实现一个文字识别(图片转文字)工具
00 前言
最近做ppt,看到有些图片中的文字内容很好,一张一张地码字很累还很费时间。就想着有空做一个文字识别的小工具,方便办公流程。在网上查了一下资料,百度智能云提供了文字识别的接口,可以直接调用,挺方便的。于是就做了一个小工具,和大家分享一下制作过程。
01 准备
01 -1 虚拟环境
本文所用版本是python3.8.2,新版的python都自带一个创建虚拟环境模块。新建一个工作目录名叫Image2Text。
mkdir Image2Text //也可以直接用鼠标右键创建文件夹
cd Image2Text //进入项目文件夹
python -m venv venv //创建虚拟环境,第一个venv是包名,第二个是创建虚环境名字(可以用项目名)然后在venv文件夹下我们看到如下的目录,虚拟环境激活后才能使用,激活的脚本在Scripts里面。

于是,我们进到Scripts文件夹里面,执行激活脚本。使用activate激活(使用deactivate.bat 退出)。
01 -2 安装依赖
其中PySide2是做界面的。baidu-aip 是调用的百度的文字识别接口,是主要功能。
pip3 install PySide2
pip install baidu-aip
注:之前使用pyQt5出现了qt.qpa.plugin: Could not find the Qt platform plugin "windows"这个问题,然后用pip3 install PySide2下载PySide2,并修改了路径。
01 -3 图片识别SDK
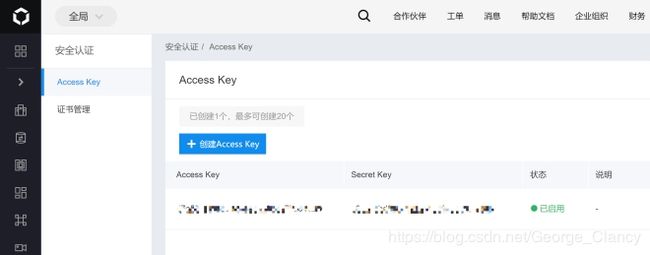
根据百度的文本识别SDK介绍(https://ai.baidu.com/ai-doc/OCR/Dk3h7yf8m),我们需要注册百度智能云的账户,并在安全中心获取API_KEY(对应百度智能云的“Access Key ID”)和SECRET_KEY(对应百度智能云的“Access Key Secret”)。
02 开始
02-1 调用接口测试
百度文本识别的接口很丰富,有通用文本识别、包含位置信息的文本识别、驾照识别等等。我这里面用的是通用的文本识别,首先,新建一个orc_util.py文件引用接口并说明认证信息。
from aip import AipOcr
# 添加认证信息,这里面的api密钥和secret密钥可以去百度智能云免费申请
APP_ID = ''
API_KEY = 'd7a50f1938xxxxxxxxxx5277a51e23'
SECRET_KEY = 'e6ca46bdxxxxxxxxxxxx053cf288b'然后,我们定义一个获取图片的方法。
def get_ocr_str(file_path, origin_format=True):
"""
获取图片比特流
:param file_path: 图片路径
:return: 函数get_ocr_str_from_bytes()的结果
"""
with open(file_path, 'rb') as fp:
file_bytes = fp.read()
return get_ocr_str_from_bytes(file_bytes, origin_format)然后定义一个转换方法,设置options参数(不检测文本方向,语言模式为中英文),实例化一个AipOcr类,调用basicGeneral()接口。通用文字识别的请求参数见表1,通用文字识别的返回参数见表2。
def get_ocr_str_from_bytes(file_bytes, origin_format=True):
"""
图片转文字
:param file_bytes: 图片的字节
:return: result_str
"""
options = {
'detect_direction': 'false',
'language_type': 'CHN_ENG',
}
ocr = AipOcr(APP_ID, API_KEY, SECRET_KEY)
result_dict = ocr.basicGeneral(file_bytes, options)
if origin_format:
result_str = '\n'.join([entity['words'] for entity in result_dict['words_result']])
else:
result_str = ''.join([entity['words'] for entity in result_dict['words_result']])
return result_str| 参数名称 | 是否必选 | 类型 | 可选值范围 | 默认值 | 说明 |
|---|---|---|---|---|---|
| image | 是 | string | 图像数据,base64编码,要求base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式 | ||
| url | 是 | string | 图片完整URL,URL长度不超过1024字节,URL对应的图片base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式,当image字段存在时url字段失效 | ||
| language_type | 否 | string | CHN_ENG ENG POR FRE GER ITA SPA RUS JAP KOR |
CHN_ENG | 识别语言类型,默认为CHN_ENG。可选值包括: - CHN_ENG:中英文混合; - ENG:英文; - POR:葡萄牙语; - FRE:法语; - GER:德语; - ITA:意大利语; - SPA:西班牙语; - RUS:俄语; - JAP:日语; - KOR:韩语; |
| detect_direction | 否 | string | true false |
false | 是否检测图像朝向,默认不检测,即:false。朝向是指输入图像是正常方向、逆时针旋转90/180/270度。可选值包括: - true:检测朝向; - false:不检测朝向。 |
