IPFS内部原理入门(An Introduction to IPFS)
原作:An Introduction to IPFS
作者:Dr. Christian Lundkvist, Director of Engineering, andJohn Lilic, ConsenSys Enterprise
翻译:伏神
原文地址:https://medium.com/@ConsenSys/an-introduction-to-ipfs-9bba4860abd0
(译文如有不妥之处,欢迎留言指正)

credit: Bogdan Burcea
“When you have IPFS, you can start looking at everything elsein one specific way and you realize that you can replace it all” — Juan Benet
走近IPFS,后面再谈技术(A Less Technical Approach to IPFS)
(本节原始作者John Lilic)
这一节我将尝试对IPFS做概况性描述,为我的同事Christian Lundkvist博士后面的深入技术总结提供铺垫。IPFS源于Juan Benet当初的一项工作尝试,其目的是建立一个系统能够快速移动版本化科学数据。版本控制使您能够跟踪软件的状态如何随时间变化(如Git)。自那时起,IPFS就被认为是分布式的、永久性的网络;“IPFS是一个分布式文件系统,它试图以同一个的文件系统将所有的计算设备连接起来。在某些方面,这类似于Web的原始目标,但是IPFS实际上更类似于一个的bittorrent集群,并在内部交换git对象。IPFS可以成为互联网的一个新的主要子系统。如果构建正确,它可以补充甚至替代HTTP。你没听错,它可以补充或替代更多东西。感觉像在吹牛B?它就是这么NB!”
IPFS本质上是一个版本化的文件系统,可以接收文件并管理、存储它们,随着时间的推移还能跟踪版本变化。IPFS也记录了这些文件是如何在网络中移动的,所以它也是一个分布式文件系统。
IPFS中的数据和内容在网络上移动的规则的与bittorrent相似。文件系统层提供了非常有趣的属性,例如:
- 完全分布式的网站。
- 没有源服务器的网站。
- 可以完全在客户端浏览器上运行的网站。
- 网站不必和任何服务器有联系。
内容寻址(Content Addressing )
IPFS不是引用存储在特定服务器上的对象(图片、文章、视频),而是通过文件内容对应hash值引用文件。可以这样理解,如果在你的浏览器中你想访问一个特定的页面,那么IPFS会问整个网络“有人有这个文件对应这个hash吗?”在IPFS就会有节点返回文件,此时你就访问到了它。
IPFS在HTTP层使用内容寻址。这是一项用以代替位置标识符寻址文件的实践,我们通过文件内容本身的特征来定位它。也就是说内容将决定地址。它的机制是用加密算法计算文件的hash值,这样就可以安全地将文件用很小数据量进行表示,这个hash值作为文件的地址,不会发生地址相同文件数据不同的情况。IPFS中文件的地址通常以一个散列开头,该散列标识某个根对象,然后沿着一条路径向下走(注:类似目录层次)。不同于传统服务器上的文件寻址操作,IPFS是先获得特定的对象,然后查看的是这个对象记录的路径。
HTTP vs. IPFS查找并获取文件(HTTP vs. IPFS to find and retrieve a file )
HTTP有一个很好的特性,在标识符中包含了位置信息,所以很容易找到托管文件的计算机并访问他们。这在通常的应用场景下很好用,但不包括离线情况,或是在用到了大型分布式系统,希望将通过整个网络分散负载的场景。
在IPFS中,只需要两步就能解决问题:
- 通过内容寻址识别文件。
- 查找文件——有了哈希,就可以向接入的网络询问“谁有这个内容? (哈希) ”,然后连接到相应的节点并下载它。
最终的效果就是通过点到点的覆盖(译者:图论中的覆盖?),获得高速的路由。
观看Alpha Video可以学习更多的内容。
例说IPFS (IPFS by Example )
(本节原始作者 Dr. Christian Lundkvist)
