嵌入式Linux——DMA:在内核中简单使用DMA实现内存中数据传递
简介:
本文主要介绍在内核中简单使用DMA实现内存数据传递。由于本篇文章中没有介绍与框架相关的程序,只是使用字符设备来操作DMA,同时也没有抽象的层次,因此本文中代码分析部分就相对简单。但我还是会将文章分为两部分,第一部分我将介绍与DMA相关的知识。而第二部分讲解在内核中如何通过代码实现DMA的数据传递。
Linux内核:linux-2.6.22.6
所用开发板:JZ2440 V3(S3C2440A)
声明:
本文是看完韦东山老师关于DMA的视频后,所写的学习总结。所以文章中可能会用到老师在课上所讲解的内容。不过我也在文章中加了一些我自己的东西。所以如果你觉得我的文章对你有帮助那是我的荣幸。同时我将S3C2440A中DMA这一章节翻译为中文并放在我的文章:S3C2440A 第八章:DMA 中,如果你想了解可以看看这篇翻译。而我会在下面介绍DMA中一些重要的知识点。
第一部分:DMA相关知识
在介绍DMA之前我想问大家:我们为什么要引入DMA,DMA对我们有什么好处那?
答:计算机系统中各种常用的数据输入/输出方法有查询方式(包括无条件及条件传送方式)和中断方式,这些方式适用于CPU与慢速及中速外设之间的数据交换。但当高速外设要与系统内存或者要在系统内存的不同区域之间进行大量数据的快速传送时,就在一定程度上限制了数据传送的速率。直接存储器存取(DMA)就是为解决这个问题提出的,采用DMA方式,在一定时间段内,由DMA控制器取代CPU,获得总线控制权,来实现内存与外设或者内存的不同区域之间大量数据的快速传送。同时很重要的一点是当DMA传输数据时,并不占用CPU资源,在这个时候CPU可以空出手来做其他的事情。这样我们既可以做大量数据的高速传输又可以让CPU有时间和资源去做其他的事情。
上面介绍了什么是DMA,也介绍了DMA的重要性。那么我们就要看看我们芯片中的DMA了。在S3C2440A中,我们集成了DMA模块,可以用来传递高速传输数据。既然是数据传输那么我又要问了,我们知道数据传输三要素:源,目的,长度。这是我们数据传输时要知道的。那么在S3C2440A中,源,目的,长度是怎么表示的那?
在2440中我们的源与目的的选择有四种情况
1. 源和目的都在系统总线
2. 源在系统总线,而目的在外部总线
3. 源在外部总线,而目的在系统总线
4. 源和目的都在外部总线
2440中源与目的就是通信的双方,而这双方是通过请求DMA传递信息的,所以我们将上面这些向DMA发送请求的(不管是源还是目的)称为请求源。他们请求DMA来传输数据。而在2440中有四条通道来设置不同的请求源,他们为:

介绍完源与目的,我们本来是要介绍数据传输长度的。但是我想还是先介绍数据传输方式比较好。介绍完数据传输方式我们了解了数据是以什么样的方式传输的。这样我们自然就知道要传输的数据长度了。
DMA模式介绍:
DMA service mode:single service&Whole service。前一模式下,一次DMA请求完成一项原子操作,并且transfer count的值减1。后一模式下,一次DMA请求完成一批原子操作,直到transfer count等于0表示完成一次整体服务。具体对应DCON[27]。
DMA DREQ/DACK PROTOCOL:DMA请求和应答的协议有两种,Demond mode 和 Handshake mode。两者对Request和Ack的时序定义有所不同:
在Demond模式下,如果DMA完成一次请求后如果Request仍然有效,那么DMA就认为这是下一次DMA请求,并立即开始下一次的传输;
在Handshake模式下,DMA完成一次请求后等待Request信号无效,如果Request无效,DMA会无效ACK两个时钟周期,再等待下一次Request。
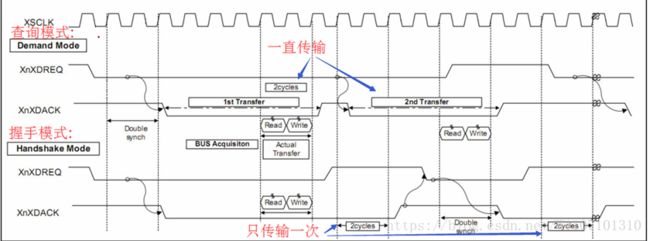
下面我们来介绍DMA中数据传输的格式,注意,这里说的是传输格式,而不是传输的大小。在DMA中有两种传输格式,单元传输和burst4传输,相对于单元传输的每次读写一个单元,burst4 可以一次完成四个单元的读写。而这里的单元就是我们说的数据的大小有:字节,半字,字。

有了上面的知识我们就可以介绍总的数据的传输大小了:DSZ x TSZ x TC,其中DSZ就是上面说的数据的大小,TSZ是传输的格式,而TC是传输的次数。他们的乘积就是整个数据的大小了。
介绍了数据传输的三要素,我想大家又要问了:既然有了数据传输的三要素,那么我们的数据是如何传输的?
