Hybrid Conditional Random Field based Camera-LIDAR Fusion for Road Detection
摘要
道路检测是自动驾驶汽车的主要挑战之一。道路检测通常使用两种传感器:摄像头和激光雷达。但是,它们每个人都有一些固有的缺点。因此,传感器融合通常用于结合这两种传感器的优点。尽管如此,当前的传感器融合方法还是由摄像机或激光雷达主导,而不是同时兼顾两者。在本文中,我们扩展了条件随机场(CRF)模型,并提出了一种新颖的混合CRF模型,以融合来自摄像机和LIDAR的信息。对齐LIDAR点和像素后,我们将像素和LIDAR点的标签(道路或背景)作为随机变量,并通过最小化混合能量函数来推断标签。学习增强的决策树分类器以预测像素和LIDAR点的成对。混合模型中的成对像素和点与点云(i)图像中的上下文一致性,(ii)点云中的上下文一致性以及(iii)对齐像素和LIDAR点之间的交叉模态一致性进行编码。该模型以概率方式集成了来自两个传感器的信息,并充分利用了两个传感器。混合CRF模型可以通过割图有效地优化以获得道路面积。在KITTI-ROAD基准数据集上进行了广泛的实验,实验结果表明,该方法优于当前方法。
1.简介
道路检测是自动驾驶汽车的基础研究课题,已经研究了数十年[11]。对于自动驾驶汽车,稳定和准确的道路检测是前提。由于公路,城市道路和乡村道路等不同类型的道路具有不同的特征,因此检测它们的方法也有所不同。在涂满油漆的高速公路上,道路检测可以用车道检测代替,这被认为要容易得多。但是,由于多种原因而检测正常的城市道路更具挑战性,例如路段之间的道路材料变化,道路区域和非道路区域之间的纹理和高度的相似性,照明和天气的变化以及以此类推。
为了实现准确和稳定的道路检测,已经开发了许多基于不同种类传感器的算法。最常用的传感器是单眼相机[4、15]和“光检测和测距(LIDARs)” [8],它们可以获取用于道路检测的各种信息。单目视觉捕获场景的透视投影,然后可以使用浓密的颜色和纹理将像素或超像素分组为道路和背景区域。但是,单眼视觉通常会遭受照明和天气变化的影响,并且无法捕获准确的3D信息。与视觉相比,激光雷达是一种有源传感器,它独立于环境光工作,并且可以精确地测量到物体的距离。但是,在激光雷达捕获的点云中,既没有颜色也没有纹理信息,并且这些点相当稀疏。
为了克服固有的缺点并结合不同类型传感器的优点,多模式传感器融合已被广泛使用[53、31、43、33、50]。对于道路检测,已经提出了几种相机-LIDAR融合方法。但是,它们中的大多数只由摄像机或激光雷达控制,无法充分利用两个传感器的优势。例如,在[43]中,在将LIDAR点云投影到图像上之后,用于障碍物分类的特征由LIDAR点的高度信息支配,而忽略像素信息。在[21]中,来自图像和激光雷达点云的信息以阶段的方式分别利用。LIDAR点云仅用于提取ground seed,而随后的道路检测和分割以图像为主。在[54]中,对特征和区域级别进行融合,从而导致融合粗略。所有这些方法都无法通过联合模型以精细的粒度融合图像和LIDAR。这项工作旨在填补这一空白。除了多模式信息外,另一种对提高性能至关重要的信息是每种模式中的上下文信息。考虑到条件随机场(CRF)在建模上下文信息中的优势[44],我们将CRF扩展到多模式设置,并提出了一种基于混合CRF的新型相机-LIDAR融合方法,以提高道路检测的性能。通过将道路检测公式化为二进制标记问题,将像素和LIDAR点的标记(道路或背景)作为随机变量,并构建了混合CRF模型来解决多模式标记问题。所提出的方法利用学习的增强决策树分类器来导出像素和LIDAR点的融合。通过成对像素和LIDAR点的相邻平滑先验以及对齐的LIDAR点和像素之间的一致性约束进行建模。该模型概率性地集成了来自两个传感器的信息,并且很好地利用了来自两个传感器的信息。混合CRF模型可以通过图割[23]进行有效优化,以获得道路面积。在KITTI-ROAD基准数据集上进行的实验[14]表明,所提出的混合CRF模型在融合多模式信息方面是有效的,并且与现有方法相比,道路检测的结果更好。
