作业调度中间件 Elastic-Job-Cloud 源码分析 —— 高可用
点击上方“芋道源码”,选择“设为星标”
做积极的人,而不是积极废人!
源码精品专栏
中文详细注释的开源项目
消息中间件 RocketMQ 源码解析
数据库中间件 Sharding-JDBC 和 MyCAT 源码解析
作业调度中间件 Elastic-Job 源码解析
分布式事务中间件 TCC-Transaction 源码解析
Eureka 和 Hystrix 源码解析
Java 并发源码
摘要: 原创出处 http://www.iocoder.cn/Elastic-Job/cloud-high-availability/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文基于 Elastic-Job V2.1.5 版本分享
1. 概述
2. Scheduler 集群
3. Scheduler 部署
4. Scheduler 故障转移
5. Scheduler 数据存储
5.1 RunningService
5.2 ProducerManager
5.3 TaskScheduler
6. Mesos Master 崩溃
7. Mesos Slave 崩溃
8. Scheduler 核对
666. 彩蛋
1. 概述
本文主要分享 Elastic-Job-Cloud 高可用。
一个高可用的 Elastic-Job-Cloud 组成如下图:
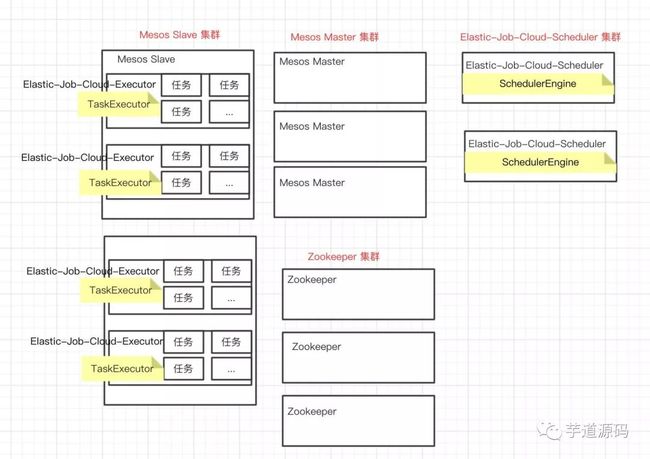
Mesos Master 集群
Mesos Slave 集群
Zookeeper 集群
Elastic-Job-Cloud-Scheduler 集群
Elastic-Job-Cloud-Executor 集群
本文重点分享 Elastic-Job-Cloud-Scheduler 如何实现高可用。
Mesos Master / Mesos Slave / Zookeeper 高可用,同学们可以自行 Google 解决。Elastic-Job-Cloud-Executor 运行在 Mesos Slave 上,通过 Mesos Slave 集群多节点实现高可用。
你行好事会因为得到赞赏而愉悦
同理,开源项目贡献者会因为 Star 而更加有动力
为 Elastic-Job 点赞!传送门
2. Scheduler 集群
Elastic-Job-Cloud-Scheduler 通过至少两个节点实现集群。集群中通过主节点选举一个主节点,只有主节点提供服务,从实例处于"待命"状态。当主节点故障时,从节点会选举出新的主节点继续提供服务。实现代码如下:
public final class Bootstrap {
public static void main(final String[] args) throws InterruptedException {
// 初始化 注册中心
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(BootstrapEnvironment.getInstance().getZookeeperConfiguration());
regCenter.init();
// 初始化 Zookeeper 选举服务
final ZookeeperElectionService electionService = new ZookeeperElectionService(
BootstrapEnvironment.getInstance().getFrameworkHostPort(), (CuratorFramework) regCenter.getRawClient(), HANode.ELECTION_NODE, new SchedulerElectionCandidate(regCenter));
electionService.start();
// 挂起 主进程
final CountDownLatch latch = new CountDownLatch(1);
latch.await();
// Hook 貌似位置不对?
