Python 数据分析三剑客之 Pandas(十):数据读写
CSDN 课程推荐:《迈向数据科学家:带你玩转Python数据分析》,讲师齐伟,苏州研途教育科技有限公司CTO,苏州大学应用统计专业硕士生指导委员会委员;已出版《跟老齐学Python:轻松入门》《跟老齐学Python:Django实战》、《跟老齐学Python:数据分析》和《Python大学实用教程》畅销图书。
Pandas 系列文章:
- Python 数据分析三剑客之 Pandas(一):认识 Pandas 及其 Series、DataFrame 对象
- Python 数据分析三剑客之 Pandas(二):Index 索引对象以及各种索引操作
- Python 数据分析三剑客之 Pandas(三):算术运算与缺失值的处理
- Python 数据分析三剑客之 Pandas(四):函数应用、映射、排序和层级索引
- Python 数据分析三剑客之 Pandas(五):统计计算与统计描述
- Python 数据分析三剑客之 Pandas(六):GroupBy 数据分裂、应用与合并
- Python 数据分析三剑客之 Pandas(七):合并数据集
- Python 数据分析三剑客之 Pandas(八):数据重塑、重复数据处理与数据替换
- Python 数据分析三剑客之 Pandas(九):时间序列
- Python 数据分析三剑客之 Pandas(十):数据读写
另有 NumPy、Matplotlib 系列文章已更新完毕,欢迎关注:
- NumPy 系列文章:https://itrhx.blog.csdn.net/category_9780393.html
- Matplotlib 系列文章:https://itrhx.blog.csdn.net/category_9780418.html
推荐学习资料与网站(博主参与部分文档翻译):
- NumPy 官方中文网:https://www.numpy.org.cn/
- Pandas 官方中文网:https://www.pypandas.cn/
- Matplotlib 官方中文网:https://www.matplotlib.org.cn/
- NumPy、Matplotlib、Pandas 速查表:https://github.com/TRHX/Python-quick-reference-table
文章目录
- 【01x00】读取数据
- 【01x01】简单示例
- 【01x02】header / names 定制列标签
- 【01x03】index_col 指定列为行索引
- 【01x04】sep 指定分隔符
- 【01x05】skiprows 忽略行
- 【01x06】na_values 设置缺失值
- 【01x07】nrows / chunksize 行与块
- 【02x00】写入数据
- 【02x01】简单示例
- 【02x02】sep 指定分隔符
- 【02x03】na_rep 替换缺失值
- 【02x04】index / header 行与列标签
- 【02x05】columns 指定列
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/106963135
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!
【01x00】读取数据
Pandas 提供了一些用于将表格型数据读取为 DataFrame 对象的函数。常见方法如下:
Pandas 官方对 IO 工具的介绍:https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
| 函数 | 描述 |
|---|---|
| read_csv | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为逗号 |
| read_table | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为制表符('\t') |
| read_fwf | 读取定宽列格式数据(没有分隔符) |
| read_clipboard | 读取剪贴板中的数据,可以看做 read_table 的剪贴板版本。在将网页转换为表格时很有用 |
| read_excel | 从 Excel XLS 或 XLSX file 读取表格数据 |
| read_hdf | 读取 pandas写的 HDF5 文件 |
| read_html | 读取 HTML 文档中的所有表格 |
| read_json | 读取 JSON( JavaScript Object Notation)字符串中的数据 |
| read_msgpack | 读取二进制格式编码的 pandas 数据(Pandas v1.0.0 中已删除对 msgpack 的支持,建议使用 pyarrow) |
| read_pickle | 读取 Python pickle 格式中存储的任意对象 |
| read_sas | 读取存储于 SAS 系统自定义存储格式的 SAS 数据集 |
