腾讯发表多模态综述,一文详解多模态大模型
多模态大语言模型(MLLM)是近年来兴起的一个新的研究热点,它利用强大的大语言模型作为大脑来执行多模态任务。MLLM令人惊讶的新兴能力,如基于图像写故事和无OCR的数学推理,在传统方法中是罕见的,这表明了一条通往人工通用智能的潜在道路。在本文中,追踪多模态大模型最新热点,讨论多模态关键技术以及现有在情绪识别上的应用。
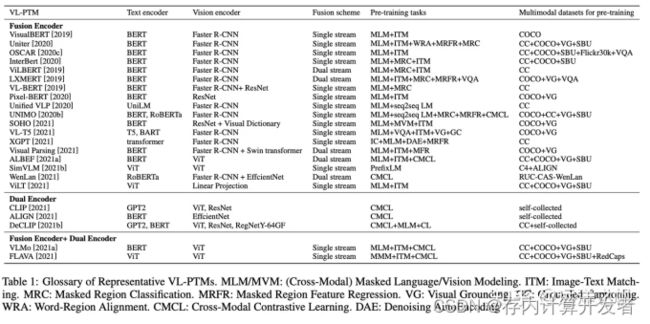
腾讯 AI Lab 发表了一篇关于多模态大模型的最新综述《MM-LLMs: Recent Advances in MultiModal Large Language Models》,整理归纳了现在多模态大模型的整体架构设计方向,并且提供了现有主流的 26 个多模态大模型的简介,总结了提升多模态大模型性能的关键方法,
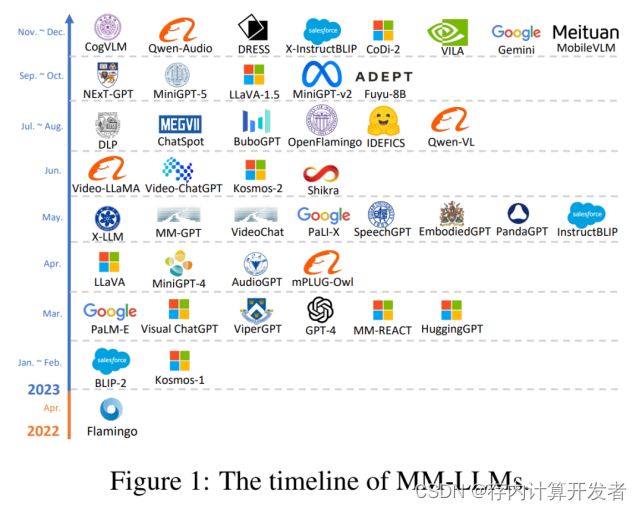
多模态大模型脱胎于大模型的发展,传统的多模态模型面临着巨大的计算开销,而 LLMs 在大量训练后掌握了关于世界的“先验知识”,因而一种自然的想法就是使用 LLMs 作为多模态大模型的先验知识与认知推动力,来加强多模态模型的性能并且降低其计算开销,从而多模态大模型这一“新领域”应运而生。
多模态大模型的整体架构可以被归类为如下图的五个部分,整个多模态大模型的训练可以被分为多模态理解与多模态生成两个步骤。多模态理解包含多模态编码器,输入投影与大模型主干三个部分,而多模态生成则包含输出投影与多模态生成器两个部分,通常而言,在训练过程中,多模态的编码器、生成器与大模型的参数一般都固定不变,不用于训练,主要优化的重点将落在输入投影与输出投影之中,而这两部分一般参数量仅占总体参数的 2%。
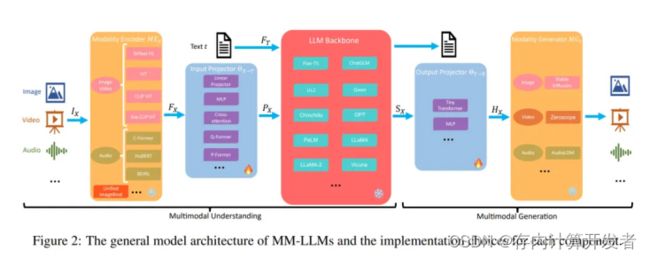
多模态大模型预训练的核心架构旨在整合和处理多种类型的数据模态,如文本、图像、音频等,以发掘不同模态间的深层关联并提升模型的表征能力【3】。以下是多模态大模型预训练的核心架构组件:
1.模态特定的编码器(Modality-Specific Encoders)
- 文本编码器:负责将文本数据转换为向量表示,通常采用Transformer或BERT架构。
- 图像编码器:处理图像数据,常使用卷积神经网络(CNN)来提取视觉特征。
- 音频编码器(如果有):处理音频数据,可能采用特定的音频处理网络,如WaveNet。

在得到模态特定的嵌入编码和位置编码之后,将其输入到共享参数的单模态编码器中,这些编码器由一系列Transformer的感知机块叠加构成,编码器可以同时接收多种模态的输入并生成统一的嵌入特征,方便后续的多任务和迁移学习训练。
2.跨模态融合层(Cross-Modal Fusion Layer)