本文的主要贡献包括:(i)提出了一种融合图像和LIDAR点云的新型混合CRF模型,其中图像和LIDAR点云的上下文一致性以及交叉模式一致性的约束为(ii)将拟议的传感器融合框架应用于城市道路检测,并且我们的方法在KITTI-ROAD基准数据集上取得了良好的性能[14]。除了基于深度学习的方法外,我们基于UM子集的方法的结果在排行榜上排名第一[1],后者通常依赖于对额外数据进行预训练的模型进行初始化,而现代GPU则用于快速计算。
本文的其余部分安排如下。第2节回顾了道路检测的工作。第三部分显示了激光雷达点和图像的配准方式。在第4节中,我们首先介绍基于CRF的标记框架,然后提供有关所提出的混合CRF模型的详细信息。第5节介绍了像素和LIDAR点分类器的训练以及特征提取。在第6节中给出了在KITTI-ROAD基准数据集上测试的实验结果。最后,在第7节中列出了未来工作的结论和方向。
2.相关工作
作为开发自动驾驶车辆的基本问题,道路检测已被广泛研究。基于不同类型的传感器以及某些传感器类型的融合,已经开发了各种道路检测系统。
用于道路检测的最常用传感器是单眼相机[20]。通常将基于单目视觉的道路检测公式化为分类问题,即,将每个像素或超像素分类为道路或背景。许多机器学习方法已经应用于道路检测,例如高斯混合[10],支持向量机[2],极限学习机[55、30],神经网络[42],boosting [15]和struc建立随机森林[51]。近年来,许多新的特征学习方法已应用于道路检测,例如慢速特征分析[15],稀疏编码和字典学习[52、32、28、29],卷积神经网络[3、35]和深度反卷积网络[37]。基于分类的方法3独立地对每个单元进行分类,并且不考虑上下文的交互作用。因此,该预测可能是嘈杂的。为了解决这个问题,条件随机场(CRF)[50、19、45、41]被广泛用于建模上下文交互。通常,基于CRF的方法应该比基于简单分类的方法具有更好的性能。但是,当图像质量受到照明或天气条件的严重影响时,这些方法也可能会得到较差的结果。
LIDAR是自动驾驶汽车中另一种广泛使用的传感器。已经提出了多种基于LIDAR的道路检测算法,它们可以大致分为两类:基于回归的算法和基于分类的算法。基于道路区域连续性的假设,基于回归的算法利用一维曲线拟合[21,8]或二维曲面拟合[12,5]来分割道路。基于分类的算法提取点或网格单元的特征,然后基于某些直观规则或学习方法(例如高程图分析[46],高斯混合模型[26]和局部凸度准则[38])对它们进行分类。与基于图像的算法相似,可以采用马尔可夫随机场(MRF)对LIDAR点的上下文信息进行建模,以获得局部一致的结果。可以在网格图[17],圆柱网格图[7]或点的相邻图[40]上构建随机字段。简而言之,基于LIDAR的道路检测算法分析点云的3D信息,以获取无障碍区域作为道路。但是,在某些场景中,路边区域的高度与道路区域没有明显差异,因此这些方法可能会失败。
