50 行代码教 AI 实现动作平衡 | 附完整代码

【CSDN 编者按】本文将为大家展示如何通过 Numpy 库和 50行 Python 代码,使用标准的 OpenAI Gym平台创建智能体 (Agent),就教会机器处理推车杆问题 (Cart Pole Problem) ,保持平衡。

作者 | Mike Shi
译者 | linstancy
责编 | Jane
出品 | AI科技大本营(id:rgznai100)
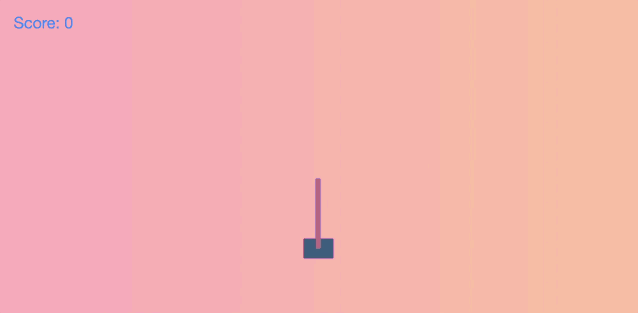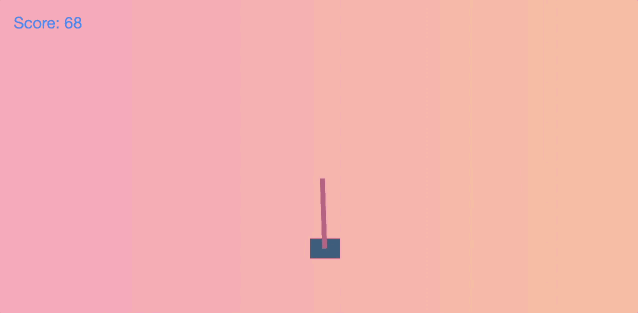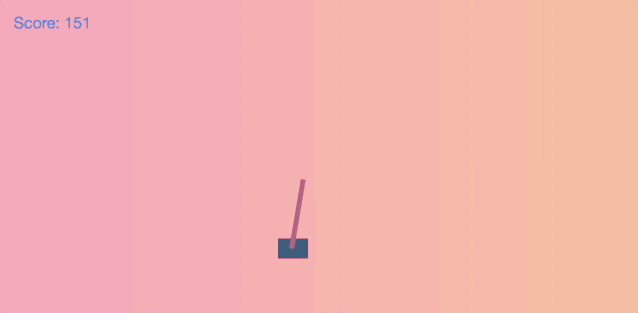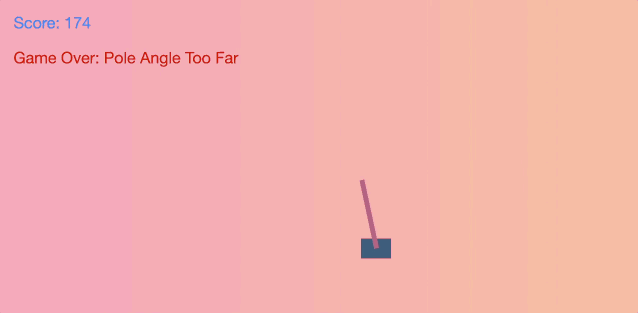
推车杆问题 (cart pole problem) ,大家可以类比好像在手指尖上垂直平衡铅笔一样,需要通过左右推动来平衡车顶部的杆,这是个非常具有挑战性的问题!
今天,我们不过多的讨论强化学习的基础理论,希望大家在下面的编译器里,不断尝试,体会这个项目。一开始,大家只需要点击“Start”,开始配置需要的环境即可。