| read_sql | (使用 SQLAlchemy)读取 SQL 查询结果为 pandas 的 DataFrame |
| read_stata | 读取 Stata 文件格式的数据集 |
| read_feather | 读取 Feather 二进制格式文件 |
以下以 read_csv 和 read_table 为例,它们的参数多达 50 多个,具体可参见官方文档:
read_csv:https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
read_table:https://pandas.pydata.org/docs/reference/api/pandas.read_table.html
常用参数:
| 参数 | 描述 |
|---|---|
| path | 表示文件系统位置、URL、文件型对象的字符串 |
| sep / delimiter | 用于对行中各字段进行拆分的字符序列或正则表达式 |
| header | 用作列名的行号,默认为 0(第一行),如果没有 header 行就应该设置为 None |
| index_col | 用作行索引的列编号或列名。可以是单个名称、数字或由多个名称、数字组成的列表(层次化索引) |
| names | 用于结果的列名列表,结合 header=None |
| skiprows | 需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始) |
| na_values | 指定一组值,将该组值设置为 NaN(缺失值) |
| comment | 用于将注释信息从行尾拆分出去的字符(一个或多个) |
| parse_dates | 尝试将数据解析为日期,默认为 False。如果为 True,则尝试解析所有列。此外,还可以指定需要解析的一组列号或列名。 如果列表的元素为列表或元组,就会将多个列组合到一起再进行日期解析工作(例如,日期、时间分别位于两个列中) |
| keep_date_col | 如果连接多列解析日期,则保持参与连接的列。默认为 False |
| converters | 由列号 / 列名跟函数之间的映射关系组成的字典。例如,{'foo': f} 会对 foo 列的所有值应用函数 f |
| dayfirst | 当解析有歧义的日期时,将其看做国际格式(例如,7/6/2012 —> June 7,2012),默认为 Fase |
| date_parser | 用于解析日期的函数 |
| nrows | 需要读取的行数(从文件开始处算起) |
| iterator | 返回一个 TextParser 以便逐块读取文件 |
| chunksize | 文件块的大小(用于迭代) |
| skip_footer | 需要忽略的行数(从文件末尾处算起) |
| verbose | 打印各种解析器输出信息,比如“非数值列中缺失值的数量”等 |
| encoding | 用于 unicode 的文本编码格式。例如,“utf-8” 表示用 UTF-8 编码的文本 |
| squeeze | 如果数据经解析后仅含一列,则返回 Series |
| thousands | 千分位分隔符,如 , 或 . |
【01x01】简单示例
首先创建一个 test1.csv 文件:
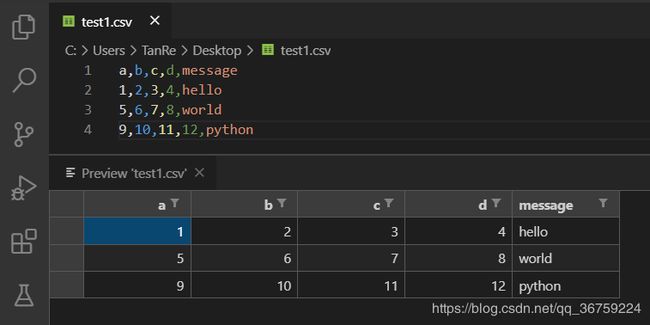
使用 read_csv 方法将其读出为一个 DataFrame 对象:
>>> import pandas as pd
>>> obj = pd.read_csv(r'C:\Users\TanRe\Desktop\test1.csv')
>>> obj
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 python
>>>
>>> type(obj)
<class 'pandas.core.frame.DataFrame'>
前面的 csv 文件是以逗号分隔的,可以使用 read_table 方法并指定分隔符来读取:
>>> import pandas as pd
>>> obj = pd.read_table(r'C:\Users\TanRe\Desktop\test1.csv', sep=',')
>>> obj
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 python
【01x02】header / names 定制列标签
以上示例中第一行为列标签,如果没有单独定义列标签,使用 read_csv 方法也会默认将第一行当作列标签:
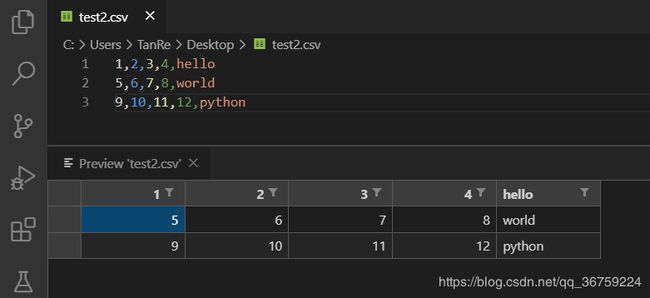
>>> import pandas as pd
>>> obj = pd.read_csv(r'C:\Users\TanRe\Desktop\test2.csv')
>>> obj
1 2 3 4 hello
0 5 6 7 8 world
1 9 10 11 12 python
避免以上情况,可以设置 header=None,Pandas 会为其自动分配列标签:
>>> import pandas as pd
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test2.csv', header=None)
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 python
也可以使用 names 参数自定义列标签,传递的是一个列表:
>>> import pandas as pd
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test2.csv', names=['a', 'b', 'c', 'd', 'message'])
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 python
【01x03】index_col 指定列为行索引
index_col 参数可以指定某一列作为 DataFrame 的行索引,传递的参数是列名称,在以下示例中,会将列名为 message 的列作为 DataFrame 的行索引:
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test2.csv',
names=['a', 'b', 'c', 'd', 'message'],
index_col='message')
a b c d
message
hello 1 2 3 4
world 5 6 7 8
python 9 10 11 12
如果需要构造多层索引的 DataFrame 对象,则只需传入由列编号或列名组成的列表即可:
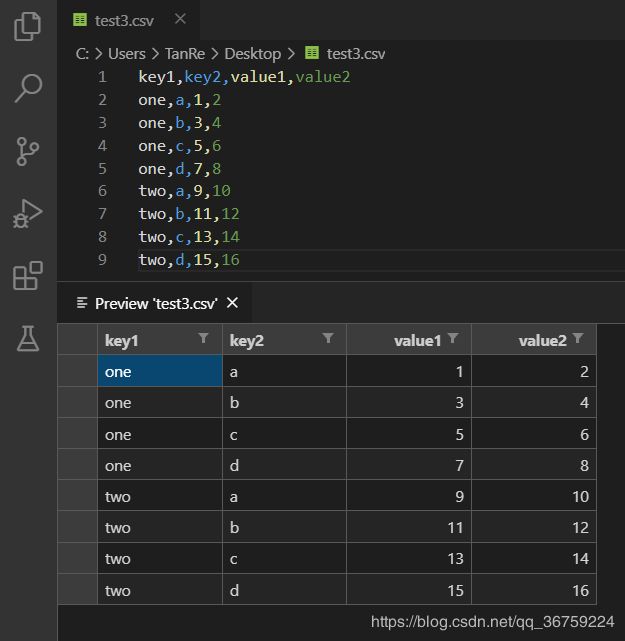
>>> import pandas as pd
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test3.csv', index_col=['key1', 'key2'])
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
two a 9 10
b 11 12
c 13 14
d 15 16
【01x04】sep 指定分隔符
在 read_table 中,sep 参数用于接收分隔符,如果遇到不是用固定的分隔符去分隔字段的,也可以传递一个正则表达式作为 read_table 的分隔符,如下面的 txt 文件数据之间是由不同的空白字符间隔开的:
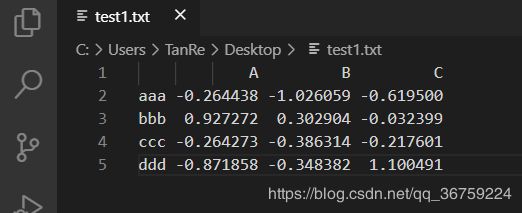
>>> import pandas as pd
>>> pd.read_table(r'C:\Users\TanRe\Desktop\test1.txt', sep='\s+')
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
【01x05】skiprows 忽略行
skiprows 参数可用于设置需要忽略的行数,或需要跳过的行号列表,在下面的示例中,读取文件时选择跳过第1、3、4行(索引值分别为0、2、3):

>>> import pandas as pd
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test4.csv', skiprows=[0, 2, 3])
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 python
【01x06】na_values 设置缺失值
当文件中出现了空字符串或者 NA 值,Pandas 会将其标记成 NaN(缺失值),同样也可以使用 isnull 方法来判断结果值是否为缺失值:
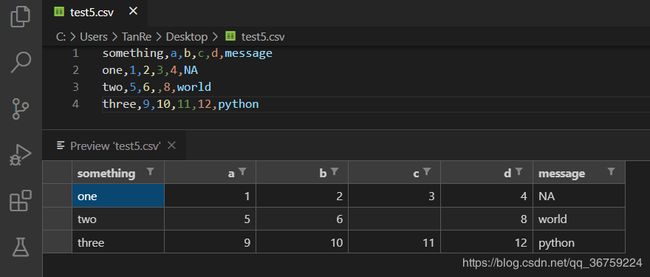
>>> import pandas as pd
>>> obj = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> obj
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> pd.isnull(obj)
something a b c d message
0 False False False False False True
1 False False False True False False
2 False False False False False False
na_values 方法可以传递一组值,将这组值设置为缺失值,如果传递的为字典对象,则字典的各值将被设置为 NaN:
>>> import pandas as pd
>>> obj1 = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> obj1
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> obj2 = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv', na_values=['1', '12'])