Runtime.getRuntime().addShutdownHook(new Thread("shutdown-hook") {
@Override
public void run() {
electionService.stop();
latch.countDown();
}
});
}
}
Bootstrap,Elastic-Job-Cloud-Scheduler 启动器(仿佛在说废话)。
CoordinatorRegistryCenter,用于协调分布式服务的注册中心,在《Elastic-Job-Lite 源码分析 —— 注册中心》有详细解析。
ZookeeperElectionService,Zookeeper 选举服务,本小节的主角。
ShutdownHook 关闭进程钩子,代码放置的位置不对,需要放在
CountDownLatch#await()方法上面。目前实际不影响使用。
调用 ZookeeperElectionService#start() 方法,初始化 Zookeeper 选举服务以实现 Elastic-Job-Cloud-Scheduler 主节点选举。
private final CountDownLatch leaderLatch = new CountDownLatch(1);
private final LeaderSelector leaderSelector;
public ZookeeperElectionService(final String identity, final CuratorFramework client, final String electionPath, final ElectionCandidate electionCandidate) {
// 创建 LeaderSelector
leaderSelector = new LeaderSelector(client, electionPath, new LeaderSelectorListenerAdapter() {
@Override
public void takeLeadership(final CuratorFramework client) throws Exception {
// ... 省略【暂时】无关代码
}
});
// 设置重复参与选举主节点
leaderSelector.autoRequeue();
// 设置参与节点的编号
leaderSelector.setId(identity);
}
/**
* 开始选举.
*/
public void start() {
log.debug("Elastic job: {} start to elect leadership", leaderSelector.getId());
leaderSelector.start();
}
通过 Apache Curator LeaderSelector 实现分布式多节点选举。
FROM https://curator.apache.org/apidocs/org/apache/curator/framework/recipes/leader/LeaderSelector.html
Abstraction to select a "leader" amongst multiple contenders in a group of JMVs connected to a Zookeeper cluster. If a group of N thread/processes contends for leadership, one will be assigned leader until it releases leadership at which time another one from the group will be chosen.
Note that this class uses an underlying InterProcessMutex and as a result leader election is "fair" - each user will become leader in the order originally requested (from ZK's point of view).调用
LeaderSelector#autoRequeue()方法,设置重复参与选举主节点。默认情况下,自己选举成为主节点后,不再参与下次选举。设置重复参与选举主节点后,每次选举都会参与。在 Elastic-Job-Cloud-Scheduler 里,我们显然要重复参与选举。调用
LeaderSelector#setId()方法,设置参与节点的编号。在 Elastic-Job-Cloud-Scheduler 里暂时没有实际用途。编号算法为BootstrapEnvironment.getInstance().getFrameworkHostPort(),即:HOST:PORT。调用
#start()方法,开始选举。当自己选举主节点成功,回调LeaderSelector#takeLeadership()方法。
回调 LeaderSelector#takeLeadership() 方法,Elastic-Job-Cloud-Scheduler 主节点开始领导状态。实现代码如下:
// ZookeeperElectionService.LeaderSelector 内部实现类
@Override
public void takeLeadership(final CuratorFramework client) throws Exception {
log.info("Elastic job: {} has leadership", identity);
try {
// 开始领导状态
electionCandidate.startLeadership();
// 挂起 进程
leaderLatch.await();
log.warn("Elastic job: {} lost leadership.", identity);
// 终止领导状态
electionCandidate.stopLeadership();
} catch (final JobSystemException exception) {
// 异常退出
log.error("Elastic job: Starting error", exception);
System.exit(1);
}
}
调用
SchedulerElectionCandidate#startLeadership()方法,开始领导状态。实现代码如下:// SchedulerElectionCandidate.java
public final class SchedulerElectionCandidate implements ElectionCandidate {private final CoordinatorRegistryCenter regCenter;
private SchedulerService schedulerService;
public SchedulerElectionCandidate(final CoordinatorRegistryCenter regCenter) {
this.regCenter = regCenter;
}
@Override
public void startLeadership() throws Exception {
try {
schedulerService = new SchedulerService(regCenter);
schedulerService.start();
} catch (final Throwable throwable) {
throw new JobSystemException(throwable);
}
}}
// SchedulerService.java
/**
* 以守护进程方式启动.
