数据库——SQL 中(数据查询)
目录
一、单表查询
1.1选择表中的若干列
1.1.1查询指定列
1.1.2查询全部列
1.1.3查询经过计算的值
1.1.4使用列别名改变查询结果的列标题
1.1.5更名运算
1.2选择表中的若干元组
1.2.1消除取值重复的行
1.2.2查询满足条件的元组
1.3 ORDER BY子句
1.4聚集函数
1.5 GROUP BY子句
二、多表查询
2.1等值连接与自然连接
2.2自身连接
三、嵌套查询
3.1概述
3.2带有 in谓词的子查询
3.3带有比较运算符的子查询
3.4带有 exists谓词的子查询
四、集合查询
4.1交运算
4.2并运算
4.3差运算
五、基于派生表的查询
select [ all|distinct ] <选择序列>
from <表引用>, ..., <表引用>
[ where <查询条件> ]
[ group by <分组列>, ..., <分组列> [ having <分组选择条件> ] ]
[ order by <排序列> [ ASC|DESC ], ..., order by <排序列> [ ASC|DESC ] ]
--select子句:指定要显示的属性列
--from子句:指定查询对象(基本表或视图)
--where子句:指定查询条件
--group by子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数
--having短语:只有满足指定条件的组才予以输出
--order by子句:对查询结果表按指定列值的升序或降序排序一个SQL查询的含义
- 为 from子句中列出的关系产生笛卡尔积
- 在步骤1的结果上应用 where子句中指定的谓词
- 对于步骤2结果中的每个元组,输出 select子句中指定的属性或表达式的结果
一、单表查询
查询的输入是 from子句中列出的关系,在这些关系上进行 where和 select子句中指定的运算,最终产生一个关系作为结果
1.1选择表中的若干列
1.1.1查询指定列
--找出所有教师所在系的系名
select dept_name
from instructor;1.1.2查询全部列
在 select关键字后面列出所有列名,或 将<目标列表达式>指定为 *,表示“所有属性”
--选中 instructor中的所有属性
select instructor.*
from instructor,teacher
where instructor.ID = teacher.ID;
--select * 表示 from子句结果关系的所有属性都被选中,即 instructor,teaches的所有属性都被选中1.1.3查询经过计算的值
select子句的<目标列表达式>可以是关系的属性,也可以是表达式,但不会导致对关系的任何改变
select salary-5000
from instructor;1.1.4使用列别名改变查询结果的列标题
select Sname aName, 'Year of Birth:' Birth, 2014-Sage Birthday, lower(Sdept) Department
from Student;
--aName,Birth,Birthday,Department是别名1.1.5更名运算
- from子句中的多个关系中可能存在同名的属性,导致结果中出现重复的属性名
- 如果在 select子句中使用算术表达式,结果属性就没有名字
- 想改变结果中的属性名字
as子句既可以出现在 select子句中,也可以出现在 from子句中
--对于大学中所有讲授课程的教师,找出他们的姓名以及所讲述的所有课程标识
select T.name, S.course_id
from instructor as T, teaches as S
where T.ID = S.ID;
--使用 as语句重命名结果关系中的属性:old_name as new_name
1.2选择表中的若干元组
1.2.1消除取值重复的行
SQL允许在关系以及SQL表达式结果中出现重复,如果想强行删除重复,可在 select后加入关键词 distinct,缺省为 all
select Sno
from sc;
--等价于
select all Sno
from sc;
--指定关键词 distinct后消除重复行
select distinct dept_name
from instructor;1.2.2查询满足条件的元组
| 常用查询条件 |
谓 词 |
| 比 较 |
=, >, <, >=, <=, !=, <>, !>, !<; not +上述比较运算符 |
| 确定范围 |
between … and …, not between … and … |
| 确定集合 |
in <值表>, not in <值表> |
| 字符匹配 |
[not] like ‘<匹配串>’ [escape ‘<换码字符>’] |