由于相机和LIDAR都有一些缺点,因此传感器融合成为克服每个单一传感模式固有缺陷的自然解决方案。近来,照相机-激光雷达融合已经被应用于道路检测。Shin zato[43]提出了一种简单有效的传感器融合方法来检测道路地形。该方法首先将LIDAR点投影到像面上,然后通过Delaunay三角剖分构造图。然后,将节点分为障碍和非障碍。最后,采用多个自由空间检测来获得图像平面中的密集道路区域。但是,该方法实际上并未利用任何像素信息。它仅使用交叉校准参数来将LIDAR点投影到图像平面上。Hu[21]提出了一种更直观的方法来融合来自激光雷达和相机的信息。采用平面估计来提取激光雷达点云中的地面点。将这些点投影到图像上,以学习照明不变图像特征的高斯模型,通过该模型对像素进行分类。该方法使用LIDAR点以阶段方式生成用于基于图像的分割的种子。换句话说,在第一阶段,仅使用LIDAR点云提取种子地面点。然后,在第二阶段,根据从种子像素学习的模型对图像进行分割,而LIDAR点云被完全丢弃。与分阶段方法相比,我们认为通过CRF框架同时对摄像机和LIDAR的信息进行联合建模将更加有益。
尽管CRF已广泛用于图像标记和LIDAR点云标记,但很少研究CRF融合来自多个传感器的信息的能力。在[54]中,图像和激光雷达点云融合被用于语义分割。但是,融合是在一元分类阶段完成的,CRF仅用作超像素标记的后处理。在[22]中,LIDAR点云首先被聚类以生成对象假设。然后采用CRF集成对象先验和空间约束进行像素分割。在[50]中,作者提出了针对图像和LIDAR点云的学习分类器,然后使用CRF集成了来自摄像机和LIDAR的观测结果。但是,在这些工作中,CRF模型以图像为主,而LIDAR点仅用作对已注册像素的附加观察或约束,以校正一元电势。本文扩展了他们的工作,以明确地建模相邻LIDAR点之间的上下文交互,以及在新型混合CRF框架中配准像素和LIDAR点之间的一致性约束。我们的方法以完全概率的方式集成了图像和激光雷达点云,因此,来自两个传感器的信息得到了很好的利用和融合。
3.图像和激光雷达点云对准
在本节中,我们简要介绍了图像和LIDAR点云的对齐方式。如[16]中所述,Velodyne HDL-64E激光雷达和摄像机安装在车辆的车顶上,并通过硬件触发器进行同步。一旦滚动的激光雷达面向前方,就会触发相机。相机和LIDAR经过交叉校准,因此可以通过将LIDAR点投影到图像平面上来使点云与图像对齐[16]。用![]() 表示LIDAR坐标中的3D点,首先将其转换为相机坐标
表示LIDAR坐标中的3D点,首先将其转换为相机坐标
![]()
其中![]() 是从LIDAR坐标到摄影机坐标的转换矩阵,而
是从LIDAR坐标到摄影机坐标的转换矩阵,而![]() 是整流旋转矩阵。
是整流旋转矩阵。
此步骤之后,将删除Z值为负的点。然后,剩余的点可以通过投影矩阵![]() 投影到像平面上。
投影到像平面上。
![]()
然后,可以通过![]() 获得LIDAR点p的投影像素坐标。请注意,在图像(FOV)之外的点也将被丢弃。图1显示了在典型的道路场景中由LIDAR捕获的点云和由摄像机捕获的图像,以及图像和点云的对齐方式。从融合视图中的树干上,可以看到图像和LIDAR点云对齐良好。
获得LIDAR点p的投影像素坐标。请注意,在图像(FOV)之外的点也将被丢弃。图1显示了在典型的道路场景中由LIDAR捕获的点云和由摄像机捕获的图像,以及图像和点云的对齐方式。从融合视图中的树干上,可以看到图像和LIDAR点云对齐良好。

4.基于混合CRF的Camera-LIDAR融合用于道路检测
在本文中,道路检测被公式化为二进制标记问题,即将感知数据标记为道路(1)或背景(0)。采用基于CRF的标签框架。所提出的方法是经典成对CRF的多传感器扩展。在本节中,我们首先简要介绍基于CRF的标签框架。然后,我们展示了如何使用新型的混合CRF模型将图像信息与LIDAR点云进行深度融合。
4.1基于CRF的标签
条件随机场(CRF)是一种概率图形模型,广泛用于解决标签问题。形式上,令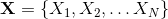 是要从观测Y推断出的离散随机变量。每个随机变量都可以从预定义集合