- 用于整合来自不同模态编码器的特征表示,可能采用早期融合、晚期融合或中间融合策略。
- 融合层可能包括交叉注意力机制(Cross-Attention Mechanism),允许模型在不同模态间建立关联。
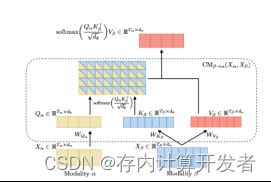
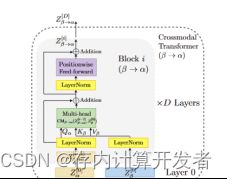
跨模态融合为核心部分,通过利用Transformer框架多头注意力中K、Q、V之间的运算关系实现情感状态的跨模态关注。与Transformer多头自注意力不同,Q为当前模态的序列,K、V为另外两种模态序列,矩阵相乘巧妙地将他们融合在一起,配合着叠加运算,最后拼接、Self-Attention融合完成跨模态学习。详细的运算过程可进一步分析本文的公式,或者结合Attention Is All You Need理解。
3. 主干网络(Backbone Network)
- 作为模型的核心,主干网络通常基于Transformer架构,用于进一步处理和融合来自不同模态的信息。
- 主干网络可能包含自注意力层和前馈网络,以增强模型对多模态数据的理解。
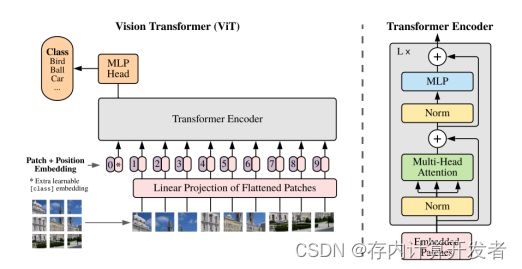
(1)将图片切成16x16的小块(patch),每个块转换为一个“词向量”,再加上位置编码;
(2)经过Transformer Encoder层
(3)分类层
4. 预训练任务(Pre-Training Tasks)
- 设计特定的预训练任务以训练模型,这些任务可能包括掩码语言模型(Masked Language Model)、图像-文本匹配、跨模态对比学习等。
- 预训练任务旨在让模型学习到丰富的跨模态表示,为下游任务提供强大的泛化能力。
在输入图像和文本编码为矢量并完全融合交互后,下一步设计预训练任务,这部分,我们将介绍一些广泛使用的预训练任务。
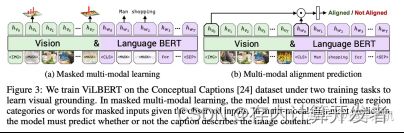
Cross-Modal Masked Language Modeling (MLM)
多模态MLM任务和nlp中bert模式很相似,通过MASK掉一部分的信息,通过没有MASK的信息来推理出MASK的表示。但与NLP不同地方在于,需要考虑如何设计学习任务。让多模态预训练模型不能只是单纯的依靠文本或者图像上下文信息就推理出MASK掉的表示是什么,而应该依赖与另外模态的信息才能推理出MASK的信息表示是什么。这样的任务设计才能让文本和图像信息之间产生关联,有上下文信息依赖,多到跨模态信息之间的对齐。
ViLT [Kim等人,2021年]采用了全字屏蔽策略,该策略防止模型仅通过周围文本信息就可以预测被MASK掉的信息表示;InterBERT [Lin等人,2020年]屏蔽了连续的文本片段,以使这预训练学习任务更加困难,并进一步改进了其在下游任务上的表现。