在我们的S3C2440中他是使用三态的有限状态机(FSM)来实现数据的传输的。虽然是使用的有限状态机,但2440 中还是有两种传输模式:单服务模式和全服务模式。我下面用一幅图来展示三态的有限状态机:

在状态1时,DMA等待DMA请求,此时DMA ACK 和INT REQ 为 0 。当DMA收到DMA请求时,他跳转到状态2 。
在状态2时,DMA ACK为1,INT REQ还为0,此时CURR_TC从DCON[19:0]从加载计数值。在他们完成后他跳到状态3 。
在状态3时,引入子状态机用来处理一次原子操作,即完成一次数据从源读出然后写到目的中。而在这是我们就要分单服务模式和全服务模式来讨论了。在单服务模式中,子有限状态机完成一次原子操作后CURR_TC-1,主有限状态机将DMA ACK设为0,然后调回到状态1,然后等待下一次的DMA请求。而在全服务模式时,子有限状态机将一直运行直到CURR_TC为0,然后他再将INT REQ设为1而将DMA ACK设为0,然后调回到状态1,然后等待下一次的DMA请求。
上面我们介绍了DMA是如何传输数据的,同时也讲了数据传输的三要素。那么我们下面就要讲一下在2440中DMA的配置步骤和要点了(主要针对寄存器):
1.数据从哪里来,到哪里去?
使用DMA首先我们要知道数据的流向,DISRCx寄存器是DMA初始源寄存器,存放了数据的源地址。DIDSTx是DMA的初始目的寄存器,存放数据的目的地址。
2.数据走的什么总线?地址是否是固定的?
我们还要知道源与目的数据存储设备在什么总线上(AHB系统总线,一般是高速的比如内存,APB外围总线,低速的比如SD,UART;具体走什么总线可以在datasheet上查到);以及数据传输结束以后起始地址还原到发送前的起始地址呢,还是在现在的末尾+1做为新的起始地址。这些设置在DISRCCx与DIDSTCx两个寄存器里面配置。
3.数据以什么方式传输?源与目的是什么设备?要不要自动重载?
需要确定数据的传输方式有请求还是握手,根据上面的总线确定与什么时钟同步(HCLK,PCLK),是单元传输还是突发传输,是以字节传输还是字传输,是否重载。是单服务(只发送一次)还是多服务(不停循环发送),以及数据的传送大小。选择源与目的设备。最后还要确定中断是不是传输结束发生(CURR_TC记数是不是0)。这些都在DCONx中设置。
4.怎么开始传输DMA和停止DMA,这些在DMASKTRIG中设置。
第二部分:在内核中如何通过代码实现DMA数据传递。
通过上面对DMA的介绍,我对DMA有了一定的认识。那么我将在这一部分用代码实现对DMA的简单控制。现在我写一下我在代码中要实现的功能:对比于使用和不使用DMA来传递内存中的数据,来确定DMA对于解放CPU的重要性。
我们将借助于字符设备驱动在他的操作函数中实现对DMA的控制。所以我们可以大体总结出这个程序的写作步骤:
1. 确定主设备号
2. 写file_operations结构体,并在其操作函数中写出对DMA的控制
3. 在入口/出口函数中注册/注销这个字符驱动
4. 使用;udev机制在内核中创建字符设备
而此处需要特别说明的一点是,在使用DMA时我们要求DMA操作的数据的物理地址和虚拟地址都是要连续的。因此我们使用dma_alloc_writecombine函数来为DMA分配内存缓冲区。而不用我们常使用的kmalloc来申请空间。而我在下图中做了这两个函数的对比:

从上图可以看出kmalloc和dma_alloc_writecombine这两个函数申请的虚拟地址都是连续的,但是他们的物理地址却不相同,kmalloc的物理地址是离散的,而dma_alloc_writecombine的物理地址是连续的。
下面是dma_alloc_writecombine函数的介绍
/*该函数只禁止cache缓冲,保持写缓冲区,也就是对注册的物理区写入数据,也会更新到对应的虚拟缓存区上*/
void *dma_alloc_writecombine(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
//分配DMA缓存区
//返回值为:申请到的DMA缓冲区的虚拟地址,若为NULL,表示分配失败,需要释放,避免内存泄漏
//参数如下:
//*dev:指针,这里填0,表示这个申请的缓冲区里没有内容
//size:分配的地址大小(字节单位)
//*handle:申请到的物理起始地址
//gfp:分配出来的内存参数,标志定义在,常用标志如下:
//GFP_ATOMIC 用来从中断处理和进程上下文之外的其他代码中分配内存. 从不睡眠.