*/
public void start() {
facadeService.start();
producerManager.startup();
statisticManager.startup();
cloudJobConfigurationListener.start();
taskLaunchScheduledService.startAsync();
restfulService.start();
schedulerDriver.start();
if (env.getFrameworkConfiguration().isEnabledReconcile()) {
reconcileService.startAsync();
}
}当 Elastic-Job-Cloud-Scheduler 主节点调用
SchedulerService#start()方法后,各种服务初始化完成,特别是和 Mesos Master 的连接,可以愉快的进行作业调度等等服务。Elastic-Job-Cloud-Scheduler 从节点,因为无法回调
LeaderSelector#takeLeadership()方法,处于"待命"状态。当主节点故障时,从节点会选举出新的主节点,触发LeaderSelector#takeLeadership()方法回调,继续提供服务。
调用
CountLatch#await()方法,挂起主节点LeaderSelector#takeLeadership()方法继续向下执行。为什么要进行挂起?如果调用完该方法,主节点就会让出主节点身份,这样会导致 Elastic-Job-Cloud-Scheduler 集群不断不断不断更新主节点,无法正常提供服务。当 Elastic-Job-Cloud-Scheduler 主节点关闭时,触发上文代码看到的 ShutdownHook ,关闭服务。实现代码如下:
// Bootstrap.java
public final class Bootstrap {public static void main(final String[] args) throws InterruptedException {
// ... 省略无关代码
Runtime.getRuntime().addShutdownHook(new Thread("shutdown-hook") {
@Override
public void run() {
// 停止选举
electionService.stop();
latch.countDown();
}
});
}}调用
ElectionService#stop()方法,停止选举,从而终止领导状态,关闭各种服务。实现代码如下:// ZookeeperElectionService.java
public void stop() {
log.info("Elastic job: stop leadership election");
// 结束 #takeLeadership() 方法的进程挂起
leaderLatch.countDown();
try {
// 关闭 LeaderSelector
leaderSelector.close();
} catch (final Exception ignored) {
}
}
// SchedulerElectionCandidate.java
@Override
public void stopLeadership() {
schedulerService.stop();
}
// SchedulerService.java
/**
* 停止运行.
*/
public void stop() {
restfulService.stop();
taskLaunchScheduledService.stopAsync();
cloudJobConfigurationListener.stop();
statisticManager.shutdown();
producerManager.shutdown();
schedulerDriver.stop(true);
facadeService.stop();
if (env.getFrameworkConfiguration().isEnabledReconcile()) {
reconcileService.stopAsync();
}
}
当发生 JobSystemException 异常时,即调用
SchedulerElectionCandidate#startLeadership()方法发生异常(SchedulerElectionCandidate#stopLeadership()实际不会抛出异常 ),调用System.exit(1)方法,Elastic-Job-Cloud-Scheduler 主节点异常崩溃。目前猜测可能有种情况会导致异常崩溃。(1)一个 Elastic-Job-Cloud-Scheduler 集群有两个节点 A / B,通过选举 A 成为主节点;(2)突然 Zookeeper 集群崩溃,恢复后,A 节点选举恰好又成为主节点,因为未调用
SchedulerElectionCandidate#stopLeadership()关闭原来的各种服务,导致再次调用SchedulerElectionCandidate#startLeadership()会发生异常,例如说 RestfulService 服务,需要占用一个端口提供服务,重新初始化,会发生端口冲突抛出异常。笔者尝试模拟,通过一个 Elastic-Job-Cloud-Scheduler + Zookeeper 的情况,能够触发该情况,步骤如下:(1)Zookeeper 启动;(2)Elastic-Job-Cloud-Scheduler 启动,选举成为主节点,正常初始化;(3)重启 Zookeeper;(4)Elastic-Job-Cloud-Scheduler 再次选举成为主节点,因为 RestfulService 端口冲突异常初始化崩溃。如果真出现这种情况怎么办呢?在「3. Scheduler 部署」揭晓答案。
Elastic-Job-Lite 在主节点选举实现方式上略有不同,有兴趣的同学可以看下《Elastic-Job-Lite 源码分析 —— 主节点选举》的实现。
3. Scheduler 部署
比较容易想到的一种方式,选择多台主机部署 Elastic-Job-Cloud-Executor 多个节点。
But…… 我们要想下,Elastic-Job-Cloud-Executor 运行在 Mesos 之上,可以使用上 Mesos 的资源调度和部署服务。引入 Mesos 上著名的框架 Marathon。它可以带来所有后台进程( 例如,Elastic-Job-Cloud-Executor )能够运行在任意机器上,Marathon 会在后台已有实例失败时,自动启动新实例的好处。是不是很赞 +1024 ?!