Cross-Modal Masked Region Prediction (MRP)
与MLM相似MRP也是通过对对部分信息MASK,通过没被MASK信息推测MASK的表示。MRP通过MASK掉一些ROI区域,然后根据其它图文信息预测出ROI区域信息表示。主要有两大类训练任务预测被MASK的区域是什么物体Masked Region Classification (MRC) 和预测被MASK区域的信息表示 Masked Region Feature Regression (MRFR) 。
Masked Region Classification (MRC)
MRC学习预测每个屏蔽区域的语义类,预测的是图像的更高层次的语意,而不是预测MASK部分每个像素。通过预测被MASK区域的是那个类,相当于在做object detect中的物体分类。用交叉熵方式来作为loss,通过没有被MASK的图文信息来预测被MASK区域可能是什么物体(做分类)。
Masked Region Feature Regression (MRFR)
MRFR通过未MASK区域的图文信息回归预测MASK区域的原始区域特征,MRFR要求模型重建高维向量,而不是语义分类。
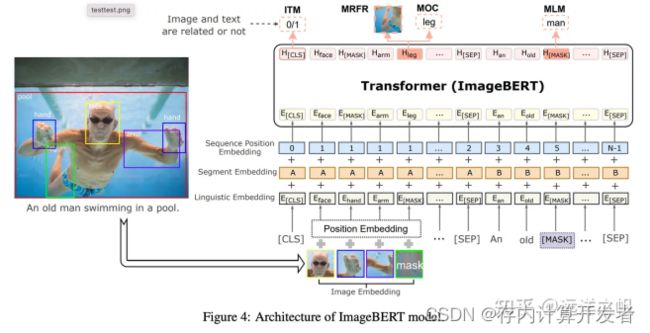
Image-Text Matching (ITM)
MLM和MRP帮助多模态预训练模型学习图像和文本之间的细粒度相关性,而ITM 为多模态预训练模型提供在粗粒度水平上对齐的能力。ITM类似NLP中预测上下两句话相似度的任务,给一对图文对预测他们之间是否匹配。
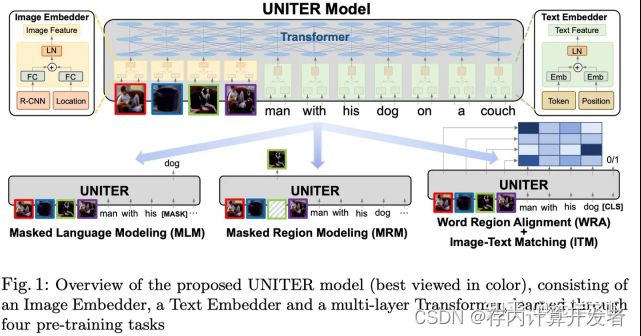
Cross-Modal Contrastive Learning (CMCL)
CMCL旨在通过将匹配的图像文本对的嵌入点推在一起,同时将不匹配的图像文本对分开,在同一语义空间下学习通用视觉和语言表达。有点类似nlp和cv里面的trip loss方式(比较学习),值得注意的是,CMCL中的对比loss是对称的,文本到图像的对比loss也类似。CLIP和ALIGN利用大规模的图像文本对来cmcl学习,并在图像分类任务表现出令人惊讶的zero-shot效果。
多模态预训练模型下游任务

下游任务包括理解和生成。
理解部分:

生成部分:
生成任务可以被认为是图像-文本的双重任务,生成任务可以分为文本到图像生成和图像到文本生成(多模式文本生成)。
5.多模态应用
以下是多模态大模型在表情识别和效价唤醒(VA)的应用,挑战要求参与者以时间连续的方式(即每0.25秒)预测情绪维度(即唤醒和效价)我们提出的方法主要由三个模块组成:预处理和特征提取模块、损失函数和融合模块。
