创建一个新的HashMap,其中包含与m相同的所有键值映射。
Map copy = new HashMap(m);
Map接口聚合操作
clear操作所做的正是您认为它可以做的:它从映射中删除所有映射。putAll操作是集合接口addAll操作的映射模拟。除了将一个地图转储到另一个地图的明显用途之外,它还有第二个更微妙的用途。假设使用映射来表示属性值对的集合;putAll操作与映射转换构造函数相结合,提供了一种使用默认值实现属性映射创建的简洁方法。下面是演示此技术的静态工厂方法
static Map newAttributeMap(Mapdefaults, Map overrides) {
Map result = new HashMap(defaults);
result.putAll(overrides);
return result;
}
- keySet —键集映射中包含的一组键。
- values —值映射中包含的值的集合。这个集合不是一个集合,因为多个键可以映射到同一个值。
- entrySet映射中包含的键值对集。Map接口提供了一个名为Map的小型嵌套接口。项,此集合中元素的类型。
for (KeyType key : m.keySet())
System.out.println(key);
或者
for (Iterator it = m.keySet().iterator(); it.hasNext(); )
if (it.next().isBogus())
it.remove();
或者
for (Map.Entry e : m.entrySet())
System.out.println(e.getKey() + ": " + e.getValue());
首先,许多人担心这些习惯用法可能很慢,因为每次调用集合视图操作时映射都必须创建一个新的集合实例。 Map没有理由不能在每次请求给定的集合视图时总是返回相同的对象。这正是所有Map在java中的实现java.util做。
对于所有这三个集合视图,调用迭代器的remove操作将从支持映射中删除相关条目,假设支持映射一开始就支持元素删除。前面的过滤习惯用法说明了这一点。
使用entrySet视图,还可以通过调用映射来更改与键关联的值。迭代过程中Entry的setValue方法(同样,假设映射一开始支持值修改)。注意,这些是在迭代期间修改映射的惟一安全方法;如果在迭代过程中以任何其他方式修改底层映射,则该行为是未指定的。
集合视图支持多种形式的元素删除——remove、removeAll、retainAll和clear操作,以及迭代器。删除操作。(同样,这假设支持删除元素。)
集合视图在任何情况下都不支持添加元素。这对于键集和值视图没有任何意义,对于entrySet视图也没有必要,因为支持映射的put和putAll方法提供了相同的功能。
集合视图的奇特用途:映射代数
当应用于集合视图时,批量操作(containsAll、removeAll和retainAll)是非常有效的工具。对于初学者,假设您想知道一个映射是否是另一个映射的子映射——也就是说,第一个映射是否包含第二个映射中的所有键值映射。下面这个用法就能说明问题:
if (m1.entrySet().containsAll(m2.entrySet())) {
...
}
同样,假设您想知道两个映射对象是否包含所有相同键的映射。
if (m1.keySet().equals(m2.keySet())) {
...