//GFP_KERNEL 内核内存的正常分配. 可能睡眠.
//GFP_USER 用来为用户空间页来分配内存; 它可能睡眠. 而与dma_alloc_writecombine函数对应的就是他们的空间释放函数了:dma_free_writecombine
dma_free_writecombine(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle); //释放DMA缓存,与dma_alloc_writecombine()对应
//size:释放长度
//cpu_addr:虚拟地址,
//handle:物理地址好了,有了上面的知识我们就可以上代码了。我们还是按着老师的步骤来讲,我们先看入口函数中做了什么:
static int s3c_dma_init(void)
{
/* 申请DMA内存 */
if(request_irq(IRQ_DMA3,s3c_dma_irq,0,"s3c_dma",1)){
free_irq(IRQ_DMA3,1);
printk("can't request_irq for DMA \n");
return -ENOMEM;
}
/* 为源分配内存对应的缓存区 */
src = dma_alloc_writecombine(NULL,BUF_SIZE,&src_phys,GFP_KERNEL);
if(NULL == src){
printk("can't alloc buffer for src \n");
return -ENOMEM;
}
/* 为目的分配内存对应的缓存区 */
dst = dma_alloc_writecombine(NULL,BUF_SIZE,&dst_phys,GFP_KERNEL);
if(NULL == dst){
printk("can't alloc buffer for dst \n");
dma_free_writecombine(NULL,BUF_SIZE, src, src_phys);
return -ENOMEM;
}
/* 对DMA寄存器做重映射 */
dma_regs = ioremap(DMA3_BASE_ADDR, sizeof(struct s3c_dma_regs));
/* 注册字符设备 */
auto_major = register_chrdev(auto_major,"s3c_dma",&dma_fops);
/* 创建设备节点 */
cls = class_create(THIS_MODULE,"s3c_dma");
class_device_create(cls,NULL,MKDEV(auto_major,0),NULL,"s3c_dma");
return 0;
}从上面看我们做了:
1. 申请DMA内存
2. 为源分配内存对应的缓存区
3. 为目的分配内存对应的缓存区
4. 对DMA寄存器做重映射
5. 注册字符设备
6. 创建设备节点
在上面我们分配为源和目的分配内存对应的缓冲区,并对2440 中DMA相关的寄存器做了重映射,这是为下面对DMA的操作做准备,而与DMA相关的寄存器我们将他们放到了一个结构体中,这样方便我们的调用:
#define DMA0_BASE_ADDR 0x4b000000 /* DMA0 寄存器的基地址 */
#define DMA1_BASE_ADDR 0x4b000040 /* DMA1 寄存器的基地址 */
#define DMA2_BASE_ADDR 0x4b000080 /* DMA2 寄存器的基地址 */
#define DMA3_BASE_ADDR 0x4b0000c0 /* DMA3 寄存器的基地址 */
struct s3c_dma_regs{
unsigned long disrc;
unsigned long disrcc;
unsigned long didst;
unsigned long didstc;
unsigned long dcon;
unsigned long dstat;
unsigned long dcsrc;
unsigned long dcdst;
unsigned long dmasktrig;
};
static volatile struct s3c_dma_regs *dma_regs;上面就是我们定义的DMA寄存器的基地址和寄存器结构体。我们会根据DMA请求源的不同而调用不同的DMA基地址。从而操作不同DMA的寄存器,在本实例中我们使用DMA3 。
下面我们看file_operations:
static struct file_operations dma_fops = {
.owner = THIS_MODULE,
.ioctl = s3c_dma_ioctl,
};因为我们这个只是一个简单的例子,所以我们并没有做太多的操作函数,而只是使用ioctl这个函数来实现我们上面说的:对比使用和不使用DMA来实现内存数据的拷贝。下面我们进ioctl中看看他是怎么实现的:
int s3c_dma_ioctl(struct inode *inode, struct file *file, unsigned int cmd, unsigned long arg)
{
int i;