是要从观测Y推断出的离散随机变量。每个随机变量都可以从预定义集合![]() 。所有随机变量的任何可能分配都称为标记,并表示为x,它可以取
。所有随机变量的任何可能分配都称为标记,并表示为x,它可以取![]() 的值。根据给定的观察值,任务是推断最可能的标记:
的值。根据给定的观察值,任务是推断最可能的标记:![]() 。
。
CRF是在![]() 上定义的概率图形模型,其中
上定义的概率图形模型,其中![]() ,而
,而![]() 定义随机变量之间的相邻关系或连通性。集团
定义随机变量之间的相邻关系或连通性。集团![]() 是一组随机变量
是一组随机变量![]() ,它们在条件上相互依赖。根据Hammersley-Clifford定理[18],CRF标记上的后验分布
,它们在条件上相互依赖。根据Hammersley-Clifford定理[18],CRF标记上的后验分布![]() 是Gibbs分布,可以写成:
是Gibbs分布,可以写成:
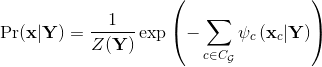
其中![]() 是在集团
是在集团![]() 上定义的势函数;
上定义的势函数;![]() 是最大团集合,
是最大团集合,![]() 是分区函数。因此,使概率
是分区函数。因此,使概率![]() 最大化等于使Gibbs能量函数最小化:
最大化等于使Gibbs能量函数最小化:
![]()
为了符号上的方便,在本文的其余部分中去掉了Y的约束。
在计算机视觉中,最常用的CRF模型是成对CRF,它仅考虑一元和成对集团:
![]()
使用上述基于CRF的标记框架,可以建立图像和点云域中的图形模型,并且可以通过模型推断来标记像素或LIDAR点。CRF具有建模上下文交互的能力,已成功应用于各种标记问题。但是,每种传感方式都有其固有的缺点。例如,照明会严重影响图像质量。如图9所示,道路上出现的大阴影很难识别。融合来自两个传感器的信息可以克服单个传感器的弊端并提高性能。为了利用CRF和传感器融合的优势,本文扩展了基于CRF的标记框架,以将图像和点云集成在混合CRF模型中。
4.2带有Camera-LIDAR融合的混合CRF
提出的混合CRF的详细信息如下。用第3节介绍的方法将图像和LIDAR点云对齐后,我们将图像像素(P)和LIDAR点(L)的标签作为随机变量投影到图像的视场上。因为道路检测被公式化为两类标签问题,所以每个随机变量都可以采用![]() 的值。对于相邻关系,考虑三种类型的边缘:(i)第一种是像素到像素边缘(
的值。对于相邻关系,考虑三种类型的边缘:(i)第一种是像素到像素边缘(![]() ),它们将像素与其8个相邻像素相连。(ii)第二个是相邻激光雷达点(
),它们将像素与其8个相邻像素相连。(ii)第二个是相邻激光雷达点(![]() )之间的边缘。实际上,可以使用3D欧式空间中的K近邻(K-NN)方法或approach近邻方法。在本文中,采用K = 6的K-NN方法。(iii)最后一种(
)之间的边缘。实际上,可以使用3D欧式空间中的K近邻(K-NN)方法或approach近邻方法。在本文中,采用K = 6的K-NN方法。(iii)最后一种(![]() )是对齐的LIDAR点和相应像素之间的交叉模态边缘,即在每个LIDAR之间添加一个边缘点和投影LIDAR点的像素。图形模型也显示在图2中。
)是对齐的LIDAR点和相应像素之间的交叉模态边缘,即在每个LIDAR之间添加一个边缘点和投影LIDAR点的像素。图形模型也显示在图2中。

图2:建议模型的图示。左上方是点云分类器的概率输出。左下角是像素分类器的概率输出。右上角是图像和LIDAR点云的融合视图。右下角是混合CRF的图形结构:绿色节点代表图像像素,红色节点代表LIDAR点,三种边缘EPP(像素到像素),ELL(LIDAR点到LIDAR点)和EPL(像素到LIDAR点)分别以绿色,红色和蓝色显示(有关详细信息,请参见文本)。
