
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来。写这个程序的主要目的是抓取海投网的宣讲会信息(公司、时间、地点)并在移动端显示,这样就可以随时随地的浏览在学校举办的宣讲会信息了。
一、Jsoup简介
Jsoup 是一个 Java 的开源HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常方便的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup主要有以下功能:
-
从一个URL,文件或字符串中解析HTML;
-
使用DOM或CSS选择器来查找、取出数据;
-
对HTML元素、属性、文本进行操作;
-
清除不受信任的HTML (来防止XSS攻击)
好了,下面写几段代码来说明 Jsoup 是如何优雅的进行 HTML 文档处理的。首先,我们需要去Jsoup官网 下载Jsoup的jar包,然后加入项目的依赖库中。
1) HTML解析
Jsoup 可以从一个字符串、文件或者一个 URL 中解析HTML,解析的目的主要是为了得到一个干净完整的解析结果,并生成 Document 对象实例。
// Parse a document from a String
String html = "神奕的博客 "
+"搭个博客写学习笔记!!
";
Document doc = Jsoup.parse(html);
// Load a Document from a File
File input = new File("D://a.html");
Document doc = Jsoup.parse(input, "UTF-8");
// Load a Document from a URL
Document doc = Jsoup.connect("http://example.com/").get();当加载和解析一个本地的HTML文件时,如果在加载文件的时候发生错误,将抛出 IOException,应作适当处理。
2) 数据提取
将HTML解析成一个Document之后,就可以使用传统的 DOM 方法进行数据抽取。例如:
// 海投网
String url = "http://xjh.haitou.cc/wh/uni-1/after/hold/page-1/";
Document doc = Jsoup.connect(url).get();
Elements elements = doc.getElementsByTag("company");
for(Element e : elements) {
System.out.println(e.text());
}Document 对象和 Elements 对象提供了一系列类似于DOM的方法来查找元素,比如 getElementById(String id)、getElementsByTag(String tag) 等等。更多方法请看《Jsoup Cookbook》。
另外,还可以使用 Selector 选择器(类似于CSS或jQuery语法)来查找元素。如下:
// 海投网
String url = "http://xjh.haitou.cc/wh/uni-1/after/hold/page-1/";
Document doc = Jsoup.connect(url).get();
// 通过标签company查找元素
Elements company = doc.select("company");
// 带有href属性的a元素
Elements links = doc.select("a[href]");
// 扩展名为.png的图片
Elements pngs = doc.select("img[src$=.png]");
// class等于content的div标签
Element content = doc.select("div.content").first(); 选择器实现了非常强大和灵活的查找功能。select方法在Document、Element 或 Elements 对象中都可以使用,且是上下文相关的,因此可实现指定元素的过滤或者链式选择访问。select方法将返回一个Elements集合,并提供一组方法来抽取和处理结果。
通过 DOM 方法或者 Selector 方法查找到一些 Elements 元素之后,我们需要从这些元素中取得数据,下面是几个常用的方法:
-
取得一个属性的值,可以使用
Node.attr(String key)方法; -
取得一个元素中的文本,可以使用
Element.text()方法; -
取得元素或属性中的HTML内容,可用
Element.html()或Node.outerHtml()方法 -
取得一个元素的 id :
Element.id() -
取得一个元素的标签名:
Element.tagName() -
取得一个元素的类名:
Element.className()
3) 数据修改
在解析一个 Document 之后可能想修改其中的某些属性值、HTML或文本内容,然后再保存到磁盘或都输出到前台页面。例如:我们可以为文档中的所有图片增加可点击链接、修改链接地址或者是修改文本等。Jsoup 提供了很多方法用来进行修改,这里就不列举了,请移步 Jsoup Cookbook。
二、海投网的页面抓取
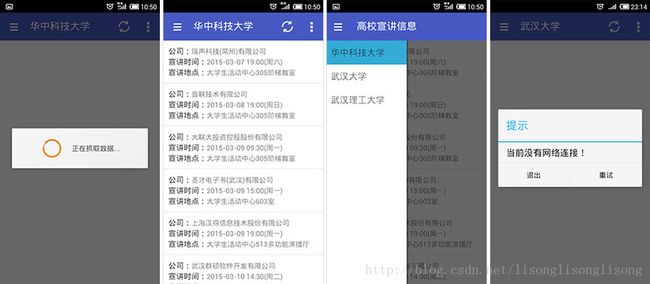
海投网是一个为高校毕业生服务的招聘信息网,创始人是华中科技大学的毕业生。现在我要抓取在华中科技大学举办的宣讲会的信息,网页如下图:

查看网页源代码,如下图:
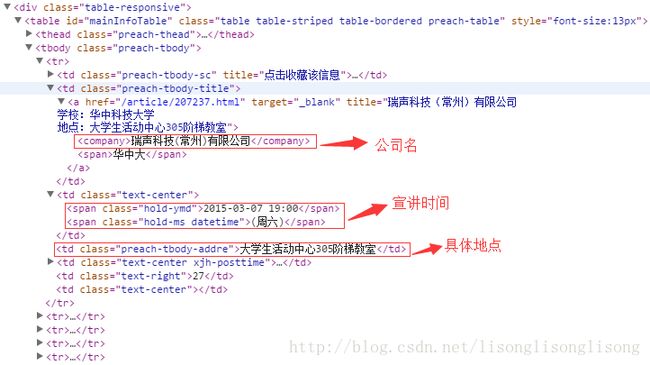
可以看出,公司名是在一个 company 标签内,宣讲会时间是在一个类名为 text-center 的 td 标签内,学校的具体地点则是在一个类名为 preach-tbody-addre 的 td 标签内。这么一分析,要提取华中科技大学的宣讲会信息就变得挺简单了。
Java代码如下:
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
String url = "http://xjh.haitou.cc/wh/uni-1/after/hold/page-1/";
Connection conn = Jsoup.connect(url);
// 修改http包中的header,伪装成浏览器进行抓取
conn.header("User-Agent", "Mozilla/5.0 (X11; Linux x86_64; rv:32.0) Gecko/ 20100101 Firefox/32.0");
Document doc = conn.get();
// 获取tbody元素下的所有tr元素