快速入门强化学习 (RL)
如果你是机器学习或强化学习领域的新人,先了解一下下面的一些基础知识和术语,为后面做铺垫。如果你已经掌握了基础知识,那可以跳过这部分内容。
-
强化学习
强化学习旨在教会我们的智能体 (算法或机器) 执行特定的任务或动作,而无需显式地告诉它该如何做。想象一个婴儿在随机抬动自己的腿,当站立起来时就给予他一个奖励。同样地,智能体的目标是在其生命周内最大化奖励值,而奖励取决于特定的任务。比如宝宝站立这个例子,站立时给予奖励记为1,否则记为0。
AlphaGo 就是一个典型的强化学习智能体例子,教会智能体如何玩游戏并最大化其奖励 (即赢得游戏)。而在本文中就将创建一个智能体,教它如何通过左右推动推车来解决推车上的杆平衡问题。
-
状态
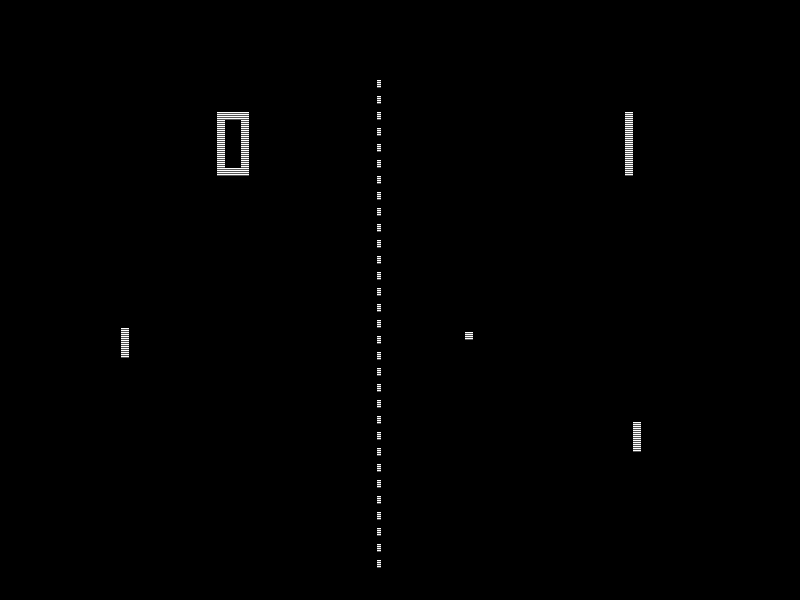
状态即当前游戏的样子,通常用数字来表示。在乒乓球比赛中,它可能是每个球拍与x、y坐标轴的垂直位置或者是乒乓球的速度。在推车杆的情况下,这里的状态由4个数字组成:即推车的位置,推车的速度,杆的位置 (作为角度) 和杆的角速度。这4个数字作为向量 (或数组) 提供给智能体,这非常重要:将状态作为一组数字意味着智能体能够对它进行一些数学运算,以便决定如何根据状态来采取什么行动。
-
策略
策略是一种可以处理游戏状态的函数 (例如棋盘的位置或者推车和杆的位置), 并输出智能体在该位置应该采取的动作 (例如移动或将推车推到左边)。在智能体采取相应的操作后,游戏将以下一个状态更新,此时将再次根据其输入策略做出决策,这个过程一直持续到游戏达到某个终止条件时结束。策略同样是个非常关键的因素,因为它反映了是智能体背后的决策能力,这也是我们所需要认真考虑的。
-
点积 (Dot Product)
两个数组 (向量) 之间的点积可以简单理解为,将第一个数组的每个元素乘以第二个数组的对应元素,并将它们全部加在一起。假设想要计算数组 A 和 B 的点积,形如 A[0]*B[0]+A[1]*B[1] ......随后将使用此运算结果再乘以一个状态 (同样是一个向量) 和一个策略值 (同样也是一个向量)。这部分内容将在下一节详细介绍。

制定策略
为了解决推车游戏,我们希望所设计的机器学习策略能够赢得游戏或最大化游戏奖励。对于智能体而言,这里将接收4维数组所表示策略,每一维代表每个组成的重要性 (推车的位置,杆位等四个组成)。随后,再将点积的结果与策略、状态向量进行处理并输出最终的结果。根据结果的正负值决定是向左还是向右推动推车。这听起来可能有点抽象,下面就通过一个具体的例子,来看看整个过程将发生什么。
假设推车在游戏中静止地处在中间位置,当杆向右倾斜时车也将向右倾斜,如下图这样:
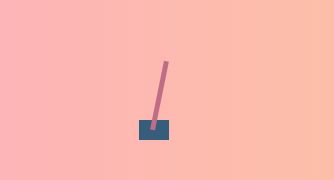
所对应的的状态如下图所示:
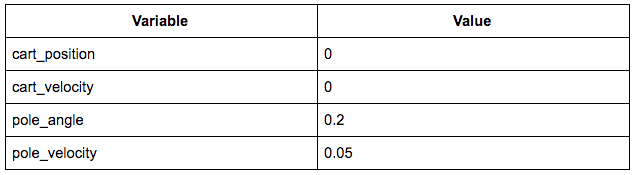
此时的状态向量为 [0, 0, 0.2, 0.05]。直观地说,现在我们想要将推车推向右侧,并将杆拉直。这里通过训练中得到了一个很好的策略,即 [-0.116, 0.332, 0.207, 0.352]。将上面的状态向量与策略向量进行点积处理,如果得到的结果为正,则将推车向右推动;反之则向左推动。

