SQL项目-IOS 应用商店分析
IOS 应用商店分析
- 1. 简介
- 2. 数据理解
- 3. 建模分析
- 4. 总结与建议
1. 简介
背景信息
今天的苹果应用商店拥有上百万款手机软件,该数据集所含数据是找到以及分析最流行软件相关信息的关键。该数据集包含超过7000个苹果IOS系统手机软件的详细信息。数据从苹果公司官网的iTunes Search API中所提取
分析目的
App主要由哪些种类构成?
什么样的App是成功的?需要具备什么因素?
当下什么app最流行
2. 数据理解
数据来源
https://www.kaggle.com/ramamet4/app-store-apple-data-set-10k-apps
数据信息
app数量: 7917
数据元素数量: 15
数据取得时间: 2017年7月
数据样式
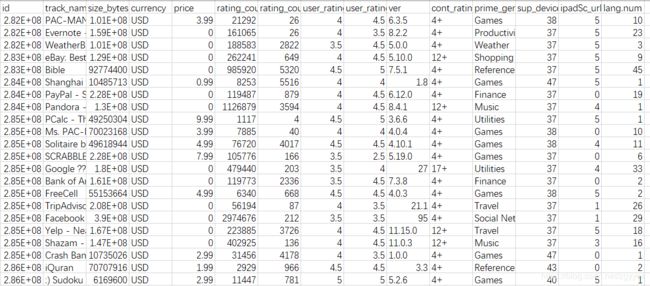
元素信息
- “id” : App ID
- “track_name”: App Name
- “size_bytes”: Size (in Bytes)
- “currency”: Currency Type
- “price”: Price amount
- “ratingcounttot”: User Rating counts (for all version)
- “ratingcountver”: User Rating counts (for current version)
- “user_rating” : Average User Rating value (for all version)
- “userratingver”: Average User Rating value (for current version)
- “ver” : Latest version code
- “cont_rating”: Content Rating
- “prime_genre”: Primary Genre
- “sup_devices.num”: Number of supporting devices
- “ipadSc_urls.num”: Number of screenshots showed for display
- “lang.num”: Number of supported languages
数据清理
1. 处理缺失值
select *
from applestore
where id is null
or track_name is null
or size_bytes is null
or price is null
or rating_count_tot is null
or rating_count_ver is null
or user_rating is null
or user_rating_ver is null
or ver is null
通过SQL查找发现数据集中无缺失值,若有缺失值将直接对其删除
2. 寻找异常值
通常可以使用Interquartile Range(IQR) 方法去寻找异常值。然而在该项目中无需去寻找处理异常值因为该项目中的异常值是对应用商店软件分析的关键。具体来说,一个软件若拥有异常大或异常小的点击率意味着这个软件非常的受欢迎或者过时已久。因此,理应花费更多的时间分析这些拥有异常值的软件成功或失败的原因。
基于该项目的特殊性,在此只对Genre一列中的数值变量进行了清理,因为其本身应该是文字而不是数字。
select count(prime_genre),prime_genre
FROM appstore
GROUP BY prime_genre
/*The code provides our information about the numeric values */
DELETE FROM appstore
WHERE prime_genre IN ('0','1','5','4','3','2')
/*Now I cleared all numeric values into prime_gen*/
3. 建模分析
- 总览
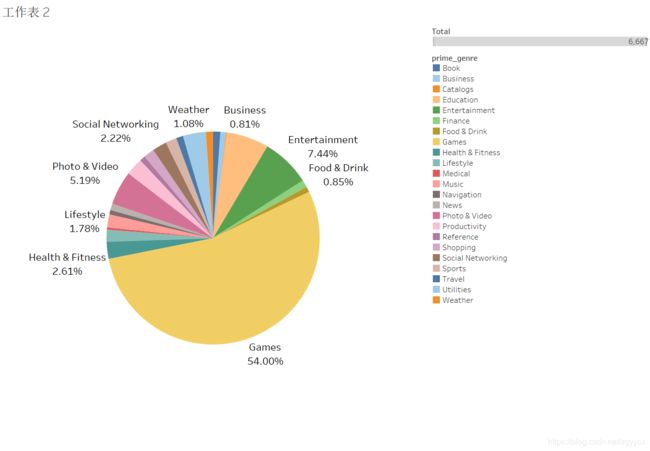
首先了解应用商店中app的类别构成
SELECT RANK() over (ORDER BY count(prime_genre) DESC) as Ranking,
prime_genre,count(prime_genre) as Total
from appstore
GROUP BY prime_genre
ORDER BY count(prime_genre) DESC
提取最流行的5类软件类型
UPDATE appstore
SET price='Unpaid'
WHERE price = 'Paid';
UPDATE appstore
SET price='Paid'
Where price !='Unpaid'; /*Transfer all price values into Paid and Unpaid categories*/
CREATE TABLE Paid
(SELECT prime_genre,COUNT(price) as Paid
from appstore
WHERE prime_genre in ('Games','Entertainment','Education','Photo & Video','Utilities')
AND price='Paid'
GROUP BY prime_genre);
CREATE Table Unpaid
(SELECT prime_genre,COUNT(price) as Unpaid