}
假设您有一个表示属性-值对集合的映射,以及两个表示必需属性和允许属性的集合。(允许的属性包括必需的属性。)下面的代码片段确定属性映射是否符合这些约束,如果不符合,则打印详细的错误消息。
static boolean validate(Map attrMap, Set requiredAttrs, SetpermittedAttrs) {
boolean valid = true;
Set attrs = attrMap.keySet();
if (! attrs.containsAll(requiredAttrs)) {
Set missing = new HashSet(requiredAttrs);
missing.removeAll(attrs);
System.out.println("Missing attributes: " + missing);
valid = false;
}
if (! permittedAttrs.containsAll(attrs)) {
Set illegal = new HashSet(attrs);
illegal.removeAll(permittedAttrs);
System.out.println("Illegal attributes: " + illegal);
valid = false;
}
return valid;
}
假设您想知道两个Map对象共有的所有键。
SetcommonKeys = new HashSet(m1.keySet());
commonKeys.retainAll(m2.keySet());
上面的例子,所有的用法都是非破坏性的;也就是说,它们不修改原有映射。
假设想删除一个映射与另一个映射具有相同之处的所有键值对
m1.entrySet().removeAll(m2.entrySet());
假设想从一个映射中删除在另一个映射中具有映射的所有键。
m1.keySet().removeAll(m2.keySet());
当开始在相同的批量操作中混合键和值时会发生什么?假设这个map,经理,它把公司里的每个员工映射到员工的经理。我们将故意模糊键和值对象的类型。没关系,只要它们是一样的。现在假设您想知道所有“个人贡献者”(或非管理员)是谁。下面的代码片段确切地告诉了您想知道的内容
Set individualContributors = new HashSet(managers.keySet());
individualContributors.removeAll(managers.values());
假设你想解雇所有直接向经理西蒙汇报的员工。
Employee simon = ... ;
managers.values().removeAll(Collections.singleton(simon));
注意,上面的方法使用Collections.singleton,一个静态工厂方法,返回一个不可变的集合,其中包含一个指定的元素。
Multimaps(多重映射)
import java.util.*;
import java.io.*;
public class Anagrams {
public static void main(String[] args) {
int minGroupSize = Integer.parseInt(args[1]);
// Read words from file and put into a simulated multimap
Map> m = new HashMap>();
try {
Scanner s = new Scanner(new File(args[0]));
while (s.hasNext()) {
String word = s.next();
String alpha = alphabetize(word);
List l = m.get(alpha);
if (l == null)
m.put(alpha, l=new ArrayList());
l.add(word);
}
} catch (IOException e) {
System.err.println(e);
System.exit(1);
}
// Print all permutation groups above size threshold
for (List l : m.values())
if (l.size() >= minGroupSize)
System.out.println(l.size() + ": " + l);
}
private static String alphabetize(String s) {
char[] a = s.toCharArray();
Arrays.sort(a);
return new String(a);
}
}
输出结果:
9: [estrin, inerts, insert, inters, niters, nitres, sinter,
triens, trines]
8: [lapse, leaps, pales, peals, pleas, salep, sepal, spale]
8: [aspers, parses, passer, prases, repass, spares, sparse,
spears]
10: [least, setal, slate, stale, steal, stela, taels, tales,
teals, tesla]
8: [enters, nester, renest, rentes, resent, tenser, ternes,
treens]
8: [arles, earls, lares, laser, lears, rales, reals, seral]
8: [earings, erasing, gainers, reagins, regains, reginas,
searing, seringa]
8: [peris, piers, pries, prise, ripes, speir, spier, spire]
12: [apers, apres, asper, pares, parse, pears, prase, presa,
rapes, reaps, spare, spear]
11: [alerts, alters, artels, estral, laster, ratels, salter,
slater, staler, stelar, talers]