显然,这里的输出是个正数,这意味着在这种策略下智能体将推车向右推动,这也正是我们想要的结果。那么,该如何得到这个策略向量呢,以便智能体能够朝着我们希望的方向推动?或者说如果随机选择一个策略,那么智能体又该如何行动呢?
牛了,这几个案例让你迅速掌握AI技术!
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw

开始编辑
在该项目主页 repl.it 上弹出一个 Python 实例。repl.it允许用户快速启动大量不同编程环境的云实例环境并在强大云编译器 (IDE) 中编辑代码,这个强大的 IDE 能在任何地方访问,如下图所示。


安装所需的包
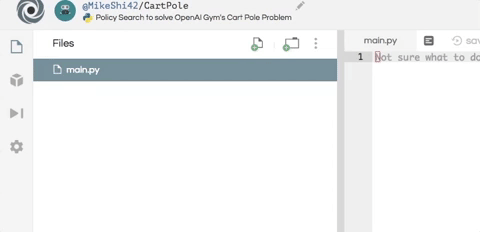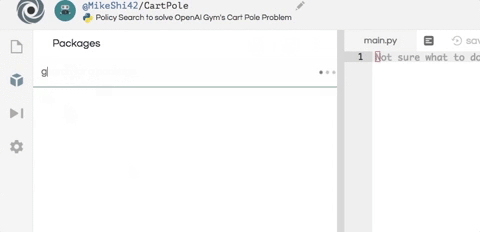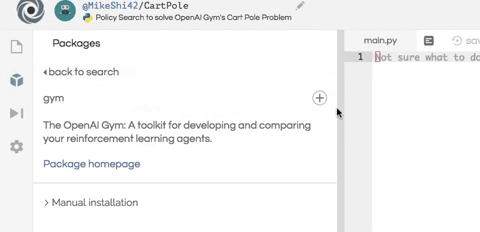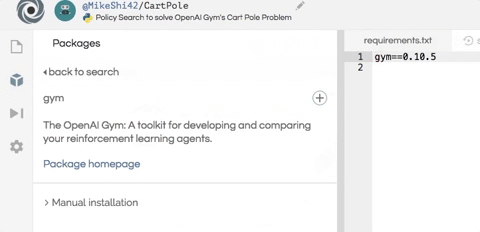
安装这个项目所需的两个软件包:numpy 用于帮助数值计算,而 OpenAI Gym 则作为智能体的模拟器。如下图所示,只需在编辑器左侧的包搜索工具中输入 gym 和 numpy,然后单击加号按钮即可安装这两个包。

创建基础环境
这里首先将刚安装的两个依赖包导入到 main.py 脚本中并设置一个新的 gym环境。随后定义一个名为 play 的函数,该函数将被赋予一个环境和一个策略向量,在环境中执行策略向量并返回分数以及每个时间步的游戏观测值。最后,将通过分数高低来反映策略的效果好坏,以及在单次游戏中策略的表现。如此,就可以测试不同的策略,查看他们在游戏中的表现!
下面从函数定义开始,将游戏重置为开始状态,如下所示。
def play(env, policy):
observation = env.reset()
接着初始化一些变量,用来跟踪游戏是否达到终止条件,策略得分以及游戏中每个步骤的观测值,如下所示。
done = False
score = 0
observations = []
现在,只需要一些时间步来开始游戏,直到 gym 提示游戏结束为止。
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
如下,这部分的代码主要是用于开始游戏并记录结果,而与策略相关的代码就是这两行:
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
在这里所做的只是对策略向量和状态 (观测) 数组之间进行点积运算,就像在之前具体例子中所展现的那样。随后根据结果的正负,选择1或0 (向左或右) 的动作。到这里为止,main.py 脚本如下所示:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy):
observation = env.reset()
done = False
score = 0
observations = []
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
下面开始寻找该游戏的最优策略!