static int cnt;
memset(src,0xaa,BUF_SIZE);
memset(dst,0x55,BUF_SIZE);
switch(cmd){
case MEM_CPY_NO_DMA :
{
for(i=0;i= 30){
cnt = 0;
if(memcmp(src,dst,BUF_SIZE)==0){
printk("MEM_CPY_NO_DMA ok \n");
}else{
printk("MEM_CPY_NO_DMA file \n");
}
}
break;
}
case MEM_CPY_DMA :
{
/* 把源,目的,长度告诉DMA */
/* 源的物理地址 */
dma_regs->disrc = src_phys;
/* 源位于AHB总线,原地址递增 */
dma_regs->disrcc = (0<<1) | (0<<0);
/* 目的的物理地址 */
dma_regs->didst = dst_phys;
/* 目的位于AHB总线,目的地址递增 */
dma_regs->didstc = (0<<2) | (0<<1) | (0<<0);
/* 使能中断,单个传输,软件触发,读写单位为byte */
dma_regs->dcon = (1<<30) | (1<<29) | (0<<28) | (1<<27) | (0<<23) | (0<<20) | (BUF_SIZE << 0);
/* 启动DMA */
dma_regs->dmasktrig = (1<<1) | (1<<0);
/* 如何知道DMA什么时候完成,用中断函数通知 */
/* 休眠 */
ev_dma = 0;
wait_event_interruptible(dma_waitq,ev_dma);
if(++cnt >= 30){
cnt = 0;
if(memcmp(src,dst,BUF_SIZE)==0){
printk("MEM_CPY_DMA ok \n");
}else{
printk("MEM_CPY_DMA file \n");
}
}
break;
}
}
return 0;
} 通过switch语句判断,当我们从应用程序的ioctl中接收到cmd并将其传输到我们驱动中的ioctl中,从而判断是MEM_CPY_NO_DMA还是MEM_CPY_DMA。当cmd为MEM_CPY_NO_DMA时,我们不使用DMA而是用CPU来将数据从源拷贝到目的,而当cmd为MEM_CPY_DMA时,我们使用DMA将源中的数据拷贝到目的。
讲解到这里,我想很多人要问了,我们既然写了ioctl,那么我们去哪里使用这个ioctl函数那?
所以我们还要写一个测试程序在应用层测试这个驱动程序。而具体的测试程序为:
/*
* 用法:
* ./s3c_dma_test
*/
#include
#include
#include
#include
#include
#define MEM_CPY_NO_DMA 0
#define MEM_CPY_DMA 1
void print_usage(char *data)
{
printf("usage: \n");
printf("%s \n",data);
}
int main(int argc,char **argv)
{
int fd;
/* 判断输入的参数是不是两个 */
if(2 != argc){
print_usage(argv[0]);
return -1;
}
/* 打开DMA设备 */
fd = open("/dev/s3c_dma",O_RDWR);
if(fd<0){
printf("can't open /dev/s3c_dma . \n");
}
/* 判断参数并调用ioctl函数 */
if(strcmp(argv[1], "nodma") == 0){
while(1){
ioctl(fd,MEM_CPY_NO_DMA);
}
}else if(strcmp(argv[1], "dma") == 0){
while(1){
ioctl(fd,MEM_CPY_DMA);
}
}else{
print_usage(argv[0]);
}
return 0;
} 从上面看他做的是:
1. 判断输入的参数是不是两个
2. 打开DMA设备
3. 判断参数并调用ioctl函数
测试:
下面我介绍怎么通过这个测试程序测试DMA驱动。
1. 装载驱动模块:insmod s3c_dma.ko
2. 在后台运行不使用DMA的驱动,即测试ioctl中的cmd为MEM_CPY_NO_DMA: ./dma_test nodma &
3. 当程序在后台运行后,我们使用ls命令,看开发板上的反应时间。
4. 在后台运行使用DMA的驱动,即测试ioctl中的cmd为MEM_CPY_DMA: ./dma_test dma &
5. 当程序在后台运行后,我们使用ls命令,看开发板上的反应时间。
然后比较两次的反应时间就可以看出使用DMA的优越性了。
参考文章:
S3C2440 Mini 2440 DMA方式实现Uart串口通信
mini2440裸机试炼之——DMA直接存取 实现Uart(串口)通信
32.Linux-2440下的DMA驱动(详解)
基于mini2440开发板学习DMA
DMA原理和实验