| detect_language | 否 | string | true false |
false | 是否检测语言,默认不检测。当前支持(中文、英语、日语、韩语) |
| probability | 否 | string | true false |
是否返回识别结果中每一行的置信度 |
| 字段 | 必选 | 类型 | 说明 |
|---|---|---|---|
| direction | 否 | number | 图像方向,当detect_direction=true时存在。 - -1:未定义, - 0:正向, - 1: 逆时针90度, - 2:逆时针180度, - 3:逆时针270度 |
| log_id | 是 | number | 唯一的log id,用于问题定位 |
| words_result_num | 是 | number | 识别结果数,表示words_result的元素个数 |
| words_result | 是 | array | 定位和识别结果数组 |
| +words | 否 | string | 识别结果字符串 |
| probability | 否 | object | 行置信度信息;如果输入参数 probability = true 则输出 |
| +average | 否 | number | 行置信度平均值 |
| +variance | 否 | number | 行置信度方差 |
| +min | 否 | number | 行置信度最小值 |
然后,定义主函数开始测试吧。
if __name__ == '__main__':
IMAGE_PATH = "test.jpg"
print(get_ocr_str(IMAGE_PATH))我们的测试图是这样的,测试的时候直接截的cmd命令行的报错信息,命名为test然后保存在当前的目录下。
cmd命令行运行结果如下 ,我们可以看到识别结果还是不错的,并且还保留了原格式。emm, 那么开始做界面吧。
02-2 界面编写
ok,我们要开始编写界面了, 我这边使用的是PySide2,打算后期再美化一下。也可以使用python自带的tkinter。好了,我们新建一个MainUi.py文件。同样,引入需要的包,设置一个全局的资源变量(等待转换时的图标)。
中间遇到过一个问题,最开始运行MainUi.py文件的时候,提示找不到Qt插件,也就是qt.qpa.plugin: Could not find the Qt platform plugin "windows"这个问题,然后找到了如下的解决方式。
import sys
import PySide2
import os
'''
#添加PySide2路径,为了解决qt.qpa.plugin: Could not find the Qt platform plugin "windows"这个问题;
#也可以修改文件"C:\Applications\WinPython-64bit-3.6.3.0Qt5\python-3.6.3.amd64\Lib\site-packages\PySide2_init_.py" ,作者用的是WinPython ,
dirname = os.path.dirname(__file__)
plugin_path = os.path.join(dirname, 'plugins', 'platforms')
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = plugin_path
'''
dirname = os.path.dirname(PySide2.__file__)
plugin_path = os.path.join(dirname, 'plugins', 'platforms')
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = plugin_path
import ocr_util
import threading
from PySide2 import QtWidgets
from PySide2.QtCore import Signal,Slot
from PySide2.QtGui import QMovie,QPixmap,QIcon
#设置资源变量
LOADING_GIF_URL = './asset/file.png'
然后定义一个类,设置一个信号量,用于连接返回的识别结果,并显示到文本框中。
class MainUi(QtWidgets.QMainWindow):
signal_response = Signal(str)
def __init__(self):
super().__init__()
self.init_ui()定义一个初始化方法,添加两个布局,一个用来放文本框,一个用来放按钮,截取图片功能没有实现哦,打算后面做的。
def init_ui(self):
#初始化一个窗口,主界面采用固定大小,网格布局
self.setMinimumSize(800,500)
self.main_widget = QtWidgets.QWidget() # 创建窗口主部件
self.main_layout = QtWidgets.QGridLayout() # 创建主部件的网格布局
self.main_widget.setLayout(self.main_layout) # 设置窗口主部件布局为网格布局
#添加上下两个widget,布局用
self.up_widget = QtWidgets.QWidget() # 创建部件
self.up_widget.setObjectName('up_widget')
self.up_layout = QtWidgets.QGridLayout() # 创建部件的网格布局层
self.up_widget.setLayout(self.up_layout) # 设置部件布局为网格
self.down_widget = QtWidgets.QWidget()
self.down_widget.setObjectName('down_widget')
self.down_layout = QtWidgets.QGridLayout()