FROM 《Mesos 框架构建分布式应用》 P47
Mesos 集群里的常见方案是在 Marathon 上运行集群的 Mesos 框架。但是 Marathon 本身就是一种 Mesos 的框架!那么在 Marathon 上运行 Mesos 框架意味着什么呢?不用考虑如何将每种框架的调度器部署到特定的主机上并且处理这些主机的故障,Marathon 能够确保框架的调度器总是在集群里的某处运行着。这样大幅简化了在高可用配置里部署新框架的复杂度。
嗯…… 当然,Marathon 我们也要做高可用。
? Marathon 原来中文是马拉松。哈哈哈,很适合的名字。
4. Scheduler 故障转移
当原有 Elastic-Job-Cloud-Scheduler 主节点崩溃时,从节点重新进行主节点选举,完成故障转移。那么此时会有一个问题,新主节点如何接管已经在执行中的 Elastic-Job-Cloud-Executer 们呢?
第一种方案,关闭原有的所有 Elastic-Job-Cloud-Executor 们,然后重新调度启动。显然,这个方式太过暴力。如果有些作业任务运行时间较长,直接中断不是很友好。再比如,Elastic-Job-Cloud-Scheduler 节点需要进行升级,也关闭 Elastic-Job-Cloud-Executor,也不合理,和使用高可用性集群操作系统的初衷是背离的。该方案,不推荐。
第二种方案,重用原主节点的 Mesos FrameworkID。原理如下:
FROM 《Mesos 框架构建分布式应用》 P72
在 Mesos 里,调度器由其 FrameworkID、FrameworkInfo 里的可选值唯一确定。FrameworkID 必须由 Mesos 分配,从而确保对于每个框架来说该值是唯一确定的。现在,需要在分配 FrameworkID 时存储该值,这样未来的主实例才可以重用该值。
在 Elastic-Job-Cloud-Scheduler 使用注册中心( Zookeeper ) 的持久数据节点 /${NAMESPACE}/ha/framework_id 存储 FrameworkID,存储值为 ${FRAMEWORK_ID}。使用 zkClient 查看如下:
[zk: localhost:2181(CONNECTED) 1] get /elastic-job-cloud/ha/framework_id
d31e7faa-aa72-4d0a-8941-512984d5af49-0001
调用 SchedulerService#getSchedulerDriver() 方法,初始化 Mesos Scheduler Driver 时,从 Zookeeper 获取是否已经存在 FrameworkID。实现代码如下:
// SchedulerService.java
private SchedulerDriver getSchedulerDriver(final TaskScheduler taskScheduler, final JobEventBus jobEventBus, final FrameworkIDService frameworkIDService) {
// 获取 FrameworkID
Optional frameworkIDOptional = frameworkIDService.fetch();
Protos.FrameworkInfo.Builder builder = Protos.FrameworkInfo.newBuilder();
// 如果存在,设置 FrameworkID
if (frameworkIDOptional.isPresent()) {
builder.setId(Protos.FrameworkID.newBuilder().setValue(frameworkIDOptional.get()).build());
}
// ... 省略无关代码
Protos.FrameworkInfo frameworkInfo = builder.setUser(mesosConfig.getUser()).setName(frameworkName)
.setHostname(mesosConfig.getHostname())
.setFailoverTimeout(FRAMEWORK_FAILOVER_TIMEOUT_SECONDS)
.setWebuiUrl(WEB_UI_PROTOCOL + env.getFrameworkHostPort()).setCheckpoint(true).build();
// ... 省略无关代码
}
调用
FrameworkIDService#fetch()方法,从注册中心获取 FrameworkID 。实现代码如下:public Optionalfetch() {
String frameworkId = regCenter.getDirectly(HANode.FRAMEWORK_ID_NODE);
return Strings.isNullOrEmpty(frameworkId) ? Optional.absent() : Optional.of(frameworkId);
}调用
Protos.FrameworkInfo.Builder#setId(…)方法,当 FrameworkID 存在时,设置 FrameworkID。调用
Protos.FrameworkInfo.Builder#setFailoverTimeout(…)方法,设置 Scheduler 最大故障转移时间,即 FrameworkID 过期时间。Elastic-Job-Cloud-Scheduler 默认设置一周。
当 Elastic-Job-Cloud-Scheduler 集群第一次初始化,上面的逻辑显然获取不到 FrameworkID,在向 Mesos Master 初始化成功后,回调 SchedulerEngine#registered(...) 方法进行保存,实现代码如下:
// SchedulerEngine.java
public final class SchedulerEngine implements Scheduler {
@Override
