python 爬虫之scrapy(爬取猫眼电影)
1.scrapy简介
Scrapy 是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted ['twɪstɪd] (其主要对手是 Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy 架构图如下所示:绿线是数据流向。
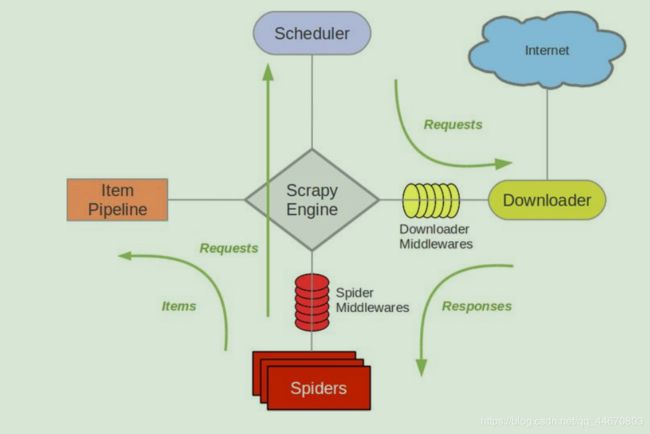
(1)Scrapy Engine(引擎): 负责 Spider、ItemPipeline、Downloader、Scheduler 中间的
通讯,信号、数据传递等。
(2)Scheduler(调度器): 它负责接受引擎发送过来的 Request 请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
(3)Downloader(下载器):负责下载 Scrapy Engine(引擎)发送的所有 Requests 请求,并将其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 来处理,
(4)Spider(爬虫):它负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器),
(5)Item Pipeline(管道):它负责处理 Spider 中获取到的 Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
(6)Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
(7) Spider Middlewares(Spider 中间件):你可以理解为是一个可以自定扩展和操作引擎和 Spider 中间通信的功能组件(比如进入 Spider 的 Responses;和从 Spider 出去的 Requests)
2.Scrapy 的运作流程
代码写好,程序开始运行…
- 引擎:Hi!Spider, 你要处理哪一个网站?
- Spider:老大要我处理 xxxx.com。
- 引擎:你把第一个需要处理的 URL 给我吧。
- Spider:给你,第一个 URL 是 xxxxxxx.com。
- 引擎:Hi!调度器,我这有 request 请求你帮我排序入队一下。
- 调度器:好的,正在处理你等一下。
- 引擎:Hi!调度器,把你处理好的 request 请求给我。
- 调度器:给你,这是我处理好的 request
- 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个 request 请求
- 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个 request 下载失 败了。然后引擎告诉调度器,这个 request 下载失败了,你记录一下,我们待会儿再 下载)
- 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了, 你自己处理一下(注意!这儿 responses 默认是交给 def parse()这个函数处理的)
- Spider:(处理完毕数据之后对于需要跟进的 URL),Hi!引擎,我这里有两个结 果,这个是我需要跟进的 URL,还有这个是我获取到的 Item 数据。
- 引擎:Hi !管道 我这儿有个 item 你帮我处理一下!调度器!这是需要跟进 URL 你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 管道``调度器:好的,现在就做!