第一次游戏
现在已经有了一个函数,用来反映策略的好坏。因此,接下来要做的事开始制定一些策略,并查看他们的表现如何。如果一开始你想尝试一些随机的策略,那么这些策略的结果将会怎样呢?这里使用 numpy 来随机生成一些的策略,这些策略都是4维数组或1x4矩阵,即选择4个0到1之间的数字作为游戏的策略,如下所示。
policy = np.random.rand(1,4)
有了这些策略以及上面所创建的环境,下面就可以开始游戏并获得策略分数:
score, observations = play(env, policy)
print('Policy Score', score)
只需点击运行即可开始游戏,它将输出每个策略所对应的得分,如下所示。
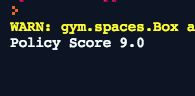
最后,所有的策略获得的最高得分为500,在这里随机生成的策略可能并不能得到太好的结果,而且通过随机生成的方式,很难解释智能体是如何进行游戏的。下一步将介绍如何选择并设置游戏的策略,来查看智能体的游戏表现。

观察我们的智能体
这里使用 Flask 来设置轻量级服务器,以便可以在浏览器中查看智能体的表现。 Flask 是一个轻量级的 Python HTTP 服务器框架,可以为 HTML UI 和数据提供服务。由于渲染和 HTTP 服务器背后的细节对智能体的训练并不重要,在这里只是简单介绍下。首先需要将 Flask 安装为 Python 包,就像上面安装 gym 和 numpy 包一样,如下所示。
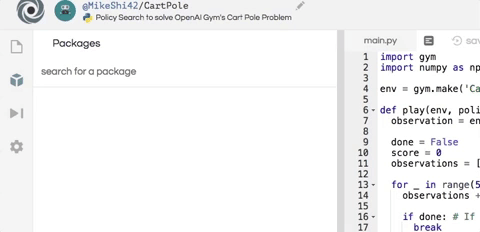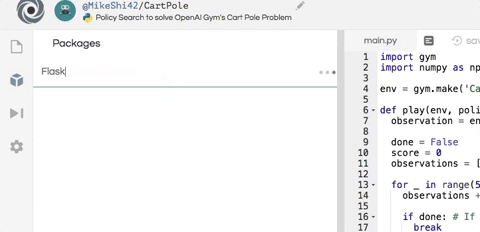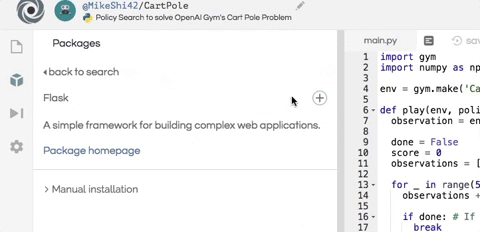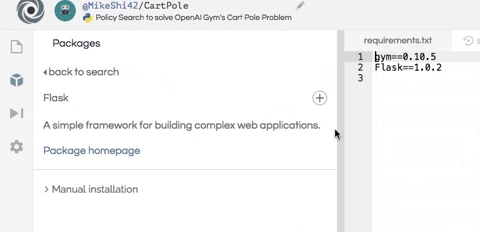
接下来,在脚本的底部创建一个 flask 服务器,它将在 /data 端点上公开游戏的每个帧的记录,并在 / 上托管 UI,如下所示。
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data():
return json.dumps(observations)
@app.route('/')
def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
此外,还需要添加两个文件:一个是项目的空白 Python 文件,这是 repl.it 用于检测 repl 是处于评估模式还是项目模式的关键。这里只需使用新文件按钮添加空白的 Python 脚本即可。随后,还需要创建一个将承载渲染 UI 的 index.html 文件。在此不需要深入了解这部分的内容,只需将此 index.html 上传到 repl.it 项目即可。
好了,现在的项目目录应该像这样,如下所示:
有了这两个新文件,当运行 repl 时它将回放所选择的游戏策略,便于我们寻找一个最优的策略。


策略搜索
在第一次游戏中只是通过 numpy 为智能体随机生成一些策略并开始游戏。那么,如何选择一些游戏策略,并在游戏结束时只保留那个结果最好的策略呢?在这里,制定游戏时并不只是生成一个策略,而是通过编写一个循环来生成一些策略,跟踪每个策略的执行情况并在最后保存最佳的策略。
首先创建一个名为 max 的元组,它将存储游戏过程所出现的最佳策略得分、观测和策略数组,如下所示。
max = (0, [], [])
接下来将生成并评估10个策略,并将得分最大值的策略保存。此外,这里还需要在 /data 端点返回最佳策略的重放,如下所示。
for _ in range(10):
policy = np.random.rand(1,4)
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)
print('Max Score', max[0])
此外,这个端点:
@app.route("/data")
def data():
return json.dumps(observations)
应改为:
@app.route("/data")
def data():
return json.dumps(max[1])
最后 main.py 脚本应像这样,如下图所示:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy):
observation = env.reset()
done = False
score = 0
observations = []
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
max = (0, [], [])
for _ in range(10):
policy = np.random.rand(1,4)
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)
print('Max Score', max[0])
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data():
return json.dumps(max[1])
@app.route('/')
def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
如果现在运行 repl,正常情况所得到的最大分数应为500。如果没有的话,请再次尝试运行 repl! 通过这种方式,能够完美地观察游戏策略是如何让杆达到平衡的!

