简介
Spark是基于内存计算的开源分布式大数据计算框架。为了更好、更快地开发Spark应用程序,开发者不仅要掌握Spark的理论基础和实现原理,更需要掌握Spark应用程序调试方式。
Spark应用程序调试方式有:本地调试模式、服务器调试模式、远程调试模式。接下来本文会一一介绍这几种调试方式的使用。
本地调试模式
1.
Spark本地开发工具推荐使用IntelliJ IDEA。编译工具推荐使用Maven或者IntelliJ IDEA自身编译。IntelliJ IDEA开发Spark应用程序和开发其他应用程序一样,可以进行debug调试,输出日志等等。
2.
安装JDK和Scala。安装版本请参考Spark官方网站说明。如2.0.2版本官网描述Spark runs on Java 7+, Python2.6+/3.4+ and R 3.1+. For the Scala API, Spark 2.0.2 uses Scala 2.11. You willneed to use a compatible Scala version (2.11.x).
3.
安装Spark,直接去Download Apache Spark。有两个步骤:
选择好对应Hadoop版本的Spark版本,如下图中所示;
然后点击下图中箭头所指的spark-2.0.2-bin-hadoop2.7.tgz,等待下载结束即可。
这里使用的是Pre-built的版本,意思就是已经编译了好了,下载来直接用就好。Spark也有源码可以下载,但是得自己去手动编译之后才能使用。下载完成后将文件进行解压(可能需要解压两次),最好解压到一个盘的根目录下,并重命名为Spark,简单不易出错。并且需要注意的是,在Spark的文件目录路径名中,不要出现空格,类似于“Program Files”这样的文件夹名是不被允许的。
解压后基本上就可以到cmd命令行下运行了。但这个时候每次运行spark-shell(Spark的命令行交互窗口)的时候,都需要先cd到Spark的安装目录下,比较麻烦,因此可以将Spark的bin目录添加到系统变量PATH中。例如我这里的Spark的bin目录路径为D:Sparkbin,那么就把这个路径名添加到系统变量的PATH中即可,方法和JDK安装过程中的环境变量设置一致。设置完系统变量后,在任意目录下的cmd命令行中,直接执行spark-shell命令,即可开启Spark的交互式命令行模式。
4.
IntelliJ IDEA添加Spark发布的依赖包或者通过Maven配置Spark相关依赖。
5.
安装Hadoop,系统变量设置后,就可以在任意当前目录下的cmd中运行spark-shell,但这个时候很有可能会碰到各种错误,这里主要是因为Spark是基于Hadoop的,所以这里也有必要配置一个Hadoop的运行环境。在HadoopReleases里可以看到Hadoop的各个历史版本,这里下载的Spark是基于Hadoop 2.6的(在Spark安装的第一个步骤中,我们选择的是Pre-built for Hadoop2.6),所以这里选择2.6.4版本。选择好相应版本并点击后,进入详细的下载页面,如下图所示,选择图中红色标记进行下载。
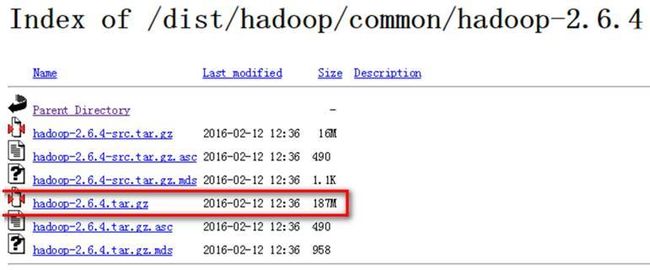
这里下载的是已经编译好的版本。下载并解压到指定目录,然后到环境变量部分设置HADOOP_HOME为Hadoop的解压目录,我这里是F:Program Fileshadoop,然后再设置该目录下的bin目录到系统变量的PATH下,我这里也就是F:Program Fileshadoopbin,如果已经添加了HADOOP_HOME系统变量,也可以用%HADOOP_HOME%bin来指定bin文件夹路径名。这两个系统变量设置好后,开启一个新的cmd,然后直接输入spark-shell命令。
正常情况下是可以运行成功并进入到Spark的命令行环境下的,但是对于有些用户可能会遇到空指针的错误。这个时候,主要是因为Hadoop的bin目录下没有winutils.exe文件的原因造成的。这里的解决办法是:
去https://github.com/steveloughran/winutils选择你安装的Hadoop版本号,然后进入到bin目录下,找到winutils.exe文件,下载方法是点击winutils.exe文件,进入之后在页面的右上方部分有一个Download按钮,点击下载即可。
-
下载好winutils.exe后,将这个文件放入到Hadoop的bin目录下,我这里是F:Program Fileshadoopbin。在打开的cmd中输入F:ProgramFileshadoopbinwinutils.exe chmod 777 /tmp/Hive
这个操作是用来修改权限的。注意前面的F:Program Fileshadoopbin部分要对应的替换成实际你所安装的bin目录所在位置。经过这几个步骤之后,然后再次开启一个新的cmd窗口,如果正常的话,应该就可以通过直接输入spark-shell来运行Spark了。
6.
熟练掌握Spark的API。Spark的API支持Scala、Java、R和Python语言。API包括常见的变化操作算子和行动操作算子。
Spark 服务器调试模式
spark-submit提交jar包。
将本地应用程序打成jar包放在服务器上,在该服务器上执行spark-submit--class com.zte.spark.example.WordCount --executor-memory 1G --total-executor-cores 3 /home/mr/SparkTest.jar /tmp/test.txt
spark-shell可以直接调试代码。
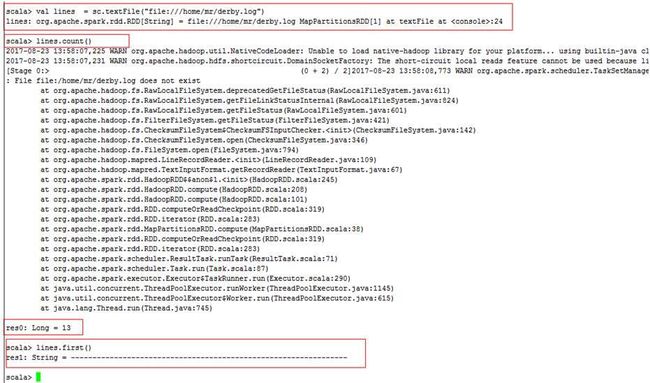
spark-sql可以直接调试SQL语句。

远程调试模式
Spark远程调试模式实际上利用的是JVM的远程debug调试。有时候Spark集群环境出现问题,当查看日志和WEB UI无法解决问题的时候,利用远程debug进行调试是一个十分快捷和有效的方式。
-Xdebug -Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=y
参数含义:
-Xdebug:告诉JVM运行在debug模式下
-Xrunjdwp:transport=dt_socket:指定连接方式(包括socket传输和内存传输两种,其中内存传输只支持Windows,而且内存传输不支持远程调试)
address=5006:JVM在5006端口上监听请求。
server=y:y表示启动的JVM是被调试者。如果为n,则表示启动的JVM是调试器。
suspend=y:y表示启动的JVM会暂停等待,服务端被挂起,直到调试器连接上。n表示JVM不会暂停等待。
客户端设置:
打开IntelliJIDEA工作台
选择“Run->Debug Configurations”菜单项
选择“Remote”,在右键弹出菜单中选择“New”
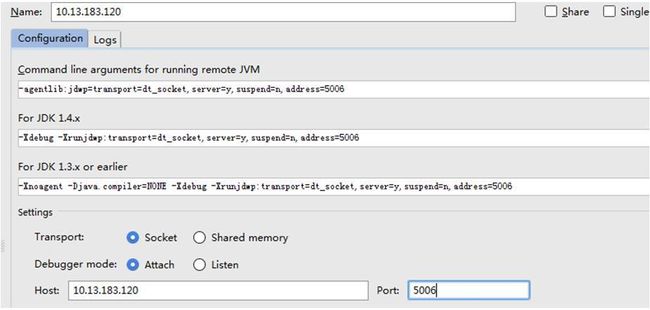
- 点击OK即可,就可以用本地的Spark代码调试Spark集群的功能。
服务器设置:
SPARK_MASTER_OPTS=-Xdebug-Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=n:调试Master的功能代码。
SPARK_WORKER_OPTS=-Xdebug-Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=n:调试Worker的功能代码。
SPARK_HISTORY_OPTS=-Xdebug-Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=n:调试History Server的功能代码。
spark-submit、spark-sql,spark-shell调试设置:
spark-submit、spark-sql,spark-shell配合spark.driver.extraJavaOptions和spark.executor.extraJavaOptions参数使用,可以远程调试Spark应用程序和GUI命令程序。如下:
spark-submit --classcom.zte.spark.example.WordCount --driver-java-options'-Xdebug -Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=n'--executor-memory 1G --total-executor-cores 3 /home/mr/SparkTest.jar /tmp/test.txt
spark-sql --executor-memory 1Gexecutor-cores 1 --driver-java-options '-Xdebug-Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=n'
spark-shell --executor-memory 1Gexecutor-cores 1--driver-java-options '-Xdebug-Xrunjdwp:transport=dt_socket,address=5006,server=y,suspend=n'
总结
我们在日常开发中,上述几种调试模式均需要熟练掌握并且合理使用。本地调试方式适合日常开发人员在本地开发,无需占用紧张的集群服务器环境,多个开发人员互不影响,本地调试在开发效率上也是最优的。服务器调试模式适合多个应用联调测试和集成测试,适合做性能测试。远程调试模式主要是解决难以定位的故障,实际证明,该方式也是定位问题最有效的手段之一