【整理】ABAP 7.40新特性介绍(上)
ABAP 7.40 Quick Reference
1. Inline Declarations - 内联声明
| Description |
Before 7.40 |
With 7.40 |
| Data statement |
DATA text TYPE string. |
DATA(text) = `ABC`. |
| Loop at into work area |
DATA wa like LINE OF itab. |
LOOP AT itab INTO DATA(wa). |
| Call method |
DATA a1 TYPE … DATA a2 TYPE … oref->meth( IMPORTING p1 = a1 IMPORTING p2 = a2). |
oref->meth( IMPORTING p1 = DATA(a1) IMPORTING p2 = DATA(a2) ). |
| Loop at assigning |
FIELD-SYMBOLS: LOOP AT itab ASSIGNING … ENDLOOP. |
LOOP AT itab ASSIGNING FIELD-SYMBOL( |
| Read assigning |
FIELD-SYMBOLS: READ TABLE itab ASSIGNING |
READ TABLE itab ASSIGNING FIELD-SYMBOL( |
| Select into table |
DATA itab TYPE TABLE OF dbtab. SELECT * FROM dbtab INTO TABLE itab WHERE fld1 =lv_fld1. |
SELECT * FROM dbtab INTO TABLE DATA(itab) WHERE fld1 = @lv_fld1. |
| Select single into |
SELECT SINGLE f1 f2 FROM dbtab INTO (lv_f1, lv_f2) WHERE … WRITE: / lv_f1, lv_f2. |
SELECT SINGLE f1 AS my_f1, F2 AS abc FROM dbtab INTO DATA(ls_structure) WHERE … WRITE: / ls_structure-my_f1, ls_structure-abc. |
2. Table Expressions - 内表读取
If a table line is not found, the exception CX_SY_ITAB_LINE_NOT_FOUND is raised. No sy-subrc.
如果找不到内表行,则触发异常CX_SY_ITAB_LINE_NOT_FOUND 。没有sy-subrc。
| Description |
Before 7.40 |
With 7.40 |
| Read Table index |
READ TABLE itab INDEX idx INTO wa. |
wa = itab[ idx ]. |
| Read Table using key |
READ TABLE itab INDEX idx USING KEY key INTO wa. |
wa = itab[ KEY key INDEX idx ]. |
| Read Table with key |
READ TABLE itab WITH KEY col1 = … col2 = … INTO wa. |
wa = itab[ col1 = … col2 = …]. |
| Read Table with key components |
READ TABLE itab WITH TABLE KEY key COMPONENTS col1 = … col2 = … INTO wa. |
wa = itab[ KEY key col1 = … col2 = …]. |
| Does record exist? |
READ TABLE itab … TRANSPORTING NO FIELDS. IF sy-subrc = 0. … ENDIF. |
IF line_exists( itab[ … ] ). … ENDIF. |
| Get table index |
DATA idx type sy-tabix. READ TABLE … TRANSPORTING NO FIELDS. idx = sy-tabix. |
DATA(idx) = line_index( itab[ … ] ). |
NB: There will be a short dump if you use an inline expression that references a non-existent record.
SAP says you should therefore assign a field symbol and check sy-subrc.
注意:如果使用内联表达式引用一个不存在的记录,则会出现Dump。SAP因此建议应该指定一个字段符号并检查sy-subrc。
ASSIGN lt_tab[ 1 ] to FIELD–SYMBOL(
IF sy–subrc = 0.
…
ENDIF.
NB: Use itab [ table_line = … ] for untyped tables.
注意:对于非类型化的表使用itab [ table_line = … ]
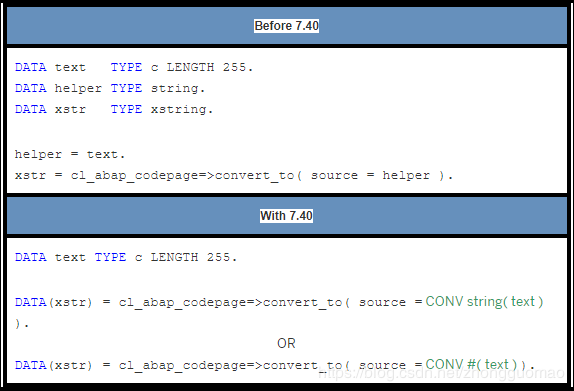
3. Conversion Operator CONV - 转换运算符CONV
- I. Definition
CONV dtype|#( … )
dtype = Type you want to convert to (explicit)
# = compiler must use the context to decide the type to convert to (implicit)
- II. Example
Method cl_abap_codepage=>convert_to expects a string
4. Value Operator VALUE - 值运算符VALUE
- I. Definition
变量Variables: VALUE dtype|#( )
结构Structures: VALUE dtype|#( comp1 = a1 comp2 = a2 … )
内表Tables: VALUE dtype|#( ( … ) ( … ) … ) …
- II. Example for structures
TYPES: BEGIN OF ty_columns1, “Simple structure
cols1 TYPE i,
cols2 TYPE i,
END OF ty_columns1.