IPFS(星际文件系统)是一种经过良好测试和技术检验的互联网技术的综合体,包含了如DHTs、Git版本控制系统和Bittorrent等技术。它创建了一个允许交换IPFS对象的P2P集群。IPFS对象的总体构成了一个被称为Merkle DAG的密码验证数据结构,这个数据结构可以用来建模许多其他数据结构。我们将在本文中介绍IPFS对象和Merkle DAG,并给出可以使用IPFS建模的结构示例。
IPFS对象(IPFS Objects)
IPFS本质上是一个用于检索和共享IPFS对象的P2P系统。一个IPFS对象是一个具有两个字段的数据结构:
- Data—大小小于256 kB的非结构化数据块(blob)
- Links — 一个Link结构体的数组。其中包含的Link指向其他IPFS对象。
Link结构有三个数据字段:
- Name — Link的名字
- Hash — Link指向的IPFS对象的hash
- Size — Link指向对象的累计大小,计算Link指向的对象大小,需要计入这个被指对象所指向所有对象的大小(注:除了被指向对象自身的size,如果它里面有link,那么还要把link中的size加进来)
Size字段主要用于优化P2P网络,因为它不影响逻辑结构的概念表达我们将在这里忽略它。
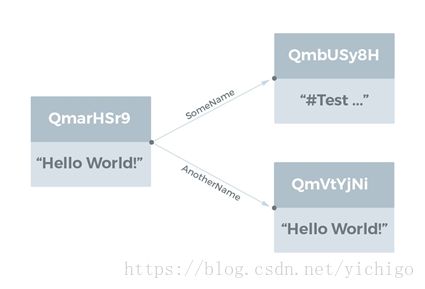
IPFS对象通常采用经Base58编码的散列引用。例如,观察hash为QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq的IPFS对象,可以使用命令行估计执行如下指令(需要读者亲自实践一下):
> ipfs object get QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq
{“Links”: [{
“Name”:“AnotherName”,
“Hash”:“QmVtYjNij3KeyGmcgg7yVXWskLaBtov3UYL9pgcGK3MCWu”,
“Size”: 18},
{“Name”:“SomeName”,
“Hash”:“QmbUSy8HCn8J4TMDRRdxCbK2uCCtkQyZtY6XYv3y7kLgDC”,
“Size”: 58}],
“Data”: “Hello World!”}
读者可能会注意到,所有的散列都是以“Qm”开头的。这是因为它实际上是一个multihash,前两个字节用于指定哈希函数和哈希长度。在上面的例子中,前两个字节的十六进制是1220,其中12表示这是SHA256哈希函数,20代表哈希函数选择32字节长度计算。
数据和命名链接构成的IPFS对象的集合即是Merkle DAG结构。顾名思义,DAG表明了这一种有向无环图,而Merkle说明这是一个密码验证的数据结构,使用加密哈希来寻址内容。读者可以思考为什么在这个图中不可能有环。
为了直观显示结构关系,我们将通过图表示IPFS对象关系,图的节点代表数据对象中的数据,图的边表示指向其他IPFS对象的链接,链接的名称是图的一条边上的标签。上面的示例可视化表示如下:
现在我们将给出可以由IPFS对象表示的各种数据结构的示例。
文件系统(Filesystems)
IPFS可以很容易地表示由文件和目录组成的文件系统。
小文件(Small Files)
IPFS对象表示一个小文件(< 256 kB)时,对象结构中的data是该文件内容(还需要在文件数据的开始和结尾处还要分别附加一小段header数据和一个footer数据),对象中不含链接,即Links数组是空的。注意,文件名称不是IPFS对象的一部分,因此两个具有不同名称和相同内容的文件将具有相同的IPFS对象表示,同样具有相同的hash值。
我们可以使用命令ipfs add向IPFS添加一个小文件:
chris@chris-VBox:~/tmp$ ipfs add test_dir/hello.txt
added QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoGtest_dir/hello.txt
我们可以使用ipfs cat查看上述IPFS对象的文件内容:
chris@chris-VBox:~/tmp$ ipfs cat QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
Hello World!