self.down_widget.setLayout(self.down_layout)
#添加上下两个widget到主部件中
self.main_layout.addWidget(self.up_widget,0,0,6,8) # 上侧部件在第0行第0列,占4行8列
self.main_layout.addWidget(self.down_widget,6,0,2,8) # 下侧部件在第6行第0列,占2行8列
self.setCentralWidget(self.main_widget) # 设置窗口主部件
#添加图片按钮和截取图片按钮
self.add_pic = QtWidgets.QPushButton("添加图片")
self.add_pic.setObjectName('add_pic')
self.add_pic.clicked.connect(self.on_add_pic_clicked)#连接点击事件
self.cap_pic = QtWidgets.QPushButton("截取图片")
self.cap_pic.setObjectName('cap_pic')
#添加按钮到下widget中
self.down_layout.addWidget(self.add_pic,6,1,1,1)
self.down_layout.addWidget(self.cap_pic,6,5,1,1)
#添加文本框用来显示识别的文字
self.textEdit = QtWidgets.QTextEdit('说明:图片格式要求不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式')
self.textEdit.setReadOnly(True)#文本框设为不可编辑
self.up_layout.addWidget(self.textEdit,0,0,6,8)
self.init_loading_gif()
self.signal_response.connect(self.__slot_http_response)#连接信号和槽函数,将结果显示在文本框中
由于文字识别的时候还是有2秒左右的检测时间的,所以添加了一个等待的图片,发现用.png格式的图片就可以显示,用.gif格式的文件就不能显示,很奇怪。
def init_loading_gif(self):
"""
初始化loading动画
:return:
"""
gif = QMovie(LOADING_GIF_URL)
gif.start()
x, y = 275, 110
self.loadingLabel = QtWidgets.QLabel(self)
self.loadingLabel.setMovie(gif)
self.loadingLabel.adjustSize()
self.loadingLabel.setGeometry(x, y, self.loadingLabel.width(), self.loadingLabel.height())
self.loadingLabel.setVisible(False)点击按钮事件,打开文件对话框,获取文件路径,然后清空文本框内容,准备显示识别结果,并调用run_ocr_async()方法。
@Slot()
def on_add_pic_clicked(self):#点击添加图片
dialog = QtWidgets.QFileDialog()#生成文件对话框对象
dialog.setFileMode(QtWidgets.QFileDialog.AnyFile)#设置文件过滤器,这里是任意文件,设置参考https://www.jianshu.com/p/4b297a825a04
file_urls = dialog.getOpenFileNames()[0]#获取文件名称
if len(file_urls) > 0:
self.textEdit.clear()
for img_full_path in file_urls:
if img_full_path is None or img_full_path == '':
continue
with open(img_full_path, 'rb') as fp:
file_bytes = fp.read()
self.run_ocr_async(file_bytes)等待的时候让等待的图片显示出来,然后调用我们之前编写的图片识别函数返回信号量,并将信号量传递给槽函数,显示在文本框中。
def run_ocr_async(self, image_bytes):
self.loadingLabel.setVisible(True)
threading.Thread(target=self.job_ocr, args=(image_bytes,)).start()
def job_ocr(self, image_bytes):
result = ''
try:
result = ocr_util.get_ocr_str_from_bytes(image_bytes)
finally:
self.signal_response.emit(result)
@Slot(str)
def __slot_http_response(self, result):
self.textEdit.append(result)
self.textEdit.setReadOnly(False)#文本框设为可编辑
self.loadingLabel.setVisible(False)MainUi类定义好了,开始编写main函数,并使用。
def main():
app = QtWidgets.QApplication(sys.argv)
gui = MainUi()
gui.show()
sys.exit(app.exec_())
if __name__ == '__main__':
main()02-3 完成
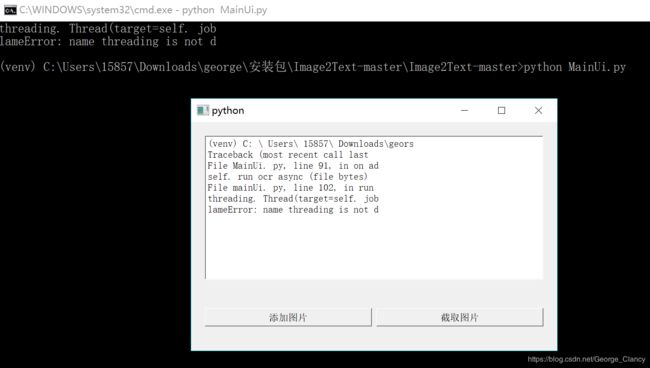
运行一下,看看成果吧。

打开文件。

ok,识别文字显示的也不错。后期界面功能再完善一下就好了。
03 未解决的问题
添加等待动画的时候,发现用.png格式的图片就可以显示,用.gif格式的文件就不能显示,很奇怪。有了解的兄弟还望赐教。