9: [capers, crapes, escarp, pacers, parsec, recaps, scrape,
secpar, spacer]
9: [palest, palets, pastel, petals, plates, pleats, septal,
staple, tepals]
9: [anestri, antsier, nastier, ratines, retains, retinas,
retsina, stainer, stearin]
8: [ates, east, eats, etas, sate, seat, seta, teas]
8: [carets, cartes, caster, caters, crates, reacts, recast,
traces]
对象排序
Collections.sort(list);
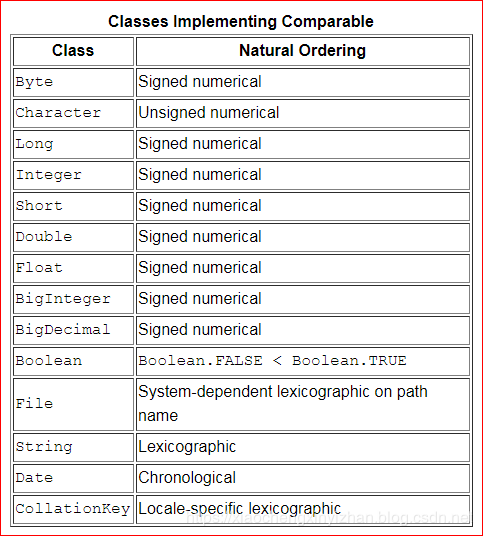
如果列表由字符串元素组成,则按字母顺序排序。如果它由日期元素组成,则按时间顺序排序。这是怎么发生的呢?String和Date都实现了可比接口。可比较的实现为类提供了一种自然排序,这允许自动对该类的对象进行排序。下表总结了实现Comparable的一些更重要的Java平台类。
如果您试图对一个列表进行排序,其中的元素没有实现Comparable .sort(list),则会抛出一个ClassCastException。同样,集合。sort(list, comparator)将抛出一个ClassCastException异常,如果您试图对一个列表进行排序,而其中的元素不能使用comparator相互比较。可以相互比较的元素称为相互比较元素。虽然不同类型的元素可以相互比较,但是这里列出的所有类都不允许类间比较。
制定自己的比较类:
需要关注这个接口
public interface Comparable {
public int compareTo(T o);
}
compareTo方法将接收对象与指定对象进行比较,并根据接收对象是否小于、等于或大于指定对象返回一个负整数、0或正整数。如果无法将指定的对象与接收对象进行比较,则该方法将抛出ClassCastException
举个例子:
import java.util.*;
public class Name implements Comparable {
private final String firstName, lastName;
public Name(String firstName, String lastName) {
if (firstName == null || lastName == null)
throw new NullPointerException();
this.firstName = firstName;
this.lastName = lastName;
}
public String firstName() { return firstName; }
public String lastName() { return lastName; }
public boolean equals(Object o) {
if (!(o instanceof Name))
return false;
Name n = (Name) o;
return n.firstName.equals(firstName) && n.lastName.equals(lastName);
}
public int hashCode() {
return 31*firstName.hashCode() + lastName.hashCode();
}
public String toString() {
return firstName + " " + lastName;
}
public int compareTo(Name n) {
int lastCmp = lastName.compareTo(n.lastName);
return (lastCmp != 0 ? lastCmp : firstName.compareTo(n.firstName));
}
}
上面的代码的要求:具体深入了解限制需要看API文档
名称对象是不可变的。在所有其他条件相同的情况下,不可变类型是解决问题的方法,特别是对于将作为集合中的元素或映射中的键使用的对象。如果在集合中修改它们的元素或键,则这些集合将会中断。构造函数检查其参数是否为空。这确保了所有Name对象都是格式良好的,因此其他方法都不会抛出NullPointerException。重新定义了hashCode方法。这对于任何重新定义equals方法的类都是必不可少的。(相等的对象必须有相等的哈希码。)如果指定的对象为空或类型不合适,则equals方法返回false。compareTo方法在这些情况下抛出一个运行时异常。这两种行为都是各自方法的一般契约所要求的。toString方法已重新定义,因此它以人类可读的形式打印名称。这总是一个好主意,特别是对于那些将要被放入集合中的对象。各种集合类型的toString方法依赖于它们的元素、键和值的toString方法。
假设需要排序姓名:
import java.util.*;
public class NameSort {
public static void main(String[] args) {
Name nameArray[] = {
new Name("John", "Smith"),
new Name("Karl", "Ng"),
new Name("Jeff", "Smith"),
new Name("Tom", "Rich")
};
List names = Arrays.asList(nameArray);
Collections.sort(names);
System.out.println(names);
}
}
输出结果
[Karl Ng, Tom Rich, Jeff Smith, John Smith]
自然顺序排序Comparators:
public interface Comparator {
int compare(T o1, T o2);
}
假设比较的类
public class Employee implements Comparable {
public Name name() { ... }
public int number() { ... }
public Date hireDate() { ... }
...