正式地,将混合CRF的要最小化的能量函数建模为
在此混合CRF模型中,分别在图像和点云域中构建了两个子CRF。子能量函数EP和EL与常规成对CRF模型的子能量函数相同,并且两个子模型的强度由参数γ平衡。实际上,对于基于像素的sub-CRF模型,主要采用Shotton的TextonBoost [44]框架。换句话说,一元电势采用学习的分类器的输出,而成对电势采用像素对比敏感的Potts模型。在本文中,一元势项![]() 采用由提升像素分类器预测的负对数似然性:
采用由提升像素分类器预测的负对数似然性:
![]()
成对的潜在项![]() 惩罚具有不同标签的相邻像素,如下所示:
惩罚具有不同标签的相邻像素,如下所示:
其中 是像素i的RGB值的矢量;
是像素i的RGB值的矢量; 是在图像样本上
是在图像样本上![]() 的期望。
的期望。![]() 是像素点i和j之间的欧几里得距离。注意,本文采用的是八邻系统,因此,对于水平或垂直连接的邻点,
是像素点i和j之间的欧几里得距离。注意,本文采用的是八邻系统,因此,对于水平或垂直连接的邻点,![]() 等于1,对角连接的邻居则等于√2。λ是控制成对项强度的参数。
等于1,对角连接的邻居则等于√2。λ是控制成对项强度的参数。
对于基于LIDAR点的子CRF模型,LIDAR点![]() 的一元势还采用了学习的分类器针对xi类预测的负对数似然性:
的一元势还采用了学习的分类器针对xi类预测的负对数似然性:
![]()
对于LIDAR点到LIDAR点的成对电位,采用距离感知的Potts模型。距离较小的相邻点被认为更有可能具有相同的标签。在本文中,潜在项的公式为:
其中pi是LIDAR点i的3D位置矢量,而ζ是控制强制闭合点采用相同标签的强度的参数。
对于像素至LIDAR点的成对邻点,采用基本的Potts模型:
![]()
其中η是控制将对齐的LIDAR点和像素约束为采用相同标签的强度的参数。
请注意,尽管相机和LIDAR在时间上是同步的并且经过交叉校准,但是在套准方面仍然存在一些不匹配的地方。然而,失配主要存在于物体的边缘附近,而在平坦的道路区域中,失配可忽略不计。此外,交叉模态势项对对准的LIDAR点和像素的标签一致性施加了软约束,而不是硬约束。整个混合CRF模型的推论将找到一个平衡所有潜在项的解决方案。因此,在建议的模型中,注册中存在的不匹配是可以接受的。
4.3。模型优化
提出的混合CRF模型的能量函数是亚模的,并且可以通过图割有效地推断出确切的最佳标记[23]。本文采用Boykov和Kolmogorov [6]提出的快速最大流量算法来解决能量最小化问题。
5.一元分类器训练
在最后一部分中,介绍了所提出的混合CRF模型的细节。在该模型中,像素和LIDAR点的一元电势是从学习到的分类器的输出中得出的。一元分类器的性能在整个模型中起着重要作用。在文学中,各种机器学习方法已应用于道路检测。Boosting是一种有效的训练方法,可以很好地概括未知样本[13]。对于这些desiderata,将提升用于一元分类器训练。
5.1。培训样本标签
由于图像和点云是同时使用的,因此必须同时标记图像和点云。虽然标记图像非常容易,但是标记点云的劳动强度更高。考虑到图像和点云已对齐,可以仅标记图像,然后将标记信息传输到相应的点云。
例如,我们实验中使用的KITTI-ROAD数据集[14]仅在图像域中标记。前述方案用于为LIDAR点生成地面真相标签。图3示出了标记结果的示例。

5.2特征提取
5.2.1图片特征