public void registered(final SchedulerDriver schedulerDriver, final Protos.FrameworkID frameworkID, final Protos.MasterInfo masterInfo) {
log.info("call registered");
// 保存FrameworkID
frameworkIDService.save(frameworkID.getValue());
// 过期 TaskScheduler Lease
taskScheduler.expireAllLeases();
// 注册 Mesos Master 信息
MesosStateService.register(masterInfo.getHostname(), masterInfo.getPort());
}
}
// FrameworkIDService.java
public void save(final String id) {
if (!regCenter.isExisted(HANode.FRAMEWORK_ID_NODE)) { // 不存在才保存
regCenter.persist(HANode.FRAMEWORK_ID_NODE, id);
}
}
5. Scheduler 数据存储
新的 Elastic-Job-Cloud-Scheduler 主节点在故障转移,不仅仅接管 Elastic-Job-Cloud-Executor,还需要接管数据存储。
Elastic-Job-Cloud-Executor 使用注册中心( Zookeeper )存储数据。数据存储分成两部分:
config,云作业应用配置、云作业配置。
state,作业状态信息。
整体如下图:

Elastic-Job-Cloud-Scheduler 各个服务根据数据存储启动初始化。下面来看看依赖数据存储进行初始化的服务代码实现。
5.1 RunningService
RunningService,任务运行时服务。调用 RunningService#start() 方法,启动任务运行队列。实现代码如下:
public final class RunningService {
/**
* 运行中作业映射
* key:作业名称
* value:任务运行时上下文集合
*/
@Getter
private static final ConcurrentHashMap> RUNNING_TASKS = new ConcurrentHashMap<>(TASK_INITIAL_SIZE);
public void start() {
clear();
List jobKeys = regCenter.getChildrenKeys(RunningNode.ROOT);
for (String each : jobKeys) {
// 从运行中队列移除不存在配置的作业任务
if (!configurationService.load(each).isPresent()) {
remove(each);
continue;
}
// 添加 运行中作业映射
RUNNING_TASKS.put(each, Sets.newCopyOnWriteArraySet(Lists.transform(regCenter.getChildrenKeys(RunningNode.getRunningJobNodePath(each)), new Function() {
@Override
public TaskContext apply(final String input) {
return TaskContext.from(regCenter.get(RunningNode.getRunningTaskNodePath(TaskContext.MetaInfo.from(input).toString())));
}
})));
}
}
}
因为运行中作业映射(
RUNNING_TASKS)使用的频次很多,Elastic-Job-Cloud-Scheduler 缓存在内存中。每次初始化时,使用从数据存储运行中作业队列加载到内存。这里我们在看下运行中作业队列的添加(
#add())方法,实现代码如下:public void add(final TaskContext taskContext) {
if (!configurationService.load(taskContext.getMetaInfo().getJobName()).isPresent()) {
return;
}
// 添加到运行中的任务集合
getRunningTasks(taskContext.getMetaInfo().getJobName()).add(taskContext);
// 判断是否为常驻任务
if (!isDaemon(taskContext.getMetaInfo().getJobName())) {
return;
}
// 添加到运行中队列
String runningTaskNodePath = RunningNode.getRunningTaskNodePath(taskContext.getMetaInfo().toString());
if (!regCenter.isExisted(runningTaskNodePath)) {
regCenter.persist(runningTaskNodePath, taskContext.getId());
}
}运行中作业队列只存储常驻作业的任务。所以瞬时作业,在故障转移时,可能存在相同作业相同分片任务同时调度执行。举个栗子?,Elastic-Job-Cloud-Scheduler 集群有两个节点 A( 主节点 ) / B( 从节点 ),(1)A 节点每 5 分钟调度一次瞬时作业任务 T ,T 每次执行消耗时间实际超过 5 分钟( 先不要考虑是否合理 )。(2)A 节点崩溃,B 节点成为主节点,5 分钟后调度 T 作业,因为运行中作业队列只存储常驻作业的任务,恢复后的
RUNNING_TASKS不存在该作业任务,因此可以调度 T 作业,实际 T 作业正在 Elastic-Job-Cloud-Executor 执行中。