TYPES: BEGIN OF ty_columnns2, “Nested structure
coln1 TYPE i,
coln2 TYPE ty_columns1,
END OF ty_columns2.
DATA: struc_simple TYPE ty_columns1,
struc_nest TYPE ty_columns2.
struct_nest = VALUE t_struct(coln1 = 1
coln2-cols1 = 1
coln2-cols2 = 2 ).OR
struct_nest = VALUE t_struct(coln1 = 1
coln2 = VALUE #( cols1 = 1
cols2 = 2 ) ).
- III. Examples for internal tables
Elementary line type:
TYPES t_itab TYPE TABLE OF i WITH EMPTY KEY.
DATA itab TYPE t_itab.
itab = VALUE #( ( ) ( 1 ) ( 2 ) ).
Structured line type (RANGES table):
DATA itab TYPE RANGE OF i.
itab = VALUE #( sign = ‘I’ option = ‘BT’ ( low = 1 high = 10 )
( low = 21 high = 30 )
( low = 41 high = 50 )
option = ‘GE’ ( low = 61 ) ).
5. FOR operator - FOR操作符
- I. Definition
FOR wa|
- II. Explanation
This effectively causes a loop at itab. For each loop the row read is assigned to a work area (wa) or field-symbol(
This wa or
that subroutine. Index like SY-TABIX in loop.
这样就高效的循环了内表itab。对于每个循环,读取的每一行行被分配给工作区(wa)或字段符号(
这里的wa或
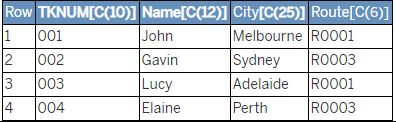
Given:
TYPES: BEGIN OF ty_ship,
tknum TYPE tknum, “Shipment Number
name TYPE ernam, “Name of Person who Created the Object
city TYPE ort01, “Starting city
route TYPE route, “Shipment route
END OF ty_ship.
TYPES: ty_ships TYPE SORTED TABLE OF ty_ship WITH UNIQUE KEY tknum.
TYPES: ty_citys TYPE STANDARD TABLE OF ort01 WITH EMPTY KEY.GT_SHIPS type ty_ships. -> 已填充如下值:
- III. Example 1
Populate internal table GT_CITYS with the cities from GT_SHIPS.

- IV. Example 2
Populate internal table GT_CITYS with the cities from GT_SHIPS where the route is R0001.
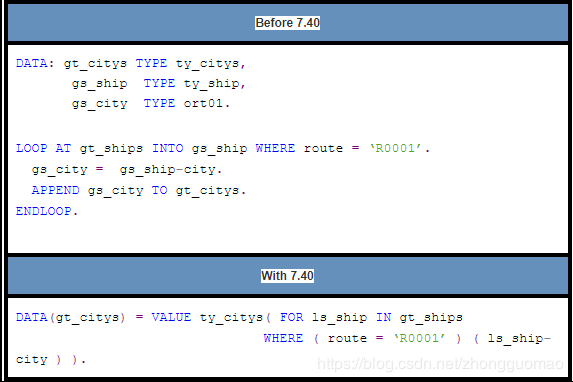
Note: ls_ship does not appear to have been declared but it is declared implicitly.
- V. FOR with THEN and UNTIL|WHILE
FOR i = … [THEN expr] UNTIL|WHILE log_exp
Populate an internal table as follows:
TYPES:
BEGIN OF ty_line,
col1 TYPE i,
col2 TYPE i,
col3 TYPE i,
END OF ty_line,
ty_tab TYPE STANDARD TABLE OF ty_line WITH EMPTY KEY.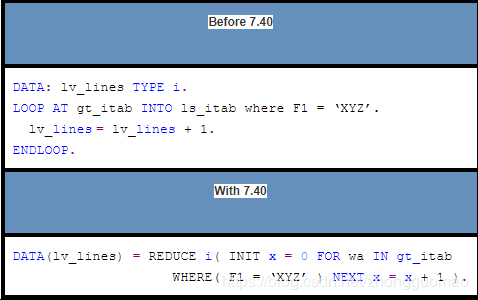
6. Reduction operator REDUCE - 缩减运算符REDUCE
- I. Definition
… REDUCE type(
INIT result = start_value
…
FOR for_exp1
FOR for_exp2
…
NEXT …
result = iterated_value
… )
- II. Note
While VALUE and NEW expressions can include FOR expressions, REDUCE must include at least one FOR expression. You can use all kinds of FOR expressions in REDUCE:
- with IN for iterating internal tables
- with UNTIL or WHILE for conditional iterations
虽然VALUE和NEW 表达式可以包含FOR表达式,但REDUCE必须至少包含一个FOR表达式。您可以在REDUCE中使用各种FOR表达式:
- 带IN用于迭代内表
- 有UNTIL 或者 WHILE的条件迭代
- III. Example 1
Count lines of table that meet a condition (field F1 contains “XYZ”).