注意:只有当调度器中不存在任何 request 了,整个程序才会停止(也就是说,对于下载失败的 URL,Scrapy 也会重新下载。)
创建项目:
scrapy startproject 项目名
创建一个spider文件
scrapy genspider 文件名 网站地址
运行spider:
scrapy crawl name --nolog
3.制作 Scrapy 爬虫 一共需要 4 步
(1)新建项目 (Scrapy startproject xxx):新建一个新的爬虫项目
(2)明确目标 (编写 items.py):明确你想要抓取的目标
(3)制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
(4)存储内容 (pipelines.py):设计管道存储爬取内容
4.scrapy写项目的步骤
1.scrapy startproject 项目名
2.scrapy genspider 文件名 网站地址
3.设置settings里面的:
robots协议
DEFAULT_REQUEST_HEADERS把urse_agent设置进去
4.写spider里面的内容了。
(1)确定需要爬取的url
start_urls = []
(2)在parse方法里面来测试一下response是否能获取
(3)解析数据
(4)在items这个文件中定义我们需要截取的数据的名称。
title = scrapy.Field()
comment = scrapy.Field()
(5)在parse方法里面先实例化item
item = QiushiItem()
(6)获取数据
item['title'] = title
item['comment'] = comment
(7)yield item
5.piplines.py中处理item
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
collection_name = item.__class__.__name__
print(collection_name)
self.db[collection_name].insert(dict(item))
return item
6.在settings中设置:
MONGO_URI = 'localhost'
MONGO_DATABASE = 'qiushi'
打开:
ITEM_PIPELINES = {
'qiushi.pipelines.MongoPipeline': 300,
}
5.scrapy示例(爬取猫眼电影)
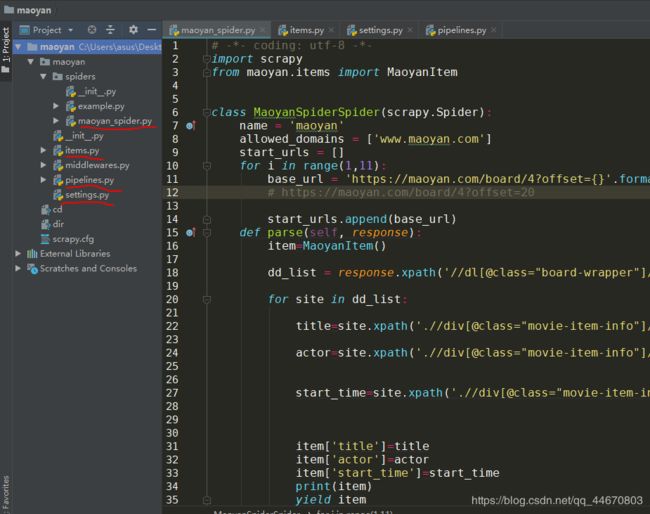
maoyan_spider.py文件:
import scrapy
from maoyan.items import MaoyanItem
class MaoyanSpiderSpider(scrapy.Spider):
name = 'maoyan'
allowed_domains = ['www.maoyan.com']
start_urls = []
for i in range(1,11):
base_url = 'https://maoyan.com/board/4?offset={}'.format((i-1)*10)
# https://maoyan.com/board/4?offset=20
start_urls.append(base_url)
def parse(self, response):
item=MaoyanItem()
dd_list = response.xpath('//dl[@class="board-wrapper"]/dd')
for site in dd_list:
title=site.xpath('.//div[@class="movie-item-info"]/p[@class="name"]/a/text()').extract_first()
actor=site.xpath('.//div[@class="movie-item-info"]/p[@class="star"]/text()').extract_first()
start_time=site.xpath('.//div[@class="movie-item-info"]/p[@class="releasetime"]/text()').extract_first()
item['title']=title
item['actor']=actor
item['start_time']=start_time
print(item)
yield item
items.py文件:
import scrapy
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
actor = scrapy.Field()
start_time = scrapy.Field()
pipelines.py文件:
import pymongo
class MaoyanPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url=crawler.settings.get('MONGO_URL'),
mongo_db=crawler.settings.get('MONGO_DATABASE','items')
)
def open_spider(self,spider):
self.client=pymongo.MongoClient(self.mongo_url)
self.db=self.client[self.mongo_db]
def close_spider(self,spider):
self.client.close()
def process_item(self, item, spider):
collection_name=item.__class__.__name__
print(collection_name)
self.db[collection_name].insert(dict(item))
return item
settings.py文件:
BOT_NAME = 'maoyan'
SPIDER_MODULES = ['maoyan.spiders']
NEWSPIDER_MODULE = 'maoyan.spiders'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
ITEM_PIPELINES = {
'maoyan.pipelines.MaoyanPipeline': 300,
}
MONGO_URI = 'localhost'
MONGO_DATABASE = 'maoyan'
爬取效果:
