Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
所谓爬虫,就是通过编程的方式自动从网络上获取自己所需的资源,比如文章、图片、音乐、视频等多媒体资源。通过一定的方式获取到html的内容,再通过各种手段分析得到自己所需的内容,比如通过BeautifulSoup对网页内容进行解析提取。
本文通过selenium的webdriver模拟浏览器来浏览网页,通过lxml库解析得到咱所需的内容。下面开始我们的爬虫工作。
本文目录:
- 1.目标
- 2.实现
- 参考资料:
1.目标
本文目标是自动解析头条的视频新闻,通过第三方解析网站得到其真实的下载地址并自动下载到本地
*至于如何通过py自动解析、查看大咖个人中心的视频页签内容、自动翻页加载,请移步 《Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】》
我们查看央视网新闻这个大V的主页:央视网新闻
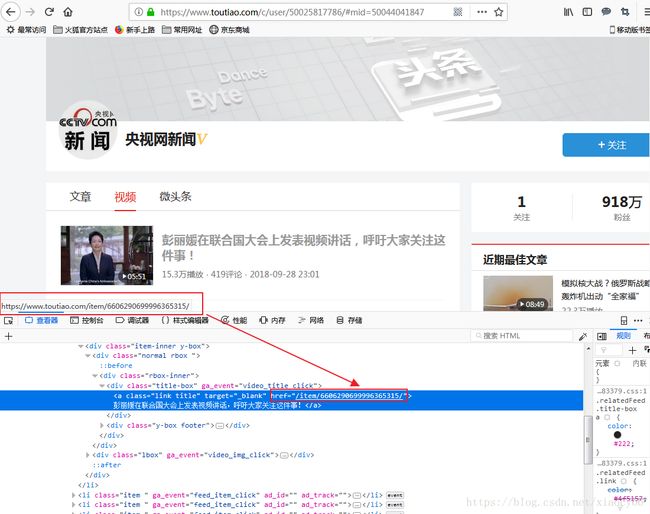
视频的播放地址是这样的:
https://www.toutiao.com/item/6606468202769678855/
显然这样的地址是无法直接下载的,真实的地址如何得到呢?这里我们就不重复造轮子了,直接通过第三方网站来实现:头条地址解析网站
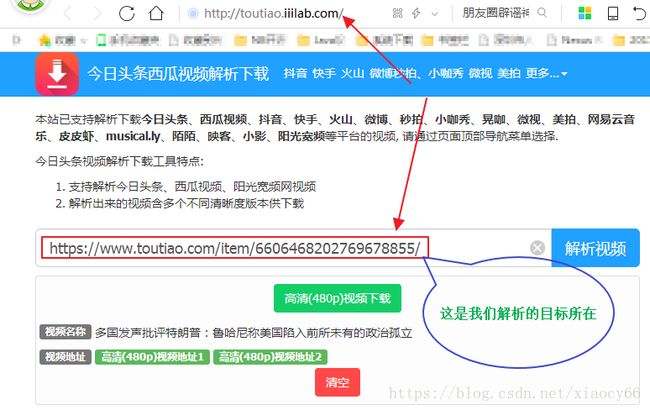
所以我们实际上只要从视频列表页面解析得到视频列表的
/item/视频id编号,然后通过selenium 驱动浏览自动输入到上面的解析网站,获取解析结果即可。
OK,思路有了,下面开搞~
2.实现
如何通过Python 编程获取视频列表内容? 请参考《Python3从零开始爬取今日头条的新闻》系列文章:
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
获取到一系列的头条视频内部地址后,通过浏览器模拟输入内部地址解析得到真实的下载地址。
这里讲下前几篇文章没遇到的一个场景:自动输入内容到浏览器的输入框,这个怎么实现呢?核心代码如下:def getRealPalyUrl(self, media_url, id, title, author):
# 查找视频地址输入框,自动输入内容
input_els = self.browser.find_element_by_xpath('//div[contains(@class, "input-group")]/input[contains(@placeholder, "请输入视频地址")][1]')
input_els.send_keys('http://www.toutiao.com' + media_url)
parse_btn = self.browser.find_element_by_xpath('//div[contains(@class, "input-group")]/div/button[contains(@class, "btn")][@type="button"][1]')
parse_btn.click()
try:
videoInfo = WebDriverWait(self.browser, 10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="thumbnail"]/div[@class="caption"]/p[1]/a'))
)
page = self.browser.page_source
page_etree = etree.HTML(page)
video_a = page_etree.xpath('//div[@class="thumbnail"]/div[@class="caption"]/p[1]/a[last()]')
if video_a and len(video_a) > 0:
video_a = video_a[0]
# 得到下载地址,视频清晰度描述
download_url = video_a.xpath('./@href')[0]
desc = ''
video_desc = video_a.xpath('./text()')
if video_desc and len(video_desc) > 0 and ('视频下载' in video_desc[0]):
desc = str(video_desc[0]).replace('视频下载', '')
# 保存到数据库
updateVideoInfo2DB(id, download_url, desc)
# 下载到本地
dl = DownloadFile()
dl.download(download_url, title, author)
except Exception as ex:
print(ex)
函数getRealPalyUrl(self, media_url, id, title, author): 的media_url 就是前面说的头条内部视频地址比如:/item/6606468202769678855/ ,
input_els = self.browser.find_element_by_xpath('//div[contains(@class, "input-group")]/input[contains(@placeholder, "请输入视频地址")][1]')