查看ipfs对象底层结构可以使用以下命令:
chris@chris-VBox:~/tmp$ ipfs object get QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
{“Links”: [],
“Data”: “\u0008\u0002\u0012\rHelloWorld!\n\u0018\r”}
该文件对象的可视化表示如下图:

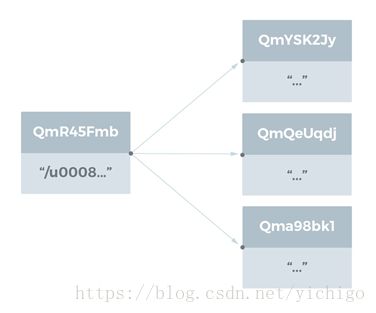
大文件(Large Files)
大文件(> 256kb)是由一个链接(Link)列表来表示的,列表中每个链接分别指向的是小于256 kB的文件块,于是只需用包含了很小的数据量的对象就能代表一个大文件。指向文件块的链接的name字段为空字符串。
chris@chris-VBox:~/tmp$ ipfs add test_dir/bigfile.js
added QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9wtest_dir/bigfile.js
chris@chris-VBox:~/tmp$ ipfs object get QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w
{“Links”: [{
“Name”: “”,
“Hash”: “QmYSK2JyM3RyDyB52caZCTKFR3HKniEcMnNJYdk8DQ6KKB”,
“Size”: 262158},
{“Name”: “”,
“Hash”: “QmQeUqdjFmaxuJewStqCLUoKrR9khqb4Edw9TfRQQdfWz3”,
“Size”: 262158},
{“Name”: “”,
“Hash”: “Qma98bk1hjiRZDTmYmfiUXDj8hXXt7uGA5roU5mfUb3sVG”,
“Size”: 178947}],
“Data”: “\u0008\u0002\u0018*\u0010 \u0010 \n”}
目录结构(Directory Structures)
目录由指向表示文件或其他目录的IPFS对象的链接(Link)列表来表示。链接的name字段是文件和目录的名称。例如,请考虑以下目录结构test_dir目录:
chris@chris-VBox:~/tmp$ ls -R test_dir
test_dir:
bigfile.js hello.txt my_dir
test_dir/my_dir:
my_file.txt testing.txt
test_dir
├─bigfile.js
├─hello.txt
└─my_dir
├─my_file.txt
└─testing.txt
其中的文件hello.txt和my_file.txt的内容同为字符串Hello World!\n。而文件testing.txt的内容为字符串Testing 123\n
将这个目录结构表示为一个IPFS对象图时,它看起来是这样的:
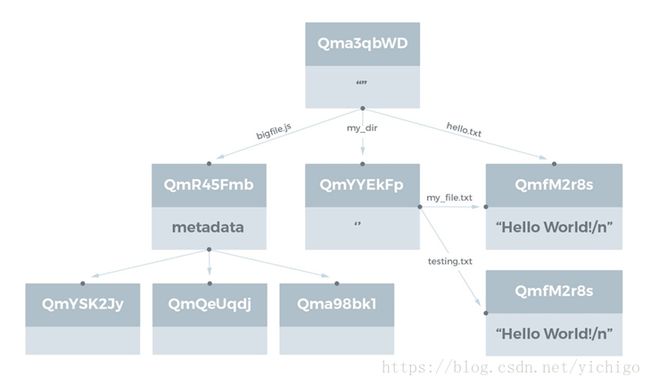
注意包含Hello World!\n的文件会被的自动去重,文件中的数据仅存储在IPFS中的一个逻辑位置(由其hash寻址)。
IPFS命令行工具可以无缝地跟踪目录链接名称来遍历文件系统:
chris@chris-VBox:~/tmp$ ipfs cat Qma3qbWDGJc6he3syLUTaRkJD3vAq1k5569tNMbUtjAZjf/my_dir/my_file.txt
Hello World!