纹理滤镜库响应,局部二进制图案,密集HOG和颜色均按像素提取为图像特征。位置信息也包括在特征中。
•纹理滤镜库响应将图像转换为CIE-Lab颜色空间,然后将滤镜库应用于灰度图像或CIE-Lab图像的每个通道。实际上,将高斯滤波器应用于每个通道,而将水平和垂直高斯微分滤波器和高斯拉普拉斯滤波器应用于灰度图像。因此,对于给定的比例σ,为每个像素获得6维特征向量。在本文中,采用了三个比例尺,因此每个像素获得18维滤波器组响应。
•局部二进制图案提取了8个连接的相邻局部二进制图案特征以另外描述局部纹理。
•密集HOG为9个方向计算了密集的定向梯度直方图。
•颜色功能中包括每个像素的RGB通道。
•位置像素的位置对于道路检测很有用,因为道路总是出现在图像的下部。因此,像素的2D归一化x和y坐标也用作特征的一部分。
最后,为图像中的每个像素获得40维特征向量。然后将特征向量输入到分类器中,以获取每个像素是道路还是背景的概率。
5.2.2点云特征
对于点云特征,使用了几种常用的简单几何特征:
•3D位置3D位置用3D坐标表示,也没有用距离来表示。
•提取从点p的局部邻域估计的散射矩阵M的特征值表示为λ0<λ1<λ2的光谱特征,![]() 作为光谱特征[40]。
作为光谱特征[40]。
•方向特征通过M的主特征向量和最小特征向量估计局部切线向量和法线向量,并将这些向量用作方向特征。
因此,为每个激光雷达点获得了12维特征向量。
5.3分类器训练
通过标记数据并提取特征,可以训练分类器。在本文中,选择提升决策树作为图像和点云的分类器。迭代提升可以将强分类器作为弱分类器的总和。在本文中,将深度为d的决策树分类器作为弱分类器,将AdaBoost作为提升算法。每个弱分类器将特征向量表示hi(v),将其映射到二进制预测。经过AdaBoost的N次迭代后,学习到的强分类器H(v)是弱分类器的加权和:

强分类器为每个测试要素输出置信度值,以采用标签1(道路)和标签0(背景):
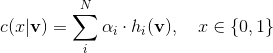
然后可以通过以下方式将置信度值重新解释为概率:
这些概率可用于获得混合CRF模型中的一元电势。
6.实验
6.1数据集
在本节中,我们对可公开获得的KITTI-ROAD数据集[14]进行一些实验,以验证所提出方法的性能。KITTI-ROAD数据集包含通过车载硬件同步摄像头和Velodyne HDL-64E LIDAR捕获的传感器数据。还提供了交叉校准参数,以将LIDAR点云注册到图像中。整个数据集包含从五个不同日期以相对较低的流量密度捕获的约600帧记录。根据驾驶环境,数据分为三个子类别:城市标记(UM),城市标记多车道(UMM)和城市未标记(UU)。它们每个都包含大约100个训练框架和100个测试框架。带注释的图像是为训练框架提供的,而测试数据的真实性则不是公开可用的,并且需要上传结果以进行在线评估。注释包含道路区域和自我通道。本文只研究道路检测,而忽略了我的车道信息。提供两种评估指标:一种是透视图中基于像素的评估,另一种是鸟瞰图(BEV)中基于行为的评估。性能指标包括误报率(FPR),误报率(FNR),精度(PRE),召回率(REC)和F1得分。考虑到某些方法的输出置信度图,最大F1分数(MaxF)和平均精度(AP)[14]也在官方开发工具包[1]中进行了计算。由于我们的方法采用二进制预测,因此MaxF等于F1分数,AP不太适合评估我们的方法。因此,在本文中,为了以官方方式评估结果,列出了MaxF和AP以与排行榜保持一致[1]。否则,将省略AP,并使用F1分数代替MaxF。
6.2参数设定
6.2.1分类器