}
可以如下实现方式
import java.util.*;
public class EmpSort {
static final Comparator SENIORITY_ORDER =
new Comparator() {
public int compare(Employee e1, Employee e2) {
return e2.hireDate().compareTo(e1.hireDate());
}
};
// Employee database
static final Collection employees = ... ;
public static void main(String[] args) {
List e = new ArrayList(employees);
Collections.sort(e, SENIORITY_ORDER);
System.out.println(e);
}
}
SortedSet 接口
SortedSet是一组按升序维护其元素的集合,根据元素的自然顺序或在SortedSet创建时提供的比较器进行排序。除了正常的Set操作之外,SortedSet接口还提供以下操作
- 范围视图–允许对排序后的集合端点进行任意范围操作,
- 端点–返回排序后的集合比较器访问中的第一个或最后一个元素
- 比较器访问–返回用于对集合排序的比较器(如果有的话)
public interface SortedSet extends Set {
// Range-view
SortedSet subSet(E fromElement, E toElement);
SortedSet headSet(E toElement);
SortedSet tailSet(E fromElement);
// Endpoints
E first();
E last();
// Comparator access
Comparator comparator();
}
SortedMap 接口:
与SortedSet类似相同
public interface SortedMap extends Map{
Comparator comparator();
SortedMap subMap(K fromKey, K toKey);
SortedMap headMap(K toKey);
SortedMap tailMap(K fromKey);
K firstKey();
K lastKey();
}
集合小结:
- 第一个树从Collection接口开始,它提供了所有集合使用的基本功能,比如add和remove方法。它的子接口——Set、List和Queue——提供了更专门化的集合。
- Set接口不允许重复元素。这对于存储诸如一副卡片或学生记录之类的集合非常有用。Set接口有一个子接口SortedSet,用于对集合中的元素进行排序。
- List接口提供了一个有序集合,用于需要精确控制每个元素插入位置的情况。您可以根据元素的确切位置从列表中检索元素。
- 队列接口支持额外的插入、提取和检查操作。队列中的元素通常基于FIFO进行排序。
- Deque接口支持在两端进行插入、删除和检查操作。Deque中的元素可以在LIFO和FIFO中使用。
- 第二棵树以Map接口开始,该接口映射类似于散列表的键和值。
- Map的子接口SortedMap以升序或比较器指定的顺序维护键值对。
集合主要四大类:
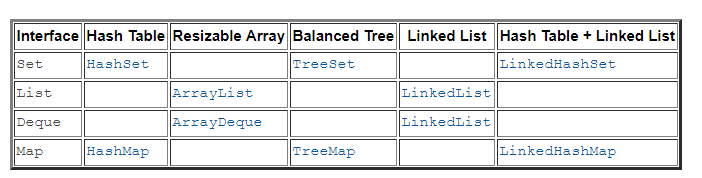
- 对于Set接口,HashSet是最常用的实现。
- 对于List接口,ArrayList是最常用的实现。
- 对于Map接口,HashMap是最常用的实现。
- 对于队列接口,LinkedList是最常用的实现。
- 对于Deque接口,ArrayDeque是最常用的实现。
关于集合框架的大图:
Set的实现
有三种通用的Set实现:HashSet、TreeSet和LinkedHashSet。使用这三种方法中的哪一种通常比较简单。HashSet比TreeSet快得多(对于大多数操作来说,是常量时间对日志时间),但是没有提供顺序保证。如果需要使用SortedSet接口中的操作,或者需要值顺序迭代,则使用TreeSet;否则,使用HashSet。可以肯定的是,您将在大多数情况下使用HashSet。LinkedHashSet在某种意义上介于HashSet和TreeSet之间。它实现为一个哈希表,其中运行一个链表,它提供了按插入顺序的迭代(最近插入的最少),运行速度几乎与HashSet一样快。LinkedHashSet实现将其客户机从HashSet提供的未指定的、通常混乱的顺序中解脱出来,而不会增加与TreeSet相关的成本。关于HashSet值得记住的一点是,迭代在条目数和桶数(容量)的和上是线性的。因此,选择过高的初始容量会浪费空间和时间。另一方面,选择一个过低的初始容量会浪费时间,因为每次它被迫增加容量时都会复制数据结构。如果没有指定初始容量,默认值为16。在过去,选择质数作为初始容量有一定的优势。这不再是事实。在内部,容量总是四舍五入到2的幂。初始容量由int构造函数指定。下面的代码行分配初始容量为64的HashSet。
Set s = new HashSet(64);