input_els.send_keys('http://www.toutiao.com' + media_url)
上面第一行是为了找到“请输入视频地址”这个输入框,第二行是模拟键盘输入完整的地址内容。
parse_btn = self.browser.find_element_by_xpath('//div[contains(@class, "input-group")]/div/button[contains(@class, "btn")][@type="button"][1]')
parse_btn.click()
上面第一行是为了找到 解析视频 这个按钮,然后模拟鼠标点击按钮向服务器发送请求。
如何使用xpath定位元素?请参考前文:Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
的2.1.3 章节的内容有详细介绍。
videoInfo = WebDriverWait(self.browser, 10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="thumbnail"]/div[@class="caption"]/p[1]/a'))
)
接下来这个代码是在点击解析视频按钮之后等待页面出现下载地址再进行下一步,这里是最多等待10s,一般情况下都足够了。后面就是解析得到具体的downloadurl了,然后通过这个真实的url下载到本地。其中用到的下载类DownloadFile的代码如下:
#!/usr/bin/python3
# -*- coding:utf-8 -*-
import os
import sys
import time
from urllib import request
class DownloadFile(object):
def __init__(self):
self.start_time = time.time()
'''
urllib.urlretrieve 的回调函数:
def callbackfunc(blocknum, blocksize, totalsize):
@blocknum: 已经下载的数据块
@blocksize: 数据块的大小
@totalsize: 远程文件的大小
'''
def __Schedule(self, blocknum, blocksize, totalsize):
speed = (blocknum * blocksize) / (time.time() -self.start_time)
# speed_str = " Speed: %.2f" % speed
speed_str = " Speed: %s" % self.__format_size(speed)
recv_size = blocknum * blocksize
# 设置下载进度条
f = sys.stdout
pervent = recv_size / totalsize
percent_str = "%.2f%%" % (pervent * 100)
n = round(pervent * 50)
s = ('█' * n).ljust(50, '-')
f.write(percent_str.ljust(8, ' ') + '█' + s + '█' + speed_str)
f.flush()
f.write('\r')
# 字节bytes转化K\M\G
def __format_size(self, bytes):
try:
bytes = float(bytes)
kb = bytes / 1024
except:
print("传入的字节格式不对")
return "Error"
if kb >= 1024:
M = kb / 1024
if M >= 1024:
G = M / 1024
return "%.3fG" % (G)
else:
return "%.3fM" % (M)
else:
return "%.3fK" % (kb)
def __downloadFile(self, url, folder, fileName):
print("正在下载: %s" % fileName)
print(url)
request.urlretrieve(url, folder + "\\" + fileName, self.__Schedule)
def download(self, url, title, author):
curFolder = 'H:\\py\\downloads\\' + author
if not os.path.exists(curFolder):
try:
os.makedirs(curFolder)
except Exception as ex:
print(ex)
else:
try:
# 下载文件
self.__downloadFile(url, curFolder, title + '.mp4')
except Exception as ex:
print(ex)
全文完结,后续实现用其它框架来爬虫新闻资源。敬请期待~
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
参考资料:
[1]: XPath语法参考
[2]: 廖雪峰老师的Python3 在线学习手册
[3]: Python3官方文档
[4]: 菜鸟学堂-Python3在线学习
[5]: 其他所有分享过python学习填坑网友的经验