TF2.0深度学习实战(五):搭建VGG系列卷积神经网络
写在前面:大家好!我是【AI 菌】,一枚爱弹吉他的程序员。我
热爱AI、热爱分享、热爱开源! 这博客是我对学习的一点总结与记录。如果您也对深度学习、机器视觉、算法、Python、C++感兴趣,可以关注我的动态,我们一起学习,一起进步~
我的博客地址为:【AI 菌】的博客
我的Github项目地址是:【AI 菌】的Github
本教程会持续更新,如果对您有帮助的话,欢迎star收藏~
前言:
本专栏将分享我从零开始搭建神经网络的学习过程,注重理论与实战相结合,力争打造最易上手的小白教程。在这过程中,我将使用谷歌TensorFlow2.0框架逐一复现经典的卷积神经网络:LeNet、AlexNet、VGG系列、GooLeNet、ResNet 系列、DenseNet 系列,以及现在很流行的:RCNN系列、YOLO系列等。
这一次我将复现经典的卷积神经网络VGG系列,首先会对VGG系列卷积神经网络进行简要的解析。然后对自定义数据集进行加载,迭代训练,搭建VGG系列网络,完成图片分类任务。
学习记录:
深度学习环境搭建:Anaconda3+tensorflow2.0+PyCharm
TF2.0深度学习实战(一):分类问题之手写数字识别
TF2.0深度学习实战(二):用compile()和fit()快速搭建MINIST分类器
TF2.0深度学习实战(三):LeNet-5搭建MINIST分类器
TF2.0深度学习实战(四):搭建AlexNet卷积神经网络
TF2.0深度学习实战(六):搭建GoogLeNet卷积神经网络
资源传送门:
论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》
论文翻译:《用于大规模图像识别的深度卷积网络》
VGG实验室官网:http://www.robots.ox.ac.uk/~vgg/research/very_deep/
github项目地址:VGG16、VGG19
一、VGG简介
VGG卷积神经网络出自于《Very Deep Convolutional Networks for Large-Scale Image Recognition》这篇论文,在2014年,由牛津大学VGG实验室的卡伦·西蒙尼安(Karen Simonyan) 和安德鲁·齐瑟曼( Andrew Zisserman)共同发表的。其研究成果在 ILSVRC-2014 挑战赛 ImageNet 分类任务上获得亚军。
VGG卷积神经网络最大的意义在于,将神经网络的层数推向更深,并达到了在当时来说一流的分类和定位效果。我们常说的VGG系列其实包含了:VGG11、VGG13、VGG16、VGG19等一系列的网络模型。其中11、13、16、19表示的是神经网络的层数。可见当时已经将神经网络推向了19层,而在此之前的AlexNet只有8层,LeNet才只有5层。
二、VGG网络结构
谈到CNN(卷积神经网络),卷积层、激活函数、池化层、全连接层、BN层、填充等这些字眼太熟悉了,卷积操作有那几种形式?激活函数该如何选择?池化层有那几种?全连接层的作用是什么?填充有那几种方式?这些都与神经网络的搭建息息相关。
因此,我还是想不厌其烦地向大家推荐一篇博文:千万别点开,不然你会爱上CNN。在这里,有你想要的!
了解完这些基础知识后(大佬忽视~),我们再来看看下面的网络结构:(图片来自论文)

读完了上面的那篇博文,我相信这个图就不难理解了。如果还不懂的话,评论私聊我,发你10G资料补补!哈哈,玩笑是要开的,图还是要分析的:
整个实验分为了6组:A、A-LRN、B、C、D、E。这6组对应着6个单独的卷积神经网络,组成了我们常说的VGG系列。其中,A和A-LRN属于VGG11,B属于VGG13,C和D属于VGG16,E属于VGG19。
- 从整体结构上来看,和LeNet、AlexNet一样,前面采用多个卷积层进行特征提取,后面使用几个全连接层进行分类识别。不同的是,AGG系列网络更深,最浅的也有11层(比如A),最深的到达了19层(比如E)。而网络更深意味着,待优化的参数量就越多。为了避免训练时的参数过多,在设计网络时,采用了更小尺寸的卷积核。从图中我们也可以看到,用的最多的是3 × \times × 3的卷积核,还有少量的1 × \times × 1卷积核。事实证明这个做法是对的,在这之后出现的很多一流的卷积神经网络都是采用的小尺寸的卷子核。
- 输入的是224 × \times × 224 × \times × 3的RGB三通道彩色图片,输出的是1000分类,最后再经过softmax,得到1000分类的概率输出。
- 网络结构中,卷积层和全连接层每一层后都会使用ReLU激活函数。其中,全连接层每层后面还会加入Dropout防止过拟合。
- 虽然有6组实验,但是全连接层都是使用的3层,而且全连接层的节点数和AlexNet一模一样!。是的,就是一模一样!
