(二)使用Ansible搭建分布式大数据基础环境-Ansible项目创建
“使用Ansible搭建分布式大数据基础环境”系列文章完整包含了如何使用Ansible这一分布式运维利器,来帮我们快速搭建Hadoop2/Spark2/Hive2/ZooKeeper3/Flink1.7/ElasticSearch5等一整套大数据解决方案。本篇是系列文章的第二篇。更多后续文章尽请关注。
(一)使用Ansible搭建分布式大数据基础环境-环境准备
(二)使用Ansible搭建分布式大数据基础环境-Ansible项目创建
(三)使用Ansible搭建分布式大数据基础环境-编写第一个playbook
(四)使用Ansible搭建分布式大数据基础环境-Ansible常用Module介绍
(五)使用Ansible搭建分布式大数据基础环境-ZooKeeper集群模式搭建
(六)使用Ansible搭建分布式大数据基础环境-Hadoop高可用集群搭建
(七)使用Ansible搭建分布式大数据基础环境-MySQL安装
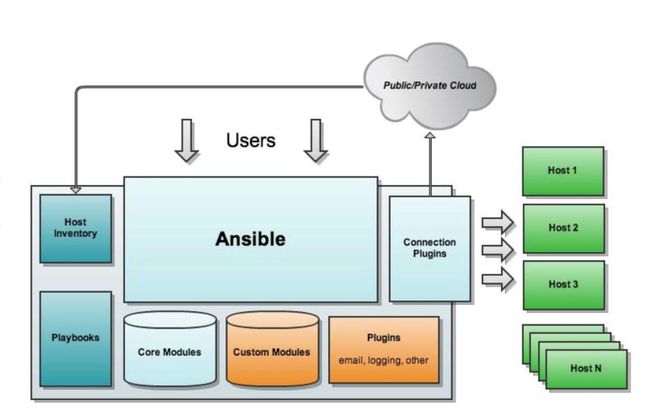
(Ansible架构图)
这一章节主要是完成以下工作:
- Ansible Playbook项目结构创建
- Inventory文件创建,设置我们的集群信息
- group_vars文件创建,创建后面我们经常要用的一些变量及其值。
备注:本章及后面所有playbook文件创建等工作都在本机Mac上完成(也就是Ansible的发号指令机器,另外三台都是接受Ansible指令机器。)
1. Ansible项目结构创建
ansible官方给出了以下推荐的文件目录结构
production # inventory file for production servers
staging # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
library/ # if any custom modules, put them here (optional)
module_utils/ # if any custom module_utils to support modules, put them here (optional)
filter_plugins/ # if any custom filter plugins, put them here (optional)
site.yml # master playbook
webservers.yml # playbook for webserver tier
dbservers.yml # playbook for dbserver tier
roles/
common/ # this hierarchy represents a "role"
tasks/ #
main.yml # <-- tasks file can include smaller files if warranted
handlers/ #
main.yml # <-- handlers file
templates/ # <-- files for use with the template resource
ntp.conf.j2 # <------- templates end in .j2
files/ #
bar.txt # <-- files for use with the copy resource
foo.sh # <-- script files for use with the script resource
vars/ #
main.yml # <-- variables associated with this role
defaults/ #
main.yml # <-- default lower priority variables for this role
meta/ #
main.yml # <-- role dependencies
library/ # roles can also include custom modules
module_utils/ # roles can also include custom module_utils
lookup_plugins/ # or other types of plugins, like lookup in this case
webtier/ # same kind of structure as "common" was above, done for the webtier role
monitoring/ # ""
fooapp/ # ""如果不同Inventory下,group_vars/host_vars有很大不同,官方推荐另一种group_vars/host_vars移植到inventory目录下去的另一种结构:
inventories/
production/
hosts # inventory file for production servers
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
staging/
hosts # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
stagehost1.yml # here we assign variables to particular systems
stagehost2.yml
library/
module_utils/
filter_plugins/
site.yml
webservers.yml
dbservers.yml
roles/
common/
webtier/
monitoring/
fooapp/我们这里由于只搭建一个环境,所以采用第一种目录结构,创建完成之后,我们的目录结构如下图所示:
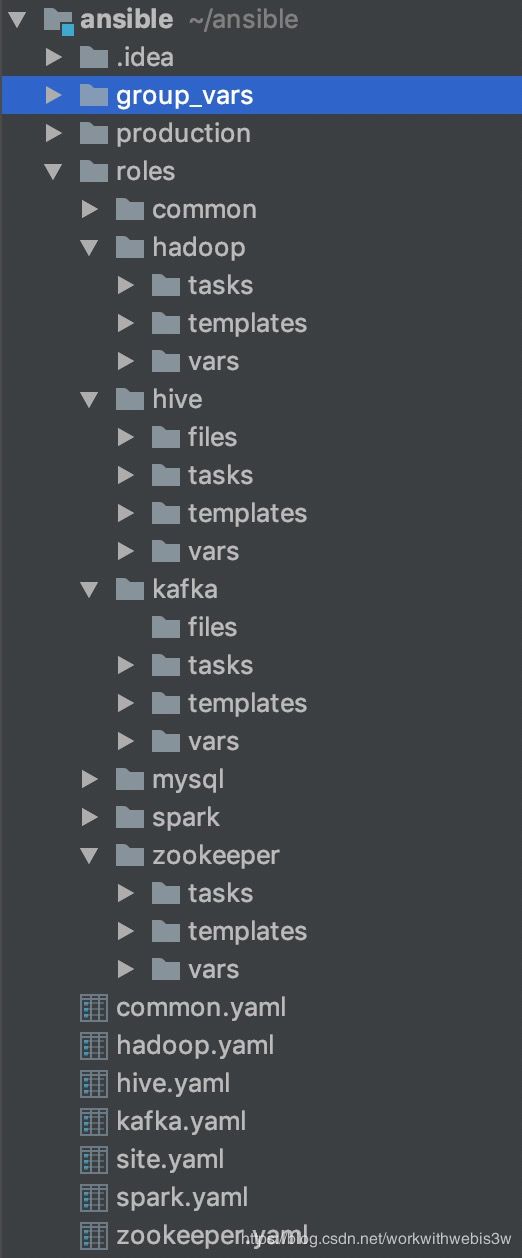
按照官方说明,roles目录存放所有playbook文件(简称playbook,每个playbook代表一个相对完整的工作流,这个工作流包含多个运维步骤,步骤之间存在先后顺序),我们为我们要安装的每个大数据组件都创建一个playbook,以及一个common的基础playbook,下面分别介绍之
- common:所有playbook执行之前都依赖的playbook,目前主要作用是用户创建,目录创建等。
- hadoop:安装hdfs/yarn/mapred等组件playbook
- zookeeper:安装zookeeper的playbook
- spark:安装spark的playbook,安装方式是spark on yarn
- hive:安装hive的playbook
- kafka:安装kafka的playbook
- mysql:安装mysql的playbook
根路径下每个yaml文件分别指定运行某个playbook(如只需要安装hadoop,可以使用ansible-playbook hadoop.yaml只运行hadoop 的搭建workflow),site.yaml引用所有剧本,串起所有playbook的执行工作。
site.yaml和hadoop.yaml两个文件内容如下:
#site.yaml
---
- hosts: cluster
remote_user: hadoop
roles:
- common
- zookeeper
- hadoop
- mysql
- hive
- spark
#hadoop.yaml
---
- hosts: cluster
remote_user: hadoop
roles:
- hadoopYAML文件中roles里配置的顺序具有依赖关系,依赖者要放到被依赖者之后,这样才能够实现被依赖者安装之后再安装依赖者的的正确安装顺序。在这里,由于hadoop/kafka依赖zookeeper,所以zookeeper在最前面,而spark/hive又依赖hadoop,故spark/hive playbook放在hadoop之后。
2. 创建Inventory文件,设置集群分组
在production目录下,创建一个hosts文件,内容如下:
[cluster]
master1
master2
slave1这里我们只创建了一个cluster集群,并把三台机器都归属到这个集群(具体inventory文件的语法格式参照ansible官方文档)。
3.group_vars文件创建
在group_vars目录下,我们创建cluster.yaml文件,在里面用我们添加一下安装hadoop/zookeeper/spark等都需要用到的一些变量:
base: /data/bigdata # 设置我们今后所有操作的顶级目录,包括下载/安装/日志等
download_base: "{{ base }}/download" # 所有需要下载的第三方安装包存放目录
app_base: "{{base}}/app" # 所有应用安装根目录
download_server: "http://mirror.bit.edu.cn/apache" # 所有应用下载mirror地址,之后hadoop/zookeeper/spark等的安装包都会从该mirror下载
data_base: "{{base}}/data" # 所有应用启动后数据存放根目录
log_base: "{{base}}/log" # 所有应用启动后日志存放根目录
run_user: hadoop # 所有程序运行身份
JAVA_HOME: /usr/java/jdk1.8.0_45/总结:至此,我们以及完成了我们的ansible项目的文件结构创建工作。