计算满足条件的内表行数(字段F1包含“XYZ”的)。
- IV. Example 2
Sum the values 1 to 10 stored in the column of a table defined as follows
将存储在表中的值1和10相加,定义如下
DATA gt_itab TYPE STANDARD TABLE OF i WITH EMPTY KEY.
gt_itab = VALUE #( FOR j = 1 WHILE j <= 10 ( j ) ).
- V. Example 3
Using a class reference – works because “write” method returns reference to instance object

7. Conditional operators COND and SWITCH - 条件运算符COND 和SWITCH
- I. Definition
… COND dtype|#( WHEN log_exp1 THEN result1
[ WHEN log_exp2 THEN result2 ]
…
[ ELSE resultn ] ) …
… SWITCH dtype|#( operand
WHEN const1 THEN result1
[ WHEN const2 THEN result2 ]
…
[ ELSE resultn ] ) …
- II. Example for COND
DATA(time) =
COND string(
WHEN sy-timlo < ‘120000’ THEN
|{ sy-timlo TIME = ISO } AM|
WHEN sy-timlo > ‘120000’ THEN
|{ CONV t( sy-timlo – 12 * 3600 )
TIME = ISO } PM|
WHEN sy-timlo = ‘120000’ THEN
|High Noon|
ELSE
THROW cx_cant_be( ) ).
- III. Example for SWITCH
DATA(text) =
NEW class( )->meth(
SWITCH #( sy-langu
WHEN ‘D’ THEN `DE`
WHEN ‘E’ THEN `EN`
ELSE THROW cx_langu_not_supported( ) ) ).8. CORRESPONDING operator - CORRESPONDING 运算符
- I. Definition
… CORRESPONDING type( [BASE ( base )] struct|itab [mapping|except] )
- II. Example Code
TYPES: BEGIN OF line1, col1 TYPE i, col2 TYPE i, END OF line1.
TYPES: BEGIN OF line2, col1 TYPE i, col2 TYPE i, col3 TYPE i, END OFline2.
DATA(ls_line1) = VALUE line1( col1 = 1 col2 = 2 ).
WRITE: / ‘ls_line1 =’ ,15 ls_line1–col1, ls_line1–col2.
DATA(ls_line2) = VALUE line2( col1 = 4 col2 = 5 col3 = 6 ).
WRITE: / ‘ls_line2 =’ ,15 ls_line2–col1, ls_line2–col2,ls_line2–col3.
SKIP 2.
ls_line2 = CORRESPONDING #( ls_line1 ).
WRITE: / ‘ls_line2 = CORRESPONDING #( ls_line1 )’
,70 ‘Result is ls_line2 = ‘
,ls_line2–col1, ls_line2–col2, ls_line2–col3.
SKIP.
ls_line2 = VALUE line2( col1 = 4 col2 = 5 col3 = 6 ). “Restore ls_line2
ls_line2 = CORRESPONDING #( BASE ( ls_line2 ) ls_line1 ).
WRITE: / ‘ls_line2 = CORRESPONDING #( BASE ( ls_line2 ) ls_line1 )’
, 70 ‘Result is ls_line2 = ‘, ls_line2–col1
, ls_line2–col2, ls_line2–col3.
SKIP.
ls_line2 = VALUE line2( col1 = 4 col2 = 5 col3 = 6 ). “Restore ls_line2
DATA(ls_line3) = CORRESPONDING line2( BASE ( ls_line2 ) ls_line1).
WRITE: / ‘DATA(ls_line3) = CORRESPONDING line2( BASE ( ls_line2 ) ls_line1 )’
, 70 ‘Result is ls_line3 = ‘ , ls_line3–col1
, ls_line3–col2, ls_line3–col3.
- III. Output

- IV. Explanation
Given structures ls_line1 & ls_line2 defined and populated as above.
给定结构ls_line1和ls_line2的定义和填充如上所述。

1、The contents of ls_line1 are moved to ls_line2 where there is a matching column name. Where there is no match the column of ls_line2 is initialised.
当有匹配的列名时将ls_line1的内容移动到ls_line2。如果没有匹配项,则初始化ls_line2的列。
2、This uses the existing contents of ls_line2 as a base and overwrites the matching columns from ls_line1.This is exactly like MOVE-CORRESPONDING.
将ls_line2的现有内容作为基础,并根据ls_line1中的匹配列进行覆盖。这完全像MOVE-CORRESPONDING。
3、This creates a third and new structure (ls_line3) which is based on ls_line2 but overwritten by matching columns of ls_line1.
创建第三个新结构(ls_line3),该结构基于ls_line2,然后ls_line2被ls_line1的匹配列覆盖。
- V. Additions MAPPING and EXCEPT
MAPPING allows you to map fields with non-identically named components to qualify for the data transfer.
映射允许您映射名字不匹配的组件字段,以符合数据传输的条件。
… MAPPING t1 = s1 t2 = s2
EXCEPT allows you to list fields that must be excluded from the data transfer.
EXCEPT允许您列出必须从数据传输中排除的字段。
… EXCEPT {t1 t2 …}