如何加速?
(1)这里智能体达到平衡的速度并不够块。回想前面制定策略时,首先只是在0到1范围内随机创建了策略数组,这恰好是有效的。但如果这里智能体翻转大于运算符所设定的那样,那么可能将看到灾难性的失败结果。可以尝试将 action> 0 if outcome>0 else 0 改为 action=1 if outcome<0 else 0。
效果似乎并没有很明显,这可能是因为如果恰好选择少于而不是大于,那么可能永远也找不到解决游戏的策略。为了缓解这种情况,在实际操作时也应该生成一些带负数的策略。虽然这将使得搜索一个好策略的过程变得更加困难 (因为包含许多负的策略并不好),但所带来的好处是不再需要通过特定算法来匹配特定游戏。如果尝试在 OpenAI gym 的其他环境中这样做,那么算法肯定会失败。
要做到这一点,不能使用 policy = np.random.rand(1,4),需要将改为 policy = np.random.rand(1,4) -0.5。如此,所生成的策略中每个数字都在-0.5到0.5之间,而不是0到1。但是由于这样做会使得最优策略的搜索过程变得困难,因此在上面的 for 循环中,不要迭代10个策略,更改这部分的代码尝试搜索100个策略 (for _ in range (100):)。当然,你也可以先尝试迭代10次,看看用负的策略获得最优策略的困难性。
好了,现在的 main.py 脚本可参考
https://gist.github.com/MikeShi42/e1c5551bbf2cb2064da962ad8b198c1b
如果现在运行 repl,无论使用的是否大于或小于,仍然可以找到一个好的游戏策略。
(2)不仅如此,即使所生成的策略可能能够在一次游戏中得到最高分500的结果,那它能够在每次游戏中都有这样的表现呢?当生成100个策略并选择在单次运行中表现最佳的策略时,该策略可能只是单次最佳策略,或者它可能是一个非常糟糕的策略,只是恰好在一次游戏中有非常好的性能。因为游戏本身具有随机性 (如起始位置每次都不同),因此策略可以只是在一个起始位置表现良好,而不是在其他位置。
因此,为了解决这个问题,需要评估一个策略在多次实验中的表现。现在就采取之前实验得到的最佳政策,查看它在100次游戏实验中的表现。在这里对最优策略进行100次游戏 (最大索引值为2) 并记录每次的游戏得分。随后使用 numpy 计算该策略的平均分数并将其打印到终端。你可能会注意到,最佳的游戏策略实际上并不一定是最优秀的。

总结
好了,以上已经成功创建了一个能够非常有效地解决推车杆问题的 AI 智能体。当然它还有很大的改进空间,这将是后续系列文章的一部分。此外,后续的工作还可以对一些问题展开研究:
-
寻找“真正的”最优策略 (即在100次独立游戏中表现良好)
-
优化最佳策略搜索所需的次数 (即样本效率问题)
-
选择正确搜索策略,而不是尝试随机地选择。
-
在其他的环境中创建。
原文地址:
https://towardsdatascience.com/from-scratch-ai-balancing-act-in-50-lines-of-python-7ea67ef717
2019年人工智能系统学:
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
【END】

「2019以太坊技术及应用大会」门票惊喜大促!
V神携手众多海内外知名区块链专家来北京啦!自6月14日起,大会隆重推出618特惠票,低至399元,感恩新老用户,惊喜不断,虚左以待!扫码了解详情。

热 文 推 荐
☞为什么说 5G 是物联网的时代?
☞互联网公司没有中年人
☞教你用OpenCV实现机器学习最简单的k-NN算法
Docker 存储选型,这些年我们遇到的坑
☞荔枝自由?朋友,你实现了吗?
开源要自立?华为如何“复制”Google模式
☞从制造业转型物联网,看博世如何破界
回报率850%? 这个用Python优化的比特币交易机器人简直太烧脑了...
☞老码农冒死揭开编程黑幕:这些Bug让我认输,谁踩谁服!
 点击阅读原文,精彩继续。
点击阅读原文,精彩继续。
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