5.2 ProducerManager
ProducerManager,发布任务作业调度管理器。调用 ProducerManager#startup() 方法,启动作业调度器。实现代码如下:
public final class ProducerManager {
public void startup() {
log.info("Start producer manager");
// 发布瞬时作业任务的调度器
transientProducerScheduler.start();
// 初始化调度作业
for (CloudJobConfiguration each : configService.loadAll()) {
schedule(each);
}
}
}
调用
ConfigService#loadAll()方法,从数据存储读取所有作业配置。调用
#schedule()方法,初始化调度作业。瞬时作业,在 Elastic-Job-Cloud-Scheduler 计时调度,类似每 XX 秒 / 分 / 时 / 天之类的作业需要重新计时,这个请注意。
常驻作业,在 Elastic-Job-Cloud-Executor 计时调度,暂无影响。
在《Elastic-Job-Cloud 源码分析 —— 作业调度(一)》「3. Producer 发布任务」有详细解析。
5.3 TaskScheduler
TaskScheduler,Fenzo 作业调度器,根据 Mesos Offer 和作业任务的优化分配。因为其分配是依赖当前实际 Mesos Offer 和 作业任务运行的情况,猜测可能对优化分配有影响,但不影响正确性。笔者对 TaskScheduler 了解不是很深入,仅仅作为猜测。
在《Elastic-Job-Cloud 源码分析 —— 作业调度(一)》「4.1」「4.2」「4.3」有和 TaskScheduler 相关的内容解析。
6. Mesos Master 崩溃
Mesos Master 集群,Mesos Master 主节点崩溃后,Mesos Master 集群重新选举后,Scheduler、Mesos Slave 从 Zookeeper 获取到最新的 Mesos Master 主节点重新进行注册,不影响 Scheduler 、Mesos Slave 、任务执行。
调用 SchedulerService#getSchedulerDriver(...) 方法,设置 SchedulerDriver 从 Mesos Zookeeper Address 读取当前 Mesos Master 地址,实现代码如下:
// SchedulerService.java
private SchedulerDriver getSchedulerDriver(final TaskScheduler taskScheduler, final JobEventBus jobEventBus, final FrameworkIDService frameworkIDService) {
// ... 省略无关代码
MesosConfiguration mesosConfig = env.getMesosConfiguration();
return new MesosSchedulerDriver(new SchedulerEngine(taskScheduler, facadeService, jobEventBus, frameworkIDService, statisticManager), frameworkInfo, mesosConfig.getUrl() // Mesos Master URL
);
}
// MesosSchedulerDriver.java
public MesosSchedulerDriver(Scheduler scheduler,
FrameworkInfo framework,
String master) {
// ... 省略无关代码
}
MesosSchedulerDriver 构造方法第三个参数
master,代表 Mesos 使用的 Zookeeper 地址,例如:zk://127.0.0.1:2181/mesos。生产环境请配置多 Zookeeper 节点,例如:zk://host1:port1,host2:port2,…/path。使用 zkClient 查看如下:
[zk: localhost:2181(CONNECTED) 10] ls /mesos
[log_replicas, json.info_0000000017]
[zk: localhost:2181(CONNECTED) 11] get /mesos/json.info_0000000017
{"address":{"hostname":"localhost","ip":"127.0.0.1","port":5050},"hostname":"localhost","id":"685fe32d-e30c-4df7-b891-3d96b06fee88","ip":16777343,"pid":"[email protected]:5050","port":5050,"version":"1.4.0"}
Elastic-Job-Cloud-Scheduler 注册上、重新注册上、断开 Mesos Master 实现代码如下:
public final class SchedulerEngine implements Scheduler {
@Override
public void registered(final SchedulerDriver schedulerDriver, final Protos.FrameworkID frameworkID, final Protos.MasterInfo masterInfo) {
log.info("call registered");
// ... 省略无关代码
// 注册 Mesos Master 信息
MesosStateService.register(masterInfo.getHostname(), masterInfo.getPort());
}
@Override
