分布式作业系统 Elastic-Job-Cloud 源码分析 —— 本地运行模式
本文基于 Elastic-Job V2.1.5 版本分享
-
1. 概述
-
2. 配置
-
3. 运行
-
666. 彩蛋
1. 概述
本文主要分享 Elastic-Job-Cloud 本地运行模式,对应《官方文档 —— 本地运行模式》。
有什么用呢?引用官方解答:
在开发 Elastic-Job-Cloud 作业时,开发人员可以脱离 Mesos 环境,在本地运行和调试作业。可以利用本地运行模式充分的调试业务功能以及单元测试,完成之后再部署至 Mesos 集群。
本地运行作业无需安装 Mesos 环境。
本文涉及到主体类的类图如下( 打开大图 ):
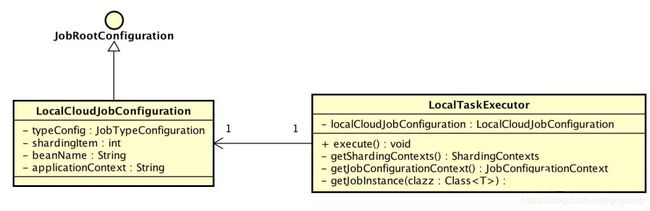
2. 配置
LocalCloudJobConfiguration,本地云作业配置,在《Elastic-Job-Cloud 源码分析 —— 作业配置》「3.2 本地云作业配置」有详细解析。
创建本地云作业配置示例代码如下(来自官方):
LocalCloudJobConfiguration config = new LocalCloudJobConfiguration(
new SimpleJobConfiguration(
// 配置作业类型和作业基本信息
JobCoreConfiguration.newBuilder("FooJob", "*/2 * * * * ?", 3)
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou")
.jobParameter("dbName=dangdang").build(), "com.dangdang.foo.FooJob"),
// 配置当前运行的作业是第几个分片
1,
// 配置Spring相关参数。如果不配置,代表不使用 Spring 配置。
"testSimpleJob" , "applicationContext.xml"); 3. 运行
LocalTaskExecutor,本地作业执行器。
创建本地作业执行器示例代码如下(来自官方):
new LocalTaskExecutor(localJobConfig).execute();可以看到,调用 LocalTaskExecutor#execute() 方法,执行作业逻辑,实现代码如下:
// LocalTaskExecutor.java
public void execute() {
AbstractElasticJobExecutor jobExecutor;
CloudJobFacade jobFacade = new CloudJobFacade(getShardingContexts(), getJobConfigurationContext(), new JobEventBus());
// 创建执行器
switch (localCloudJobConfiguration.getTypeConfig().getJobType()) {
case SIMPLE:
jobExecutor = new SimpleJobExecutor(getJobInstance(SimpleJob.class), jobFacade);
break;
case DATAFLOW:
jobExecutor = new DataflowJobExecutor(getJobInstance(DataflowJob.class), jobFacade);
break;
case SCRIPT:
jobExecutor = new ScriptJobExecutor(jobFacade);
break;
default:
throw new UnsupportedOperationException(localCloudJobConfiguration.getTypeConfig().getJobType().name());
}
// 执行作业
jobExecutor.execute();
}- 调用
#getShardingContexts()方法,创建分片上下文集合( ShardingContexts ),实现代码如下:
private ShardingContexts getShardingContexts() {
JobCoreConfiguration coreConfig = localCloudJobConfiguration.getTypeConfig().getCoreConfig();
Map shardingItemMap = new HashMap<>(1, 1);
shardingItemMap.put(localCloudJobConfiguration.getShardingItem(),
new ShardingItemParameters(coreConfig.getShardingItemParameters()).getMap().get(localCloudJobConfiguration.getShardingItem()));
return new ShardingContexts(
// taskId ?
Joiner.on("@-@").join(localCloudJobConfiguration.getJobName(), localCloudJobConfiguration.getShardingItem(), "READY", "foo_slave_id", "foo_uuid"),
localCloudJobConfiguration.getJobName(), coreConfig.getShardingTotalCount(), coreConfig.getJobParameter(), shardingItemMap);
} - 调用
#getJobConfigurationContext()方法,创建内部的作业配置上下文( JobConfigurationContext ),实现代码如下:
private JobConfigurationContext getJobConfigurationContext() {
Map jobConfigurationMap = new HashMap<>();
jobConfigurationMap.put("jobClass", localCloudJobConfiguration.getTypeConfig().getJobClass());
jobConfigurationMap.put("jobType", localCloudJobConfiguration.getTypeConfig().getJobType().name());
jobConfigurationMap.put("jobName", localCloudJobConfiguration.getJobName());
jobConfigurationMap.put("beanName", localCloudJobConfiguration.getBeanName());
jobConfigurationMap.put("applicationContext", localCloudJobConfiguration.getApplicationContext());
if (JobType.DATAFLOW == localCloudJobConfiguration.getTypeConfig().getJobType()) { // 数据流作业
jobConfigurationMap.put("streamingProcess", Boolean.toString(((DataflowJobConfiguration) localCloudJobConfiguration.getTypeConfig()).isStreamingProcess()));
} else if (JobType.SCRIPT == localCloudJobConfiguration.getTypeConfig().getJobType()) { // 脚本作业
jobConfigurationMap.put("scriptCommandLine", ((ScriptJobConfiguration) localCloudJobConfiguration.getTypeConfig()).getScriptCommandLine());
}
return new JobConfigurationContext(jobConfigurationMap);
} - 调用
#getJobInstance(...)方法, 获得分布式作业( ElasticJob )实现实例,实现代码如下:
private T getJobInstance(final Class clazz) {
Object result;
if (Strings.isNullOrEmpty(localCloudJobConfiguration.getApplicationContext())) { // 直接创建 ElasticJob
String jobClass = localCloudJobConfiguration.getTypeConfig().getJobClass();
try {
result = Class.forName(jobClass).newInstance();
} catch (final ReflectiveOperationException ex) {
throw new JobSystemException("Elastic-Job: Class '%s' initialize failure, the error message is '%s'.", jobClass, ex.getMessage());
}
} else { // Spring 环境获得 ElasticJob
result = new ClassPathXmlApplicationContext(localCloudJobConfiguration.getApplicationContext()).getBean(localCloudJobConfiguration.getBeanName());
}
return clazz.cast(result);
} - 调用
AbstractElasticJobExecutor#execute()方法,执行作业逻辑。 Elastic-Job-Lite 和 Elastic-Job-Cloud 作业执行基本一致,在《Elastic-Job-Lite 源码分析 —— 作业执行》有详细解析。
在此我向大家推荐一个架构学习交流群。交流学习群号:993070439 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系,还能领取免费的学习资源。