版本化文件系统(Versioned File Systems)
IPFS可以表示Git所使用的数据结构,以支持版本化的文件系统。Git的提交对象(commit objects)在Git手册中被描述。IPFS提交对象的结构在撰写本文时没有完全指定,讨论仍在进行中。
IPFS提交对象的主要属性是,它包含一个或多个名称为parent0、parent1等链接,这些链接指向先前的提交;另外,还包含一个名字为object的链接(Git中称为树),指向该提交引用的文件系统结构。
我们以前面的文件系统目录结构为例,这里显示了两个提交(commit):第一个提交是原始结构,在第二个提交中,我们更新了文件my_file.txt,内容改成了Another World!而不是原来的Hello World!。
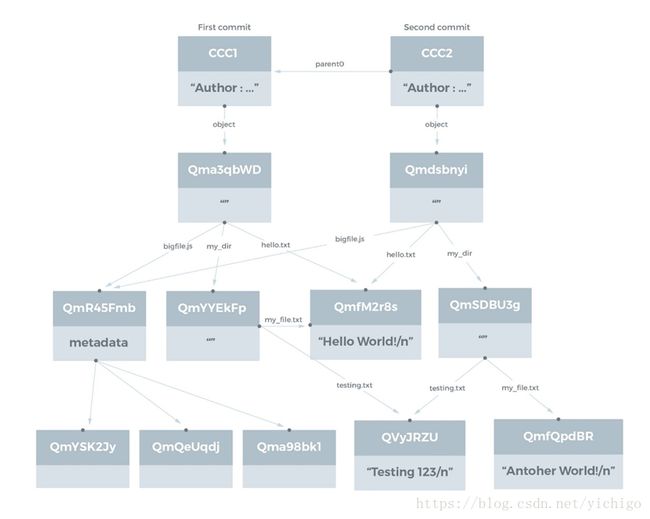
值得注意的是这里也发生了自动去重,因此第二个提交中的新对象只有主目录、新目录my_dir(译注:目录下的文件有变化,hash重新计算)和更新后的文件my_file.txt。
区块链(Blockchains)(译注:区块链不太了解,翻译可能会有错误,建议参考原文)
这是IPFS最令人兴奋的用例之一。区块链天然的拥有一个DAG结构,后续块总是通过前序块的hash值与他们相连接。像以太坊(Ethereum)这样的更高级的区块链也有一个关联的状态数据库,它有一个Merkl-Patricia树结构,也可以使用IPFS对象进行模拟。
我们假设一个区块链的简单模型,其中每个块包含以下数据:
- 交易对象列表
- 指向前一块的链接
- 状态树/数据库的hash值
这个区块链可以在IPFS中建模如下:
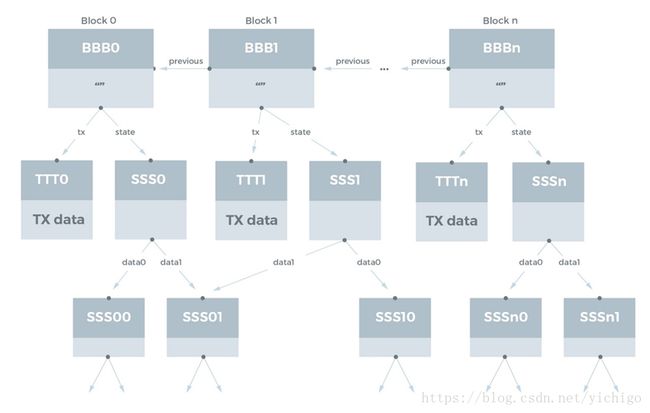
在将状态数据库放在IPFS上时,会发现重复数据——在两个块之间,只有已经更改的状态条目需要显式存储。
这里有趣的一点是,在区块链上存储数据和将数据的hash存储在区块链上的区别。在以太坊(Ethereum)平台上,为了最小化状态数据库的膨胀(bloat)(“区块链膨胀”),需要支付相当大的费用来存储相关的状态数据库中的数据。因此,对于更大的数据块来说,存储状态数据库中数据的IPFS hash,而不是存储数据本身,是一种常用的设计模式。
如果区块链及其相关状态数据库已经采用IPFS的方式表示,那么存储区块链上的hash还是储存区块链上的数据之间的区别也就不明显了,因为一切都是存储在IPFS,块的hash只需要状态数据库的hash。在这种情况下,如果有人在区块链中存储了一个IPFS链接,我们可以无缝地跟踪这个链接来访问数据,就好像数据存储在区块链本身中一样。
然而,我们仍然可以区分链上(on-chain)和链下(off-chain)数据存储。我们通过观察在创建新块时需要处理的问题来实现这一点。在当前的Ethereum网络中,矿工(miners)处理将交易(transaction)需要更新状态数据库。为了做到这一点,他们需要访问完整的状态数据库,以便能够在任何更改的地方更新它。
因此,在IPFS中表示的区块链状态数据库中,我们仍然需要将数据标记为“on-chain”或“off-chain”。为了能够挖矿,对于矿工来说“on-chain”数据本地保留是必要的,而这些数据直接受到交易的影响。“off-chain”数据必须由用户更新,不需要被矿工接触。