public void reregistered(final SchedulerDriver schedulerDriver, final Protos.MasterInfo masterInfo) {
// ... 省略无关代码
// 注册 Mesos Master 信息
MesosStateService.register(masterInfo.getHostname(), masterInfo.getPort());
}
@Override
public void disconnected(final SchedulerDriver schedulerDriver) {
log.warn("call disconnected");
MesosStateService.deregister();
}
}
MesosStateService,Mesos状态服务,提供调用 Mesos Master API 服务,例如获取所有执行器。
调用
MesosStateService#register(...)方法,注册 Mesos Master 信息,实现代码如下:public class MesosStateService {private static String stateUrl;
public static synchronized void register(final String hostName, final int port) {
stateUrl = String.format("http://%s:%d/state", hostName, port);
}}调用
MesosStateService#deregister(...)方法,注销 Mesos Master 信息,实现代码如下:public static synchronized void deregister() {
stateUrl = null;
}
《Mesos 框架构建分布式应用》P110 如何处理 master 的故障,有兴趣的同学也可以仔细看看。
7. Mesos Slave 崩溃
在《Elastic-Job-Cloud 源码分析 —— 作业失效转移》中,搜索关键字 "TASK_LOST",有 Mesos Slave 崩溃后,对 Elastic-Job-Cloud-Scheduler 和 Elastic-Job-Cloud-Executor 的影响。
《Mesos 框架构建分布式应用》P109 如何处理 slave 的故障,有兴趣的同学也可以仔细看看。
8. Scheduler 核对
FROM http://mesos.apache.org/documentation/latest/reconciliation/
Messages between framework schedulers and the Mesos master may be dropped due to failures and network partitions. This may cause a framework scheduler and the master to have different views of the current state of the cluster. For example, consider a launch task request sent by a framework. There are many ways that failures can prevent the task launch operation from succeeding, such as:
Framework fails after persisting its intent to launch the task, but before the launch task message was sent.
Master fails before receiving the message.
Master fails after receiving the message but before sending it to the agent.
通过核对特性解决这个问题。核对是协调器如何和 Mesos Master 一起检查调度器所认为的集群状态是否和 Mesos Master 所认为的集群状态完成匹配。
调用 SchedulerDriver#reconcileTasks(...) 方法,查询任务状态。代码接口如下:
public interface SchedulerDriver {
Status reconcileTasks(Collection statuses) ;
}
只能查询非终止状态( non-terminal )的任务。核对的主要原因,确认任务是否还在运行,或者已经进入了中断状态。
terminal:TASK_ERROR、TASK_FAILED、TASK_FINISHED、TASK_KILLED
non-terminal:TASK_DROPPED、TASK_GONE、TASK_GONE_BY_OPERATOR、TASK_KILLING、TASK_LOST、TASK_RUNNING、TASK_STAGING、TASK_STARTING、TASK_UNREACHABLE、TASK_UNKNOWN
当
statuses非空时,显示查询,通过回调Scheduler#statusUpdate(…)方法异步返回指定的任务的状态。当
statuses为空时,隐式查询,通过回调Scheduler#statusUpdate(…)方法异步返回全部的任务的状态。
ReconcileService,核对 Mesos 与 Scheduler 之间的任务状态。实现代码如下:
public class ReconcileService extends AbstractScheduledService {
private final ReentrantLock lock = new ReentrantLock();
@Override
protected void runOneIteration() throws Exception {
lock.lock();
try {
explicitReconcile();
implicitReconcile();