| 空 值 |
is null, is not null |
| 多重条件(逻辑运算) |
and, or, not |
select name
from instructor
where dept_name='Comp.Sci' and salary>70000;
1.3 ORDER BY子句
可以按一个或多个属性列排序
升序:ASC;降序:DESC;缺省值为 ASC
例:查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列
select Sno, Grade
from SC
where Cno='3'
order by Grade DESC;
1.4聚集函数
- 统计元组个数 count(*)
- 统计一列中值的个数 count([distinct | all] <列名>)
- 计算一列值的总和(此列必须为数值型)sum([distinct | all] <列名>)
- 计算一列值的平均值(此列必须为数值型)avg([distinct | all] <列名>)
- 求一列中的最大值和最小值 max([distinct | all] <列名>),min([distinct | all] <列名>)
sum和 avg的输入必须是数字集,其他运算符可作用在非数字数据类型的集合如字符串
1.5 GROUP BY子句
group by子句中给出的一个或多个属性用于构造分组,group by子句中的所有属性上取值相同的元组将被分在同一组
--找出每个系的平均工资
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name;分组情况: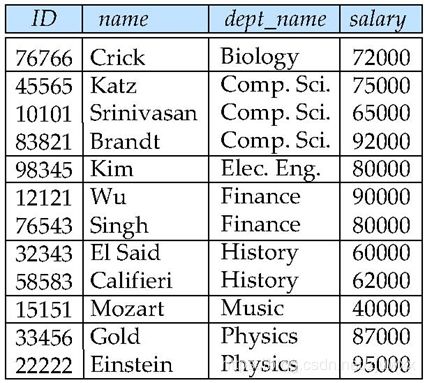 最终结果:
最终结果: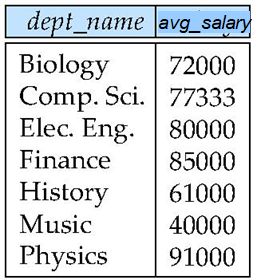
任何没有出现在 group by子句中的属性如果出现在 select子句中,只能出现在聚集函数内部,否则该查询错误
having短语与 where子句的区别
作用对象不同
where 子句作用于基表或视图,从中选择满足条件的元组
having 短语作用于组,从中选择满足条件的组
二、多表查询
同时涉及两个及以上的表的查询
2.1等值连接与自然连接
等值连接:关系R、S,取两者笛卡尔积中属性值相等的元组,例如 R.A=S.B,R.B=S.B
自然连接:特殊的等值连接。运算作用于两个关系并产生一个关系作为结果,在相同属性上进行相等比较,并投影去掉重复属性
列出属性的顺序:先是两个关系模式中的共同属性,然后是只出现在第一个关系模式中的属性,最后是只出现在第二个关系模式中的属性
--from子句中可以用自然连接将多个关系结合在一起
select A1, A2, … ,An
from R1 natural join R2 natural join … natural join Rm
where P;
2.2自身连接
自身连接:一个表与其自己进行连接
由于所有属性名都是同名属性,因此属性前必须给表起别名以示区别
例:查询每一门课的间接先修课(即先修课的先修课)
select first.Cno, second.Cpno
from Course first, Course second
where first.Cpno = second.Cno;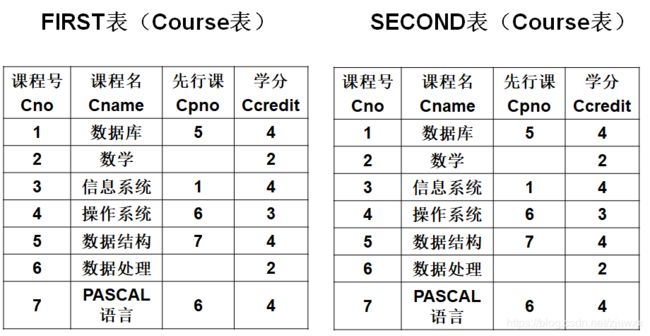
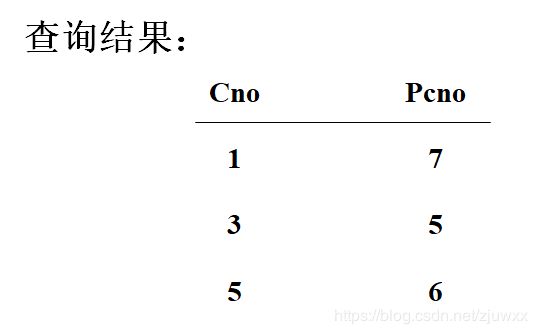
三、嵌套查询
3.1概述
一个 select-from-where语句称为一个查询块。将一个查询块嵌套在另一个查询块的 where子句或 having短语的条件中的查询称为嵌套查询
select Sname /*外层查询/父查询*/
from Student
where Sno in (
select Sno /*内层查询/子查询*/
from SC
where Cno= '2'
);- 上层的查询块称为外层查询或父查询
- 下层查询块称为内层查询或子查询
- SQL语言允许多层嵌套查询,即一个子查询中还可以嵌套其他子查询
- 子查询的限制:不能使用ORDER BY子句
相关子查询:子查询的查询条件依赖于父查询
- 首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处理内层查询,若 where子句返回值为真,则取此元组放入结果表
- 然后再取外层表的下一个元组
- 重复这一过程,直至外层表全部检查完为止
3.2带有 in谓词的子查询
谓词 in测试元组是否是集合中的成员,集合由 select子句产生的一组值构成
--找出在2009年秋季和2010年春季学期同时开课的所有课程
select distincy course_id
from section