- A-LRN仅在A的基础上加了一层LRN( Local Response Normalisation),这也是模仿AlexNet ,然而实验证明,LRN在VGG系列里并没有什么卵用,反而增加了内存消耗和计算时间。因此在后面的更深的AGG网络并没有使用LRN。
三、VGG的创新点
- 毫无疑问,最大的创新在于,将网络层数提升到更深的19层。
- 全部采用了3 × \times × 3或者少量1 × \times × 1的卷积核,相对于AlexNet中11 × \times × 11和5 × \times × 5的卷积核,卷积核更小,使得参数量更少,计算代价更低。当然这也是迫不得已的,毕竟层数比AlexNet多了很多,要想控制参数量,卷积核的大小必须减小。而实际上总的参数量还是比AlexNet要多。
- 相比于AlexNet,首个卷积层的卷积核不仅更小,而且采用了更小的步长s=1。原来AlexNet采用的是11 × \times × 11的卷积核,步长s=4。
- 池化层采用了更小的2 × \times × 2的窗口和更小的步长s=2。
最后还想补充的一点是: 使用大的卷积核,不仅会使参数增多,还会使得在卷积计算过程中丢失细节信息。因为卷积核每移动一个步长,都会与上一次的覆盖区域有重合;对于相同的步长,如果卷积核越大的话,重复的区域也就越大;这也就相当于对原始的特征进行了一定的平滑处理。而平滑掉的这些特征,也就是我们常说的局部细节信息。
四、VGG的性能
-
在ImageNet ILSVRC-2014挑战赛中,VGG分别获得了定位和分类任务的冠军和亚军。在比赛结束后,又近一步改进了模型,得出了以下ImageNet数据集分类结果:
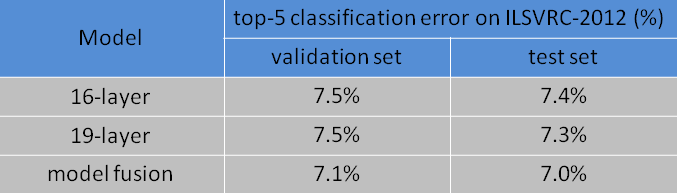
表中,16-layer和19-layer分别代表的是VGG16和VGG19。model fusion是VGG16、VGG19的融合而成的网络。这也是VGG系列测试效果最好的三种模型。
上一篇博文:TF2.0深度学习实战(四):搭建AlexNet卷积神经网络中提到,AnexNet将原来26.2%的Top-5错误率减小到了15.3%,就成了2012年 ILSVRC-2014挑战赛的冠军。然而VGG的横空出世,直接将Top-5错误率降低到了7.0%,使之成为了当时DeepLearning领域最耀眼的明星! -
除了定位和分类精度一流,它的泛化性能也很好。不仅在ImageNet数据集上大放异彩,在其他数据集上也有很好的分类效果!

上图就展示了VGG16、VGG19和他们的融合模式在VOC、Caltech数据集上的测试数据,分类平均精确度均到达了90%左右!可见泛化能力之强。就像我们身边的学神的一样,形成一个学习套路(模型)后,学啥啥都快,学啥啥都好,真正到达了举一反三的效果!
五、TF2.0搭建VGG系列实战
有些话说在前面:
在我写完代码,检查各部分都没问题,一切准备就绪,点击运行,正期待着训练完后,电脑上出现一道完美的精确度数据曲线。然而过了几分钟,居然提示了我一堆英文。凭借着我多年的直觉和刚过六级的蹩脚英语,发现是我电脑运行内存不够!
于是我下意识的翻阅了原论文,看到了下面的表:
![]()
是的,单位是million,百万!也就是说层数最少的VGG11也有1亿3千3百万个待优化参数!
没错,对于这样较深的卷积神经网络,还是建议配置GPU 进行训练,不然就训练将会非常吃力。
可奈何疫情当下,不能回实验室,只能想想其他的办法了。
于是,我改用了VGG系列层数最少的模型VGG11,并且减小了每次喂入神经网络的batch_size,于是一个轻量版的VGG横空出世。通过我的渣渣电脑,经过了几个小时的训练,对自定义数据集迭代了20个epochs,测试精确度到达了97%左右。实验证明,分类效果还不错,测试效果图如下:
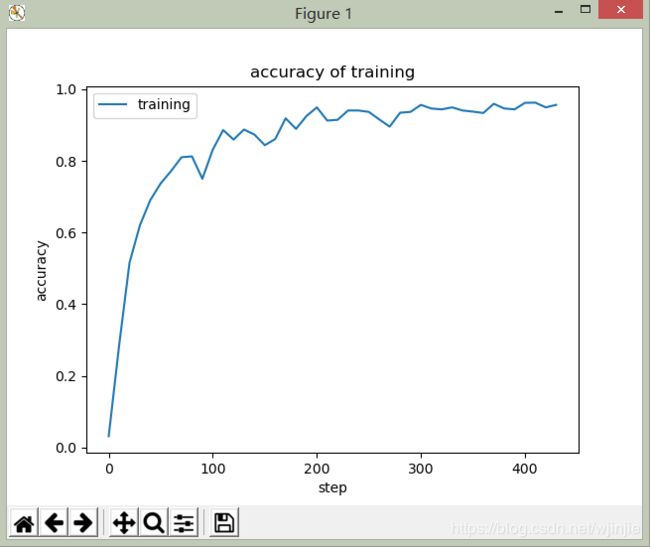
开始实战:
本次实验的自定义数据集加载、训练部分和可视化部分和上篇博文:TF2.0深度学习实战(四):搭建AlexNet卷积神经网络一样,大家可以参见详细代码。唯一不一样的部分是网络的搭建,因此下面我将一一搭建不同层数的VGG卷积神经网络。
为了让大家体验到原汁原味的VGG,下面的代码是按照论文的原本网络结构进行设计的。唯一不同的是将全连接层的节点数4096、4096、1000改为了1024、128、5,为了方便实现对自定义数据集进行五分类。
(1)搭建AGG11 实验A&A-LRN
# 搭建VGG11 实验A
network_VGG11 = Sequential([
# 第一层
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第二层
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第三层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第四层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第五层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第六层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第七层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第八层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Flatten(), # 拉直 7*7*512
# 第九层
layers.Dense(1024, activation='relu'),
layers.Dropout(rate=0.5),
# 第十层
layers.Dense(128, activation='relu'),
layers.Dropout(rate=0.5),
# 第十一层
layers.Dense(5, activation='softmax')
])
network_VGG11.build(input_shape=(None, 224, 224, 3)) # 设置输入格式
network_VGG11.summary() # 打印各层参数表
(2)搭建VGG13 实验B
在VGG11 A 的基础上增加了两层卷积层,卷积核分别为:3 × \times × 3 × \times × 64 、3 × \times × 3 × \times × 128
# 搭建网络
network_VGG13 = Sequential([
# 第一层
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第二层(新增卷积层3*3*64)
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第三层
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第四层(新增卷积层3*3*128)
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第五层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第六层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第七层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第八层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第九层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Flatten(), # 拉直 7*7*512