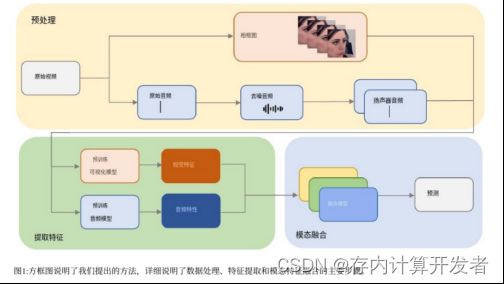
预处理和特征提取
在视觉方面,利用各种视觉预训练模型来提取裁剪对齐的人脸框架特征(即;, Clip-large, Resnet,
Senet, Eva02-large.)。这是因为人脸框架通常包含较少的噪声,并且更容易与来自其他模态的特征对齐。然后,我们使用单模态模型评估这些特征的性能,并选择表现最好的特征。
对于音频,我们对音频和音频内的单独扬声器采用去噪技术。随后,我们利用不同的预训练音频模型来提取音频特征(即:, Wavlm, Whisperv2, whisperv3)。一旦音频清晰,我们使用插值或卷积方法将音频特征与视觉特征对齐。
对于文本,基于我们的实验和之前ABAW比赛的结果,我们观察到文本模态的性能提升并不显著。因此,我们没有继续进行文本情态数据的进一步融合。
损失函数(Loss Function)
在机器学习和深度学习中,损失函数(Loss Function)是一个衡量模型预测值与实际值之间差异的函数。它用于训练过程中,指导模型通过调整参数来减小这种差异,从而提高模型的预测性能。损失函数的选择对模型的学习效果有着直接的影响。
多模态融合
多模态循环翻译网络(MCTN)是一种通过模态翻译学习鲁棒联合表示的神经网络模型。如图2所示,MCTN提供了两种模式的全面概述。该模型利用了一个基本概念,即从源模态XS到目标模态XT的转换会生成一个捕获两个模态之间联合信息的中间表示。记忆融合网络(MFN)是一种用于多视图顺序学习的循环模型,它包括三个主要组成部分: LSTM系统:多个LSTM网络,每个网络编码特定于视图的动态。Delta-memory Attention Network:用于发现跨视图交互的专门注意机制。多视图门控内存:存储跨视图交互随时间的记忆单元。图1概述了MFN管道和组件。MFN的输入是一个包含N个视图的多视图序列,每个视图的长度为t。例如,对于N = {1, v, a},序列可以由语言、视频和音频组成。第n个视图的输入数据去标注为:xn= [xtn: t≤t, xtn∈Rdxn]是第n个视图输入xn的输入维数。
参考来源:
- 组合主干网络带来目标检测新SOTA?北大等提出CBNet - 知乎
- 多模态预训练模型综述 - 知乎
- Multimodal Fusion with Pre-Trained Model Features in Affective Behaviour Analysis In-the-wildZhuofan Wen,Fengyu Zhang,Siyuan Zhang,Haiyang Sun,Mingyu Xu,Licai Sun,Zheng Lian,Bin Liu,Jianhua Tao
- 腾讯发表多模态大模型最新综述,从26个主流大模型看多模态效果提升关键方法