HashSet类还有另一个调优参数,称为负载因子。如果非常关心HashSet的空间消耗,请阅读HashSet文档了解更多信息。否则,接受默认值;这几乎总是正确的做法。如果您接受默认的负载因子,但希望指定初始容量,请选择一个大约是您预期的集增长大小的两倍的数字。如果你猜错了,你可能会浪费一点空间、时间,或者两者都浪费,但这不太可能是一个大问题。LinkedHashSet具有与HashSet相同的调优参数,但是迭代时间不受容量的影响。TreeSet没有调优参数。
有两种特殊用途的Set实现—EnumSet和CopyOnWriteArraySet。
EnumSet是枚举类型的高性能集实现。枚举集的所有成员必须具有相同的枚举类型。在内部,它由位向量表示,通常是单个长向量。枚举集支持枚举类型范围上的迭代。例如,给定了一周中的天数的enum声明,您可以在工作日中进行迭代。EnumSet类提供了一个静态工厂,使其变得简单。
for (Day d : EnumSet.range(Day.MONDAY, Day.FRIDAY))
System.out.println(d);
Enum集合还为传统位标志提供了丰富的类型安全替换。
EnumSet.of(Style.BOLD, Style.ITALIC)
CopyOnWriteArraySet是一个由写时复制数组支持的集合实现。所有的可变操作,如添加、设置和删除,都是通过创建数组的新副本来实现的;不需要任何锁。即使是迭代也可以安全地同时进行元素的插入和删除。与大多数Set实现不同,add、remove和contains方法需要的时间与Set的大小成比例。此实现仅适用于很少修改但经常迭代的集合。它非常适合于维护必须防止重复的事件处理程序列表
List的实现
有两个通用的列表实现ArrayList和LinkedList。大多数情况下,您可能会使用ArrayList,它提供了固定时间的位置访问,而且非常快。它不必为列表中的每个元素分配一个节点对象,并且可以利用系统。当arraycopy必须同时移动多个元素时。将ArrayList看作没有同步开销的向量。如果您经常向列表的开头添加元素,或者遍历列表以从列表内部删除元素,那么您应该考虑使用LinkedList。这些操作需要LinkedList中的常量时间和ArrayList中的线性时间。但你在表现上付出了巨大的代价。位置访问需要LinkedList中的线性时间和ArrayList中的常量时间。此外,LinkedList的常数因子要糟糕得多。如果您认为需要使用LinkedList,那么在做出选择之前,请同时使用LinkedList和ArrayList度量应用程序的性能;ArrayList通常更快。ArrayList有一个调优参数初始容量,它指的是ArrayList在增长之前可以容纳的元素数量。LinkedList没有调优参数和七个可选操作,其中一个是clone。其他六个是addFirst、getFirst、removeFirst、addLast、getLast和removeLast。LinkedList还实现队列接口。
CopyOnWriteArrayList是一个列表实现,由写时复制数组备份。这个实现在本质上类似于CopyOnWriteArraySet。即使在迭代期间,也不需要同步,并且保证迭代器永远不会抛出ConcurrentModificationException。此实现非常适合于维护事件处理程序列表,其中更改不频繁,遍历频繁且可能耗时。如果需要同步,向量将比与Collections.synchronizedList同步的ArrayList稍微快一些。但是Vector有很多遗留操作,所以一定要小心使用List接口操作Vector,否则以后就无法替换实现了。如果列表的大小是固定的,那么除了containsAll之外,您永远不会使用remove、add或其他任何批量操作。
Map 实现
三种通用的映射实现是HashMap、TreeMap和LinkedHashMap。如果需要SortedMap操作或键顺序的集合视图迭代,请使用TreeMap;如果您想要最大速度,而不关心迭代顺序,那么使用HashMap;如果您想要接近hashmap的性能和插入顺序迭代,请使用LinkedHashMap。在这方面,Map的情况类似于Set。同样,Set implementation部分中的其他内容也适用于Map实现。LinkedHashMap提供了LinkedHashSet不可用的两个功能。创建LinkedHashMap时,可以根据键访问而不是插入对其进行排序。换句话说,只要查找与键关联的值,就会将该键带到映射的末尾。此外,LinkedHashMap提供了removeEldestEntry方法,当向映射添加新映射时,可以重写该方法来强制执行自动删除陈旧映射的策略。这使得实现自定义缓存变得非常容易。例如,这个覆盖将允许映射增长到最多100个条目,然后每当添加一个新条目时,它将删除最老的条目,保持100个条目的稳定状态。
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