我们首先测试增强型决策树分类器的性能。众所周知,弱分类器和AdaBoost的运行回合是提升的两个主要影响因素。以UM子集的像素分类为例,我们使用决策树深度和AdaBoost轮数(即树数)的不同配置进行2倍交叉验证。图4显示了不同参数配置下Precision,Recall和F1得分的变化。从图中可以看出,当我们使用更深的弱分类器并进行更多回合时,可以获得更好的F1分数。
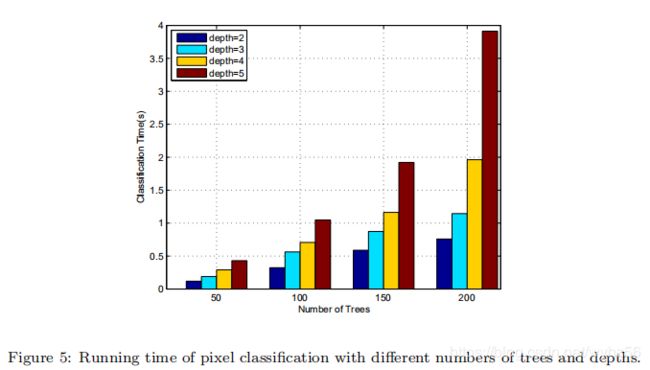
但是,相应的运行时间也会增加。因此,有必要在性能和效率之间找到平衡。图5中显示了针对不同数量的树和深度的测试时间。考虑到性能和效率,我们将100个深度为4的决策树作为像素和LIDAR点的强分类器。

6.2.2混合CRF参数
在混合CRF模型中,有几个参数控制着不同种类的潜在项的重要性。这些参数对所提出方法的性能有重大影响。同样,我们使用2倍交叉验证来搜索最佳参数。混合CRF模型是基于两个单峰成对CRF模型构建的。参数调整如下:首先,我们在基于像素的成对CRF模型中找到最佳的像素对像素成对权重λ。然后,在基于LIDAR点的成对CRF模型中调整LIDAR点到LIDAR点的成对项ζ的参数。然后固定最佳参数λ和ζ,并在混合CRF模型中调整其余两个参数γ和η。
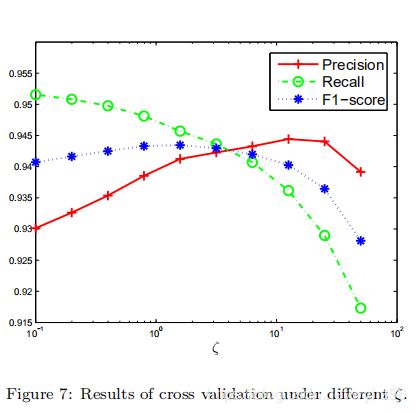
以UM子集为例,我们首先分别在基于像素的成对CRF和基于LIDAR点的成对CRF中分别调整参数λ和ζ。我们使用Precision,Recall和F1分数来评估不同参数设置的性能。结果如图6和7所示。通过图中所示的结果,我们可以选择具有最佳F1得分的参数λ和ζ。
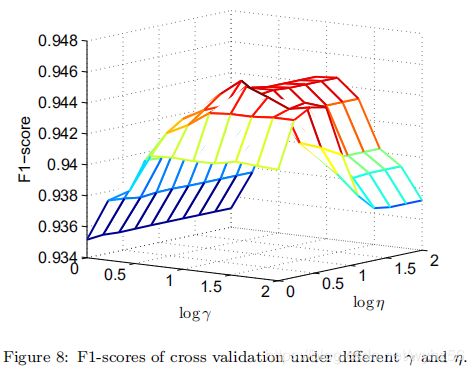
然后将这两个参数固定,并针对混合CRF模型中的γ和η的不同设置执行2倍交叉验证。图8显示了在不同参数设置下的F1得分。从图中可以看出,当参数从较小的值增长时,F1分数会增加,但是当参数增长太大时,F1分数会迅速下降。该图可以帮助我们选择具有最高F1分数的最佳γ和η。

6.3性能评估
为了评估所提出模型的性能,我们在KITTI-ROAD数据集上进行了几次比较实验。在第一个阶段中,我们将提供的具有真实性的训练图像随机分为两组,编号相同:一组用于训练,另一组用于测试。由于该方法是两个子CRF模型的组合模型,因此我们首先将其与单峰子CRF模型(基于像素的CRF和基于LIDAR点的CRF)进行比较。因为仅在图像域中提供了KITTI Road数据集的真实性,所以不适合评估基于LIDAR的方法。因此,我们分别将基于像素的CRF和基于LIDAR点的CRF与我们的方法进行比较。
对于基于像素的CRF,我们可以使用官方开发工具包对其进行评估,并将其与我们在图像领域中的方法进行比较。图9显示了通过像素CRF和提出的混合CRF获得的结果的示例,重叠的绿色区域表示检测到的道路。从图中可以看出,基于像素的成对CRF的结果受道路上投射的树木阴影的影响,而在提出的混合CRF中,融合了LIDAR点云,阴影的影响已经减少。
然后用[14]中引入的指标进行定量评估。此外,我们将像素分类器的输出(这也是λ= 0的基于像素的CRF的特例)作为基准。注意,这三个子集被分开处理。换句话说,没有来自一个子集的数据用于训练或测试其他子集。在透视图中执行评估。表1、2和3中显示了有关UM,UMM和UU子集的结果。
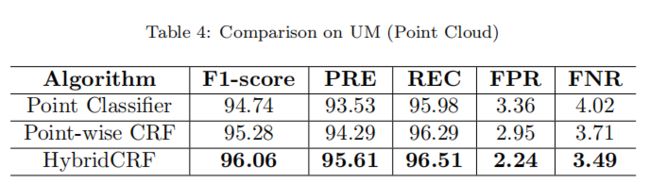
同样,使用基于LIDAR点的CRF进行相同的比较实验。根据LIDAR点方向精度评估性能,并通过套准将标签从地面图像转移到LIDAR点,从而获得地面标签。增强决策树分类器的输出也被当作另一个基线。表4、5和6列出了在UM,UMM和UU子集中测试的结果。