# 第十一层
layers.Dense(1024, activation='relu'),
layers.Dropout(rate=0.5),
# 第十二层
layers.Dense(128, activation='relu'),
layers.Dropout(rate=0.5),
# 第十三层
layers.Dense(5, activation='softmax')
])
network_VGG13.build(input_shape=(None, 224, 224, 3)) # 设置输入格式
network_VGG13.summary() # 打印各层参数表
(3)搭建VGG16 实验C&D
论文中给出的VGG16有两种结构C和D,两者结构相同。差别仅在于,对于新增的第7,10,13层,C使用是1 × \times × 1的卷积核,D使用的是3 × \times × 3的卷积核。下面以C为例:
network_VGG16 = Sequential([
# 第一层
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第二层
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第三层
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第四层
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第五层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第六层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第七层(新增卷积层1*1*256)
layers.Conv2D(256, kernel_size=1, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第八层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第九层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十层(新增卷积层1*1*512)
layers.Conv2D(512, kernel_size=1, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第十一层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十二层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十三层(新增卷积层1*1*512)
layers.Conv2D(512, kernel_size=1, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Flatten(), # 拉直 7*7*512
# 第十四层
layers.Dense(1024, activation='relu'),
layers.Dropout(rate=0.5),
# 第十五层
layers.Dense(128, activation='relu'),
layers.Dropout(rate=0.5),
# 第十六层
layers.Dense(5, activation='softmax')
])
network_VGG16.build(input_shape=(None, 224, 224, 3)) # 设置输入格式
network_VGG16.summary() # 打印各层参数表
(4)搭建VGG19 实验E
VGG19仅在D的基础上增加了3层卷积层,分别使用了3 × \times × 3 × \times × 256、 3 × \times × 3 × \times × 512、3 × \times × 3 × \times × 512的卷积核。
network_VGG19 = Sequential([
# 第一层
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第二层
layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第三层
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第四层
layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第五层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第六层
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第七层
layers.Conv2D(256, kernel_size=1, strides=1, padding='same', activation='relu'),
# 第八层(新增卷积层3*3*256)
layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第九层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十一层
layers.Conv2D(512, kernel_size=1, strides=1, padding='same', activation='relu'),
# 第十二层(新增卷积层3*3*512)
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第十三层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十四层
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
# 第十五层
layers.Conv2D(512, kernel_size=1, strides=1, padding='same', activation='relu'),
# 第十六层(新增卷积层3*3*512)
layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Flatten(), # 拉直 7*7*512
# 第十七层
layers.Dense(1024, activation='relu'),
layers.Dropout(rate=0.5),
# 第十八层
layers.Dense(128, activation='relu'),
layers.Dropout(rate=0.5),
# 第十九层
layers.Dense(5, activation='softmax')
])
network_VGG19.build(input_shape=(None, 224, 224, 3)) # 设置输入格式
network_VGG19.summary() # 打印各层参数表
写在最后:
由于时间仓促,如果有任何疏漏之处,欢迎大家指正,给出宝贵的意见!
如果您觉得这篇博文对你有所帮助,那就小手一戳,给个关注吧~,您的支持将是我创作最大的动力!