有三种特殊用途的映射实现:EnumMap、WeakHashMap和IdentityHashMap。EnumMap是一个内部实现为数组的高性能映射实现,可与enum键一起使用。这个实现将Map接口的丰富性和安全性与数组的速度相结合。如果希望将枚举映射到值,应该始终使用EnumMap而不是数组。WeakHashMap是Map接口的实现,它只存储对键的弱引用。仅存储弱引用允许当键值对的键不再在WeakHashMap外引用时垃圾收集它。该类提供了利用弱引用的能力的最简单方法。它对于实现“类似于注册”的数据结构很有用,在这种结构中,当某个条目的键不再被任何线程访问时,该条目的实用程序就会消失。IdentityHashMap是基于哈希表的基于标识的映射实现。该类对于保存拓扑的对象图转换(如序列化或深度复制)非常有用。要执行这样的转换,您需要维护一个基于身份的“节点表”,它跟踪哪些对象已经被看到。基于身份的映射还用于在动态调试器和类似系统中维护对象到元信息的映射。最后,基于身份的映射在阻止“欺骗攻击”方面很有用,因为IdentityHashMap从不调用键上的equals方法,而“欺骗攻击”是故意违背equals方法的结果。这种实现的另一个好处是速度快。
java.util。concurrent包包含ConcurrentMap接口,它使用原子putIfAbsent、remove和replace方法扩展Map,以及该接口的ConcurrentHashMap实现。ConcurrentHashMap是一个由哈希表支持的高并发、高性能的实现。此实现在执行检索时从不阻塞,并允许客户端为更新选择并发级别。它的目的是作为Hashtable的下拉式替代:除了实现ConcurrentMap之外,它还支持Hashtable特有的所有遗留方法。同样,如果不需要遗留操作,请小心使用ConcurrentMap接口操作它
Queue 实现
如前一节所述,LinkedList实现队列接口,为add、poll等提供先入先出(FIFO)队列操作。PriorityQueue类是基于堆数据结构的优先级队列。该队列根据构造时指定的顺序对元素排序,可以是元素的自然顺序,也可以是显式比较器强制的顺序。队列检索操作轮询、删除、查看和元素访问队列头部的元素。队列的头是与指定顺序相关的最小元素。如果多个元素以最小值绑定,则head是其中一个元素;领带是任意断的。PriorityQueue及其迭代器实现集合和迭代器接口的所有可选方法。方法迭代器中提供的迭代器不能保证以任何特定的顺序遍历PriorityQueue的元素。对于有序遍历,可以考虑使用Arrays.sort(pq.toArray()).)。
java.util.concurrent并发包包含一组同步队列接口和类。BlockingQueue通过以下操作扩展队列:在检索元素时等待队列变为非空,在存储元素时等待队列中的空间变为可用。该接口由以下类实现:
LinkedBlockingQueue链接节点支持的一个可选的FIFO阻塞队列之间有界FIFO阻塞队列由数组PriorityBlockingQueue一个无界的阻断优先队列由一堆
DelayQueue基于时间的调度队列由一堆
SynchronousQueue BlockingQueue接口的简单的对接机制,
使用JDK 7,TransferQueue是一个专门的BlockingQueue,其中向队列添加元素的代码可以选择等待(阻塞)另一个线程中的代码来检索元素。 TransferQueue只有一个实现:
LinkedTransferQueue一个基于链接节点的无界传输队列
Deque实现
通用实现包括LinkedList和ArrayDeque类。Deque接口支持在两端插入、删除和检索元素。ArrayDeque类是Deque接口的可调整大小的数组实现,而LinkedList类是列表实现。在Deque接口addFirst、addLast、removeFirst、removeLast、getFirst和getLast中基本的插入、删除和retieval操作。方法addFirst在头部添加一个元素,而addLast在Deque实例的尾部添加一个元素。LinkedList实现比ArrayDeque实现更灵活。LinkedList实现所有可选的列表操作。在LinkedList实现中允许空元素,但在ArrayDeque实现中不允许。在效率方面,ArrayDeque对于两端的添加和删除操作比LinkedList更有效。LinkedList实现中最好的操作是在迭代期间删除当前元素。LinkedList实现不是理想的迭代结构。LinkedList实现比ArrayDeque实现消耗更多的内存。对于ArrayDeque实例遍历,可以使用以下任意一种方法
ArrayDeque aDeque = new ArrayDeque();
for (String str : aDeque) {
System.out.println(str);
}
ArrayDeque aDeque = new ArrayDeque();
for (Iterator iter = aDeque.iterator(); iter.hasNext(); ) {
System.out.println(iter.next());
}
打印输出例子:
/*
* Copyright (c) 2012, Oracle and/or its affiliates. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
*
* - Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
*
* - Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* - Neither the name of Oracle or the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS
* IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO,
* THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
* LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
/**
*ArrayDequeSample.java creates and prints the contents of an ArrayDeque.
*/
import java.util.ArrayDeque;
import java.util.Iterator;
public class ArrayDequeSample {
public static void main(String[] args) {
ArrayDeque aDeque = new ArrayDeque<> ();
aDeque.addFirst("tea");
aDeque.addFirst("milk");
aDeque.addFirst("coffee");
aDeque.addLast("sugar");
/* Iterate through elements in an ArrayDeque instance */
for( Iterator itr = aDeque.iterator(); itr.hasNext(); ) {
System.out.println(itr.next());
}
System.out.println();
aDeque.addFirst("juice");
aDeque.addLast("honey");
System.out.println("First Element : " + aDeque.getFirst());
System.out.println("Last Element : " + aDeque.getLast());
/* Removal of the Deque Elements */
System.out.println("First Element(Removed):"+aDeque.removeFirst());
System.out.println("Last Element Removed:"+aDeque.removeLast());
System.out.println("%nPopped Element : " + aDeque.pop());
System.out.println("%n Size of Array Deque: " + aDeque.size());
}
}
并发队列的实现:
LinkedBlockingDeque类是Deque接口的并发实现。如果deque是空的,那么takeFirst和takeLast等方法将等待元素可用,然后检索和删除相同的元素。
包装器:
同步包装器:
同步包装器将自动同步(线程安全)添加到任意集合。这六个核心集合接口——集合、集合、列表、映射、SortedSet和SortedMap——都有一个静态工厂方法。
public static Collection synchronizedCollection(Collection c);
public static Set synchronizedSet(Set s);
public static List synchronizedList(List list);
public static Map synchronizedMap(Map m);
public static SortedSet synchronizedSortedSet(SortedSet s);
public static SortedMap synchronizedSortedMap(SortedMap m);
每个方法都返回一个由指定集合备份的同步(线程安全)集合。为了保证串行访问,必须通过返回的集合完成对备份集合的所有访问。保证这一点的简单方法是不保留对支持集合的引用。使用以下技巧创建同步集合。
List list = Collections.synchronizedList(new ArrayList());
以这种方式创建的集合与通常同步的集合(如向量)一样是线程安全的。面对并发访问,用户必须在遍历返回的集合时手动同步它。原因是迭代是通过对集合的多个调用来完成的,集合必须组合成单个原子操作。下面是遍历包装同步集合的习惯用法。
Collection c = Collections.synchronizedCollection(myCollection);
synchronized(c) {
for (Type e : c)
foo(e);
}
如果使用显式迭代器,则必须从同步块内调用迭代器方法。未能遵循此建议可能导致不确定性行为。用于遍历同步映射的集合视图的习惯用法类似。当用户在其集合视图上迭代时,必须在同步映射上同步,而不是在集合视图上同步,如下面的示例所示。
ap m = Collections.synchronizedMap(new HashMap());
...
Set s = m.keySet();
...
// Synchronizing on m, not s!
synchronized(m) {
while (KeyType k : s)
foo(k);
}
使用包装器实现的一个小缺点是,您没有能力执行包装实现的任何非接口操作。因此,例如,在前面的列表示例中,您不能在包装好的ArrayList上调用ArrayList的ensureCapacity操作。
不可修改包装器:
与同步包装器不同,同步包装器向包装的集合添加功能,不可修改的包装器删除功能。特别是,它们通过拦截将修改集合的所有操作并抛出UnsupportedOperationException来取消修改集合的能力。不可修改的包装有两个主要用途,如下:
- 使集合在构建后不可变。在这种情况下,最好不要维护对支持集合的引用。这绝对保证了不变性。
- 允许某些客户机只读访问您的数据结构。您保留对支持集合的引用,但将引用分发给包装器。通过这种方式,客户端可以查看但不能修改,而您可以维护完全访问。
public static Collection unmodifiableCollection(Collection c);
public static Set unmodifiableSet(Set s);
public static List unmodifiableList(List list);
public static Map unmodifiableMap(Map m);
public static SortedSet unmodifiableSortedSet(SortedSet s);
public static SortedMap unmodifiableSortedMap(SortedMap m);
Collections.checked提供了用于泛型集合的已检查接口包装器。这些实现返回指定集合的动态类型安全视图,如果客户机试图添加错误类型的元素,该视图将抛出ClassCastException。该语言中的泛型机制提供编译时(静态)类型检查,但是有可能击败这种机制。动态类型安全视图完全消除了这种可能性。
便利的实现提供方案:
数组的列表视图
Arrays.asList 方法返回其数组参数的列表视图。对列表的更改写入数组,反之亦然。集合的大小是数组的大小,不能更改。如果在列表中调用add或remove方法,将会导致UnsupportedOperationException。这个实现的通常用途是作为基于数组和基于集合的api之间的桥梁。它允许您将数组传递给期望集合或列表的方法。然而,这个实现还有另一个用途。如果您需要一个固定大小的列表,那么它比任何通用列表实现都更有效。
List list = Arrays.asList(new String[size]);
注意,对支持数组的引用没有保留。
不可变的多重副本列表
有时,您需要一个不可变的列表,由相同元素的多个副本组成。的集合。Collections.nCopies 方法返回这样的列表。这个实现有两个主要用途。首先是初始化一个新创建的列表;例如,假设您想要一个最初由1,000个空元素组成的ArrayList。
List list = new ArrayList(Collections.nCopies(1000, (Type)null);
当然,每个元素的初始值不必为空。第二个主要用途是增长现有列表。例如,假设您想将字符串“fruit bat”的69个副本添加到列表< string >的末尾。现在还不清楚你为什么想做这样的事情,但是让我们假设你做了。下面是你应该怎么做。
lovablePets.addAll(Collections.nCopies(69, "fruit bat"));
通过使用同时接受索引和集合的addAll形式,您可以将新元素添加到列表的中间,而不是列表的末尾。
不可变的单集
有时您需要一个不可变的单例集,它由一个指定的元素组成。Collections.singleton 方法返回这样一个集合。该实现的一个用途是从集合中删除指定元素的所有出现
c.removeAll(Collections.singleton(e));
相关的习惯用法从映射中删除映射到指定值的所有元素。例如,假设您有一个Map - job,它将人们映射到他们的工作领域,并且假设您想消除所有的律师。下面的一行代码就可以了。
job.values().removeAll(Collections.singleton(LAWYER));
空的集合、列表和映射常量
Collections类提供了返回空集、列表和Map - emptySet、emptyList和emptyMap的方法。这些常量的主要用途是作为方法的输入,当您根本不想提供任何值时,这些方法将接受一组值,如本例中所示。
tourist.declarePurchases(Collections.emptySet());