本文主要是最近看了以下《tcp/ip详解 卷1》的部分小结,个人最感兴趣的是 经典问题 40ms 延时 的问题!
个人建议着重看19-24章节。每章都有干货。
单播、多播、广播、组播、泛播概念区分
参考
ICMP
ICMP的作用
- 差错控制
- “Ping”的过程实际上是ICMP协议工作的过程。还有其他的网络命令如跟踪路由的Traceroute命令也是
tcp
几个概念
msl 最长报文段存活时间
mss 最大报文段长度 ,主要是为了防止报文端被分段发送。 如果超过1mss 将会被分段发送。
定时器
- 重传定时器
- 坚持(presist)定时器 窗口探查
- 保活(keepalive)定时器 就是心跳检测
- 2MSL定时器 测量一个连接处于TIME_WAIT状态的时间。
-
状态流转

常见的情况,比如server关了,端口依然占用,其实就是处于TIME_WAIT状态 ,2MSL超时,用于超时重传最后的ack。
- 接收窗口和发送窗口的区别
接收窗口是接收方发给发送方的,(就是抓包看到的win= ),
发送窗口是由sender根据receiver的接收窗口以及当前已发送未ack的数据来自己计算的。tcp抓包看不到 - tcp 滑动窗口和拥塞窗口的区别
滑动窗口:滑动窗口不是真实存在的窗口,需要sender和recever共同作用。通告窗口(window offered by receiver) ,也就是我们抓包看到的win=xxx,是接收方使用的流量控制。

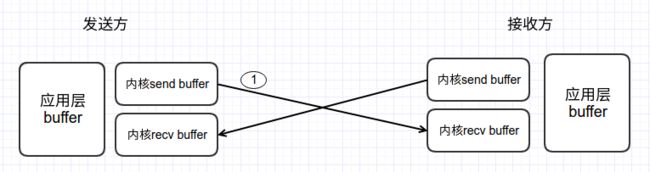
我们来分析一下1的情况,当sender 连续发送数据给receiver的时候,如果receiver的应用层来不及把数据从内核recv buffer拷贝到应用buffer,那么recv buffer会爆满,这时候receiver ack win=0。然后sender会把数据一直拷贝到send buffer而send buffer不发给receiver,直到receiver ack win> 0。
由此可见,通告窗口win就是recv buffer的剩余空间。
具体例子的分析可见 《tcp/ip 详解1》p213 。我们可以简单根据这个抓包的时序对滑动窗口进行分析。尤其我们看到 报文段8 win=3072.说明在receiver的recv buffer中还有1024个字节未被应用层buffer拷贝过去。因此在图2中可以看到的滑动窗口的通告窗口就是3072。

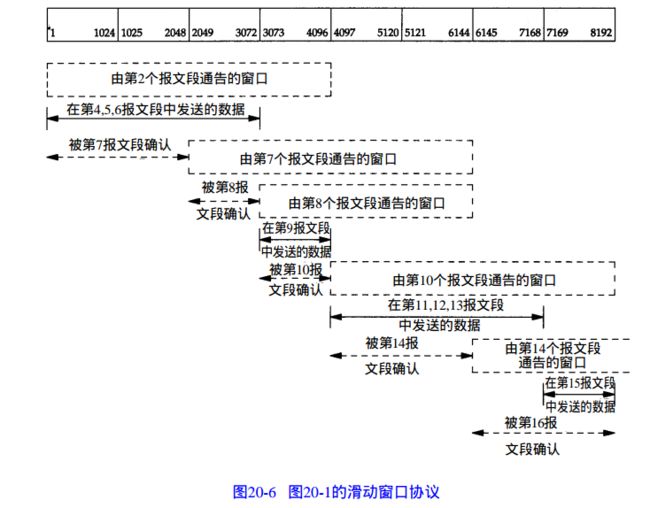
其实我们仔细想想看这里貌似存在一个缺陷,如果receiver win=0 之后 通告的win>0 的ack报文段(比如图1的报文段8)丢失了,那sender岂不是要一直等下去?
这个问题设计者早就发现了,采用了一个tcp坚持定时器。 sender周期性的向receiver 查询,以便发现窗口是否已经增大。 这些sender发出去的报文段叫做窗口探查。
**tcp window scale ** :
由于缓冲区大小在TCP头部只有16位来表示,所以它的最大值是65536,但是对于一些情况来说需要使用更大的滑动窗口,这时候就要使用扩展的滑动窗口,如光纤高速通信网络,或者是卫星长连接网络,需要窗口尽可能的大。这时会使用扩展的32位的滑动窗口大小。
shift count 在tcp三次握手的时候确认
最终的calculated window size =2^7 × 227 =128 * 227 都可在上面找到对应的数值。
拥塞窗口:是发送端维护的一个窗口,是发送方使用的流量控制。主要就是维护cwnd。下面可以看到分析。
慢启动和拥塞避免
超时重传采用“指数退避算法”
慢启动和拥塞避免是两个独立的算法,但通常一起作用。
需要维持的变量:
- 拥塞窗口 cwnd(默认初始化为1)
- 慢启动门限 ssthresh(默认初始化为65535字节)
拥塞算法:

当拥塞发生时(超时或收到重复确认) ssthresh被设置为当前窗口大小的一半( cwnd和接收方通告窗口大小的最小值,但最少为 2个报文段) 。此外,如果是超时引起了拥塞,则c w n d被设置为1个报文段(这就是慢启动) 。

前半段是慢启动(由cwnd=1开始可判断),后半段是拥塞避免。此时ssthresh是16个报文段大小。
拥塞避免的公式:

图中都是收到重复ack的 拥塞避免。从图中我们可以清晰的看到每个序号下降的地方就是一次重传,共有3处,而且每处都只有一个下落点,因此可以得出每处只重传了一个报文段。
对于cwnd的曲线,在每处发现重传后,就
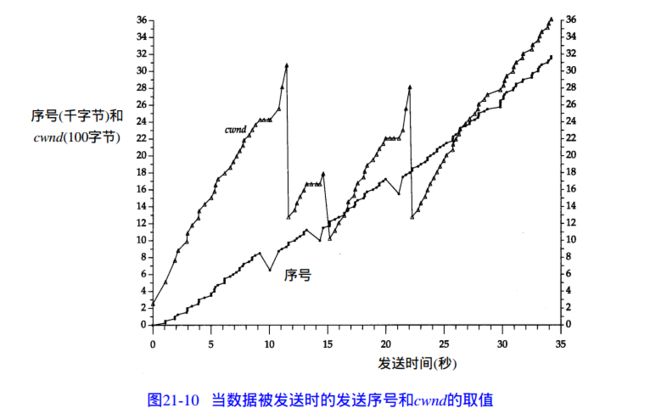
详细分析参看《tcp/ip详解》21章
延迟确认和Nagle算法
延迟确认:接收端收到数据之后,并不立即发送ACK确认收到数据,而是延迟发送ACK,等待一段时间,以期望和沿该方向传送的数据一起发送。是为了提高网络性能,因为少发了几次,然而,在某些情况下,该技术可以降低应用程序的性能。
Nagle算法:尽可能发送大块数据,避免使网络中充斥小分组,从而减少发送包的个数来增加网络的利用率。Nagle算法要求在任意时刻,最多有一个未被确认的分组,在收到确认之前,小分组将被缓存在发送端。直到缓存了一定量,等待了一定的时间,或者收到前一个数据的确认,才能发送出去。由TCP_NODELAY选项控制。
我觉得: 这两个主要是为了解决传输中 连续数据包都很小的情况,为了优化性能,而采用延迟确认和nagle,这样在发的时候可以屯多一点数据一起发,应答的时候,把数据和ack一起带过去。但是对于传输成块数据的情况就不太适用了,这两个默认都是打开的,要注意适时关闭!!,否则会带来数据传输延迟。所以一般我们实际工作中遇到由200ms以内的延时,可以怀疑下和tcp的延时ack,nagle算法有无关系。
经典问题 40ms 延时
产生条件
- 延迟确认与Nagle算法相互作用
- 延迟确认与拥塞控制相互作用
延迟确认与Nagle算法相互作用
- 延时ack
如果收到的数据内容大于一个MSS, 发送ACK;(大部分情况是这个)
如果收到了接收窗口以外的数据, 发送ACK;
如果处于quick mode, 发送ACK;
如果收到乱序的数据, 发送ACK;
其他, 延迟发送ACK
延迟ack其实是动态变化的,跟 Pingpong 这个值有关。
Pingpong是一个状态值, 用来标识当前tcp交互的状态, 以预测是否是W-R-W-R-W-R这种交互式的通讯模式(交互数据流), 如果处于(=1), 可以用延迟ack。
我们来看以下这个图。