} finally {
lock.unlock();
}
}
@Override
protected Scheduler scheduler() {
FrameworkConfiguration configuration = BootstrapEnvironment.getInstance().getFrameworkConfiguration();
return Scheduler.newFixedDelaySchedule(configuration.getReconcileIntervalMinutes(), configuration.getReconcileIntervalMinutes(), TimeUnit.MINUTES);
}
}
通过配置
FrameworkConfiguration#reconcileIntervalMinutes设置,每隔多少分钟执行一次核对。若配置时间大于 0 才开启任务状态核对功能。调用
#explicitReconcile()方法,查询运行中的任务。实现代码如下:public void explicitReconcile() {
lock.lock();
try {
// 获取运行中的作业任务上下文集合
SetrunningTask = new HashSet<>();
for (Seteach : facadeService.getAllRunningTasks().values()) {
runningTask.addAll(each);
}
if (runningTask.isEmpty()) {
return;
}
log.info("Requesting {} tasks reconciliation with the Mesos master", runningTask.size());
// 查询指定任务
schedulerDriver.reconcileTasks(Collections2.transform(runningTask, new Function
@Override
public Protos.TaskStatus apply(final TaskContext input) {
return Protos.TaskStatus.newBuilder()
.setTaskId(Protos.TaskID.newBuilder().setValue(input.getId()).build())
.setSlaveId(Protos.SlaveID.newBuilder().setValue(input.getSlaveId()).build())
.setState(Protos.TaskState.TASK_RUNNING)
.build();
}
}));
} finally {
lock.unlock();
}
}调用
#implicitReconcile()方法,查询所有任务。实现代码如下:public void implicitReconcile() {
lock.lock();
try {
// 查询全部任务
schedulerDriver.reconcileTasks(Collections.emptyList());
} finally {
lock.unlock();
}
}为什么这里要使用 ReentrantLock 锁呢?Elastic-Job-Cloud-Scheduler 提供 CloudOperationRestfulApi,支持使用 HTTP Restful API 主动触发
#explicitReconcile()和#implicitReconcile()方法,通过锁避免并发核对。对 CloudOperationRestfulApi 有兴趣的同学,直接点击链接查看实现。虽然
#implicitReconcile()方法,能查询到所有 Mesos 任务状的态,但是性能较差,而#explicitReconcile()方法显式查询运行中的 Mesos 任务的状态,性能更好,所以先进行调用。优化点(目前暂未实现):Elastic-Job-Cloud-Scheduler 注册到 Mesos 和 重注册到 Mesos,都执行一次核对。
FROM 《Elastic-Job-Lite 源码分析 —— 自诊断修复》
This reconciliation algorithm must be run after each (re-)registration.
其他 Scheduler 核对资料,有兴趣的同学可以看看:
《Mesos 框架构建分布式应用》P76 添加核对 、P111 故障转移期间的核对
《Mesos 官方文档 —— reconciliation》
Elastic-Job-Lite 也会存在作业节点 和 Zookeeper 数据不一致的情况,有兴趣的同学可以看下《Elastic-Job-Lite 源码分析 —— 自诊断修复》的实现。
666. 彩蛋
给英文和我一样半斤八两的同学一本葵花宝典+辟邪剑谱:
《Mesos中文手册》。
《Mesos 容错、故障》

整个 Elastic-Job-Cloud 完结,撒花!
收获蛮多的,学习的第一套基于云原生( CloudNative )实现的中间件,期待有基于云原生的服务化中间件。
一开始因为 Elastic-Job-Cloud 基于 Mesos 实现,内心还是有点恐惧感,后面硬啃 + 搭配《Mesos 框架构建分布式应用》,比预想的时间快了一半完成这个系列。在这里强烈推荐这本书。另外,等时间相对空,会研究下另外一个沪江开源的基于 Mesos 实现的分布式调度系统 Juice。不是很确定会不会出源码解析的文章,尽量输出噶。
后面会继续更新源码解析系列,下一个系列应该是《tcc-transaction 源码解析》。在选择要研究的 tcc 中间件还是蛮纠结的,哈哈,这里听从 zhisheng 的建议。如果不好,我保证会打死你的。
希望坚持不懈的分享源码解析会有更多的同行者阅读。确实,源码解析的受众略小。
道友,赶紧上车,分享一波朋友圈!
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:



如果你喜欢这篇文章,喜欢,转发。
生活很美好,明天见(。・ω・。)ノ♡