从表中显示的结果可以看出,通过对上下文信息进行建模,成对CRF模型可以提高基于像素或基于LIDAR点的分类器的性能。除了上下文信息之外,提出的混合CRF还可以在集成概率模型中融合多传感器信息。因此,推断出的标签比单峰CRF模型更准确。




通过验证优于单峰成对CRF模型的优越性,我们与最近开发的模型进行了一些对比实验。在这些实验中,每个子集中提供的所有训练数据及其真实性都用于学习该子集的分类器。参数采用通过上一节中的交叉验证获得的最佳值。结果将转换为鸟瞰(BEV),然后提交给网站进行评估。图10显示了在BEV中评估的测试图像的一些示例。可以在网站上找到更多结果[1]。
我们将建议的方法与排行榜上的高级方法进行了比较[1],包括HIM [39],SPRAY [24],BM [49],ProbBoost [48],HistonBoost [47],RES3D-Velo [43], FusedCRF [50],PGM-ARS [41],CB [36],StixelNet [27],NNP [9],SRF [51],FCN-LC [35]和MAP [25]。在这些方法中,有相机-LIDAR融合方法(RES3D-Velo和Fused CRF)和基于立体视觉的方法(HistonBoost,ProbBoost和NNP)。PGM-ARS和FusedCRF是也利用CRF的方法。FCN-LC和MAP是基于深度学习的方法,它们利用了功能强大的全卷积网络[34]。
表7、8、9和10列出了UM,UMM,UU子集的结果以及平均结果。最佳性能指标以粗体显示。请注意,我们方法的平均精度(AP)远比最佳方法差。原因是AP设计用于评估概率预测,而我们的方法输出二进制预测。因此,不适合以该指标进行评估。
[49]中也指出了这一点。有关这些方法的结果的更多详细信息,请向读者介绍网站[1]。从结果可以看出,该方法具有竞争力。特别是,它在UM和UU子集上获得了最佳的F1分数。但是,在UMM子集上的结果不佳。这可能是因为LIDAR点在道路更宽的UMM场景中变得稀疏了。因此,LIDAR信息的识别性降低了,尤其是在道路和人行道之间。然而,在整个数据集上,所提出的方法在这些算法中获得了最佳的F1分数。
另外,计算时间是开发和选择道路检测方法的重要因素。对于所提出的方法,计算成本包括特征提取和像素和激光雷达点的分类,图形的构建和裁剪。所提出的算法在标准单线程C ++中实现,并在具有8GB内存和时钟频率为2.6G Hz的Intel®Core™i5-3230M CPU的标准PC上进行了测试。在KITTI-ROAD数据集上测试的平均计算时间约为1.5秒。尽管当前实现的版本尚未实时使用,但在实时应用中,我们可以使用并行计算并对图像进行子采样以加速图像。
7.结论与未来工作
提出了一种基于单眼相机和多层激光雷达传感器融合的道路检测新方法。来自两个传感器的信息在混合条件随机字段中联合建模,在该条件下,像素和LIDAR点的标签被视为随机变量,并且边缘由以下连接组成:(i)im中相邻像素之间的连接年龄平面;(ii)3D空间中的相邻LIDAR点之间,以及(iii)对齐的LIDAR点及其对应像素之间。像素和LIDAR点的一元电势全部由离线学习的增强决策树分类器获得。成对电位可确保图像和点云的上下文一致性以及对齐的像素和LIDAR点之间的交叉模式一致性。所提出的方法将来自摄像头和激光雷达的信息融合在一起,有效地减少了道路检测中的模糊性。在KITTI-ROAD基准数据集上测试的实验表明,所提出的方法优于其他最近开发的方法。
将来,我们正在考虑采用更强大的深度学习方法来获得混合CRF模型的一元潜力,以进一步提高性能。我们还可以将算法移植到GPU等并行计算单元上以加速它。此外,混合CRF框架可以很容易地扩展到多类语义标记。我们相信,这种新颖的传感器融合模型比基于图像的语义标记方法可以实现更好的性能。