Elements elements = doc.select("tbody tr");
for(Element element : elements) {
String companyName = element.getElementsByTag("company").text();
String time = element.select("td.text-center").first().text();
String address = element.getElementsByClass("preach-tbody-addre").text();
System.out.println("公司:"+companyName);
System.out.println("宣讲时间:"+time);
System.out.println("宣讲学校:华中科技大学");
System.out.println("具体地点:"+address);
System.out.println("---------------------------------");
}
}
}某些网站禁止爬虫,不能抓取或者抓取一定数量后封IP。这时候我们需要伪装成浏览器进行抓取,这可以通过修改http包中的header来实现(设置User-Agent)。运行上面的程序得到输出结果:
公司:瑞声科技(常州)有限公司
宣讲时间:2015-03-07 19:00(周六)
宣讲学校:华中科技大学
具体地点:大学生活动中心305阶梯教室
---------------------------------
公司:普联技术有限公司
宣讲时间:2015-03-08 19:00(周日)
宣讲学校:华中科技大学
具体地点:大学生活动中心305阶梯教室
---------------------------------
公司:大联大投资控股股份有限公司
宣讲时间:2015-03-09 09:30(周一)
宣讲学校:华中科技大学
具体地点:大学生活动中心305阶梯教室
---------------------------------
......三、应用到Android程序中
开发 Android 程序,你需要搭建开发环境,很简单:先安装Java的JDK(最好不低于1.6),然后去Android官网下载并安装 Android Studio 就行了。
在Android程序中使用 Jsoup 需要注意两点:
-
在AndroidManifest.xml文件中添加网络访问权限
android.permission.INTERNET -
Android在4.0之后,不允许在主线程里执行网络(http)请求,也就是说 Jsoup 的代码需要写在子线程里。
1) 多线程
4.0 版本以后,如果你在主线程里尝试进行网络操作,会报android.os.NetworkOnMainThreadException 的异常。所以我们需要开辟子线程进行异步加载,用到Thread、Runnable、Handler这三个类:
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
this.setContentView(R.layout.share_mblog_view);
// 开辟一个线程
new Thread(runnable).start();
}
Runnable runnable = new Runnable(){
@Override
public void run() {
/**
* 要执行的操作
*/
// 执行完毕后给handler发送一个空消息
handler.sendEmptyMessage(0);
}
}
Handler handler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
/**
* 处理UI
*/
// 当收到消息时就会执行这个方法
}
}2) 判断网络连接是否可用
如果在没有可用网络的情况下执行网络爬虫程序,App将会报错。所以在每次执行之前都应该先判断网络是否可用。大致步骤如下:
① 获取ConnectivityManager对象
Context context = activity.getApplicationContext();
// 获取手机所有连接管理对象(包括对wi-fi,net等连接的管理)
ConnectivityManager cm = (ConnectivityManager)context.getSystemService(Context.CONNECTIVITY_SERVICE);
NetworkInfo info = cm.getActiveNetworkInfo();
// WIFI 判定条件
info != null && info.getType() == ConnectivityManager.TYPE_WIFI
// 手机网络 判定条件
info !=null && info.getType() == ConnectivityManager.TYPE_MOBILE而手机网络具体又分为很多类,比如移动3G、移动2G、联通2G等等。这里就不说了,自行Google。
④ 判断网络连接是否可用(包括所有网络类型)
public boolean isNetworkAvailable(Activity activity)
{
Context context = activity.getApplicationContext();
ConnectivityManager cm = (ConnectivityManager)
context.getSystemService(Context.CONNECTIVITY_SERVICE);
if (cm == null)
return false;
else
{ // 获取所有NetworkInfo对象
NetworkInfo[] networkInfo = cm.getAllNetworkInfo();
if (networkInfo != null && networkInfo.length > 0)
{
for (int i = 0; i < networkInfo.length; i++)
if (networkInfo[i].getState() == NetworkInfo.State.CONNECTED)
return true; // 存在可用的网络连接
}
}
return false;
}
另外,本程序在 UI 界面开发上涉及到 Android 中的 ListView(显示)、PopupWindow(菜单)、ProgressDialog(加载)、AlertDialog(提示)等控件的使用。因为本文并不是讨论 Android 控件的使用,在这里就不赘述了。
源码下载:https://github.com/SongLee24/android-crawler
个人站点:http://songlee24.github.com