from appstore
WHERE prime_genre in ('Games','Entertainment','Education','Photo & Video','Utilities')
AND price='Unpaid'
GROUP BY prime_genre);
SELECT A.prime_genre,A.PAID,B.UNPAID
FROM PAID AS A JOIN UNPAID AS B
ON A.prime_genre=B.prime_genre;
对付费和不付费数据进行提取后,通过付费和不付费两类对软件类型进行分类
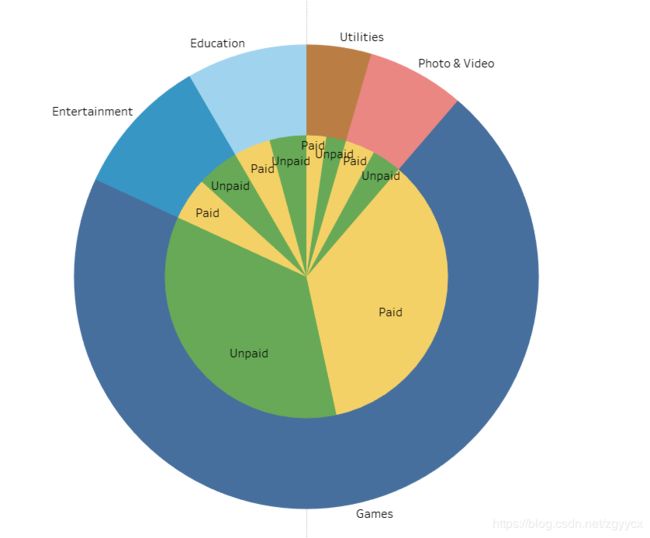
SELECT A.id,A.track_name,A.prime_genre,B.app_desc
FROM `applestore - 副本`AS A JOIN applestore_description AS B
ON A.id = B.id
WHERE A.id=B.id
提取对软件的相关评论,进行词云操作
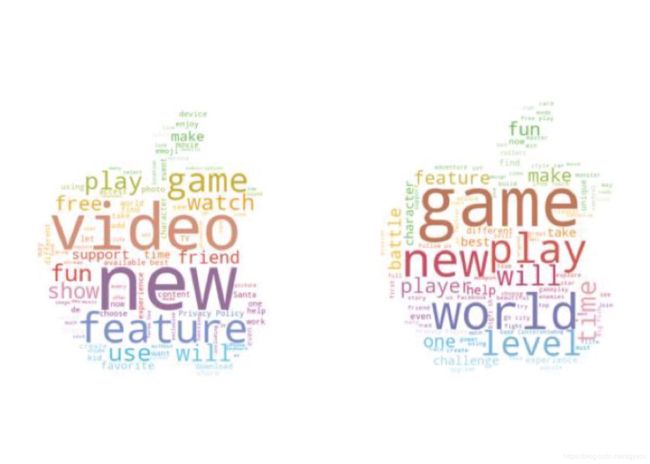
- 最成功的软件
import pandas as pd
import numpy as np
data = pd.read_csv(r'F:\R语言and Sql,Python\SQL Project\APP store 软件分析\appstore.csv')
data.head()
data1=data.loc[:,['rating_count_tot','rating_count_ver','user_rating','user_rating_ver','lang.num','sup_devices.num','ipadSc_urls.num']]
data1.head()
cor=np.array(data1.corr())
cor
dim = len(cor)
w = []
for i in range(dim):
m = cor
R = np.delete(np.delete(m,i,0),i,1)
r1 = np.delete(m[i,:],i)
r1 = r1.reshape(1,dim-1)
r2 = np.transpose(r1)
w.append(float(r1.dot(R).dot(r2)))
w = np.array(w)
deno = np.sum(np.divide(1,w))
for i in range(len(w)):
print('the weight of {} is {}.'.format(data1.columns[i],1/w[i]/deno))
/*
the weight of rating_count_tot is 0.3938887551227625.
the weight of rating_count_ver is 0.3919881700584351.
the weight of user_rating is 0.10563752423038358.
the weight of user_rating_ver is 0.10848555058841867.*/
SELECT id FROM,RatingTotal,Price
FROM
(SELECT id,track_name,((rating_count_tot-12665.81708)/75514.03075)
*0.39 as RatingTotal,
((rating_count_ver-450.5844102)/3907.931132)
*0.39 as RatingAvg,
((user_rating-3.649073)/1.413409)
*0.10 as UserRatingTotal,
((user_rating_ver-3.4196)/1.6932)
*0.10 AS UserRatingAvg
FROM appstore)
依据数据 the Total Rating, Average Rating, Total User Rating, Average User Rating, language 使用python参考相关系数评分方法建立了评分系统,找出了最成功的的10个软件


- 点击量前十软件
SELECT RANK() over (ORDER BY rating_count_tot DESC) as Ranking,
track_name as Name,
rating_count_tot as TotalRating
FROM appstore
ORDER BY rating_count_tot DESC


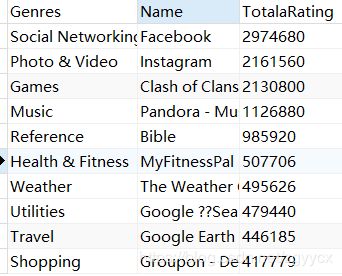
- 各类别中最流行的软件
SELECT DISTINCT prime_genre,track_name as Name,
MAX(rating_count_tot) as TotalRating
FROM appstore
GROUP BY prime_genre
ORDER BY rating_count_tot desc

4. 总结与建议
- 结合rating, rate, language 等数据建立了对App进行评分的标准
- 通过app相关数据,找出了最成功的,受欢迎的app
- 利用tableau sunburst, donut pie, wordcloud 等技术对数据进行了可视化
- 建议: 在建立了APP评分系统并找出最成功的的app后,可以在接下来的研究中对app description
data进行自然语言处理的研究,找到软件成功的共性