当检测到是交互数据流时 ,Pingpong=1,启用了延时ack。当出现一个延迟纯ack时取消交互模式 Pingpong=0;
- Nagle算法
如果发送内容大于等于1个MSS, 立即发送;
如果之前没有包未被确认, 立即发送;
如果之前有包未被确认, 缓存发送内容;
如果收到ack, 立即发送缓存的内容。
如果该包含有FIN,则允许发送;
设置了TCP_NODELAY选项,则允许发送;
接下来分析以一下下面的情况:
1 00:44:37.878027 IP 172.25.38.135.44792 > 172.25.81.16.9877: S 3512052379:3512052379(0) win 5840
2 00:44:37.878045 IP 172.25.81.16.9877 > 172.25.38.135.44792: S 3581620571:3581620571(0) ack 3512052380 win 5792
3 00:44:37.879080 IP 172.25.38.135.44792 > 172.25.81.16.9877: . ack 1 win 46
......
4 00:44:38.885325 IP 172.25.38.135.44792 > 172.25.81.16.9877: P 1321:1453(132) ack 1321 win 86
5 00:44:38.886037 IP 172.25.81.16.9877 > 172.25.38.135.44792: P 1321:1453(132) ack 1453 win 2310
6 00:44:38.887174 IP 172.25.38.135.44792 > 172.25.81.16.9877: P 1453:2641(1188) ack 1453 win 102
7 00:44:38.887888 IP 172.25.81.16.9877 > 172.25.38.135.44792: P 1453:2476(1023) ack 2641 win 2904
8 00:44:38.925270 IP 172.25.38.135.44792 > 172.25.81.16.9877: . ack 2476 win 118
9 00:44:38.925276 IP 172.25.81.16.9877 > 172.25.38.135.44792: P 2476:2641(165) ack 2641 win 2904
10 00:44:38.926328 IP 172.25.38.135.44792 > 172.25.81.16.9877: . ack 2641 win 134
前三个报文段是三次握手,可以看出172.25.81.16.9877 为server,172.25.38.135.44792为client
4,5,6,7 是client和server互相交互数据流,并且8 出现了40ms延时ack,这个流程符合我们上面的流程分析。我们可看到延时ack是在client端开启了,server端开启了nagle算法。
在报文段5到达client时,client就知道了这是交互数据流,所以开启延时ack。当7发给client时,由于cleint并不需要发送什么数据给server,所以ack就一直等着定时器超时溢出,我们看到这时候延迟了40ms。
由于8报文段,即字节序号2476的ack一直没来,并且server端开启着nadle算法(如果之前有包未被确认, 缓存发送内容),所以报文段9 在收到8后才发。
40ms 这个是时间不同系统可能默认不同,rethat 默认40ms
解决延时的方案
对于这个例子而言
client
- client端关闭延迟ack
但是, 每个tcp请求都返回一个ack包, 导致网络包量的增加,需要斟酌 - 设置TCP_QUICKACK属性。 但是需要每次recv后再设置一次。
server
- 关闭nagel算法,即设置TCP_NODELAY。
staticvoid_set_tcp_nodelay(intfd) {
intenable =1;
setsockopt(fd, IPPROTO_TCP, TCP_NODELAY,(void*)&enable,sizeof(enable));
}
但这样会导致网络中出现很多小于1mss的报文段,因此最好能将这些小报文段先缓存起来,大于1mss的时候再发出去,这样这个mss 会被分段,1个正好是1mss,1个小于1mss,cilent连续收到这两个分段后,判断接受到的数据大于1mss,因此,立即发送ack。无延迟。
延迟确认与拥塞窗口相互作用
前提发送方(关闭Nagle),接收方(启用延时ack)
同样分析,即比如接收方mss大小1460 ,发送方连续发了三个数据大小为100的报文段,此时到达了拥塞窗口cwnd=3,不能在发送了,那么接收方接受到300<1460 ,所以接收方也会出现40ms延时ack。
缩短延时方案
参考 http://www.jianshu.com/p/6f795599e4ab * 为什么是40ms?这个时间能不能调整呢?* 这段。
【参考文章】
- http://www.jianshu.com/p/ca4f68be6664
- http://www.jianshu.com/p/6f795599e4ab
总结TCP的一些算法或者实现方式,在我们平常开发中的应用和可借鉴的地方
- 滑动窗口
- 超时重传
- 延迟确认和Nagle算法 :优化延时
[附送 好文推荐]
- http://www.cnblogs.com/promise6522/archive/2012/03/03/2377935.html
关注我的公众号,看更多好文!