where semester = 'Fall' and year = 2009 and course_id in (
select course_id
from section
where semester = 'Spring' and year = 2010
);in和 not in操作符能用于枚举集合
--找出"Mozart"和"Einstein"之外的老师
select distincy name
from instructor
where name not in ('Mozart','Einstein');
3.3带有比较运算符的子查询
当能确切知道内层查询返回单值时,可用比较运算符(>,<,=,>=,<=,!=或< >)
- “至少比某一个大”用 > some表示
--找出至少比 Biology系某一个教师的工资高的所有老师的姓名
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = 'Biology';
--注意这里 as语句的用法
select name
from instructor
where salary > some (
select salary
from instructor
where depr_name = 'Biology'
);- “比所有的都大”用 > all表示
--找出比 Biology系所有教师的工资都高的所有老师的姓名
select name
from instructor
where salary > all (
select salary
from instructor
where depr_name = 'Biology'
);
3.4带有 exists谓词的子查询
带有 exists谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”
- 若内层查询结果非空,则外层的where子句返回真值
-
若内层查询结果为空,则外层的where子句返回假值
由exists引出的子查询,其目标列表达式通常都用 * ,因为带exists的子查询只返回真值或假值,给出列名无实际意义
四、集合查询
intersect, union, except分别对应交、并、差运算,均可以自动去除重复,若想保留重复只需在后面加上 "all"
4.1交运算
--找出2009年秋季和2010年春季同时开课的所有课程
(
select course_id
from section
where semester = 'Fall' and year = 2009
)
intersect
(
select course_id
from section
where semester = 'Spring' and year = 2010
);
--结果中出现的重复元组数等于在 c1和 c2中出现的重复次数里最少的那个
4.2并运算
--找出2009年秋季开课,或2010年春季开课,或两个学期都开课的所有课程
(
select course_id
from section
where semester = 'Fall' and year = 2009
)
union
(
select course_id
from section
where semester = 'Spring' and year = 2010
);
--结果中出现的重复元组数等于在 c1和 c2中出现的重复元组数的和
4.3差运算
--找出2009年秋季开课但不在2010年春季开课的所有课程
(
select course_id
from section
where semester = 'Fall' and year = 2009
)
except
(
select course_id
from section
where semester = 'Spring' and year = 2010
);
--except运算从其第一个输入中输出所有不出现在第二个输入中的元组
--结果中出现的重复元组数等于在 c1中出现的重复元组数减去 c2中出现的重复元组数(前提是结果为正)
五、基于派生表的查询
子查询不仅可以出现在 where子句中,还可以出现在 from子句中,这时子查询生成的临时派生表成为主查询的查询对象
如果子查询中没有聚集函数,派生表可以不指定属性列,子查询 select子句后面的列名为其缺省属性
--找出系平均工资超过50000美元的那些系中教师的平均工资
select dept_name,avg_salary
from (
select dept_name,avg(salary)
from instructor
group by dept_name
)
as dept_avg (dept_name,avg_salary) --括号外是表名,括号内是属性名
where avg_salary > 50000;
--子查询的结果关系被命名为 dept_name,其属性名是 dept_name和 avg_salary