>>> obj2
something a b c d message
0 one NaN 2 3.0 4.0 NaN
1 two 5.0 6 NaN 8.0 world
2 three 9.0 10 11.0 NaN python
>>>
>>> sentinels = {'message': ['python', 'world'], 'something': ['two']}
>>> obj3 = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv', na_values=sentinels)
>>> obj3
something a b c d message
0 one 1 2 3.0 4 NaN
1 NaN 5 6 NaN 8 NaN
2 three 9 10 11.0 12 NaN
【01x07】nrows / chunksize 行与块
以下 test6.csv 文件中包含 50 行数据:

可以设置 pd.options.display.max_rows 来紧凑地显示指定行数的数据:
>>> import pandas as pd
>>> pd.options.display.max_rows = 10
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test6.csv')
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
.. ... ... ... ... ..
45 2.311896 -0.417070 -1.409599 -0.515821 L
46 -0.479893 -0.633419 0.745152 -0.646038 E
47 0.523331 0.787112 0.486066 1.093156 K
48 -0.362559 0.598894 -1.843201 0.887292 G
49 -0.096376 -1.012999 -0.657431 -0.573315 0
[50 rows x 5 columns]
通过 nrows 参数可以读取指定行数:
>>> import pandas as pd
>>> pd.read_csv(r'C:\Users\TanRe\Desktop\test6.csv', nrows=5)
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
要逐块读取文件,可以指定 chunksize(行数):
>>> import pandas as pd
>>> chunker = pd.read_csv(r'C:\Users\TanRe\Desktop\test6.csv', chunksize=50)
>>> chunker
<pandas.io.parsers.TextFileReader object at 0x07A20D60>
返回的 TextParser 对象,可以根据 chunksize 对文件进行逐块迭代。以下示例中,对 test6.csv 文件数据进行迭代处理,将值计数聚合到 “key” 列中:
>>> import pandas as pd
>>> chunker = pd.read_csv(r'C:\Users\TanRe\Desktop\test6.csv', chunksize=50)
>>> tot = pd.Series([], dtype='float64')
>>> for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
>>> tot = tot.sort_values(ascending=False)
>>> tot[:10]
G 6.0
E 5.0
B 5.0
L 5.0
0 5.0
K 4.0
A 4.0
R 4.0
C 2.0
Q 2.0
dtype: float64
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/106963135
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!
【02x00】写入数据
Pandas 提供了一些用于将表格型数据读取为 DataFrame 对象的函数。常见方法如下:
| 函数 | 描述 |
|---|---|
| to_csv | 将对象写入逗号分隔值(csv)文件 |
| to_clipboard | 将对象复制到系统剪贴板 |
| to_excel | 将对象写入 Excel 工作表 |
| to_hdf | 使用 HDFStore 将包含的数据写入 HDF5 文件 |
| to_html | 将 DataFrame 呈现为 HTML 表格 |
| to_json | 将对象转换为 JSON( JavaScript Object Notation)字符串 |
| to_msgpack | 将对象写入二进制格式编码的文件(Pandas v1.0.0 中已删除对 msgpack 的支持,建议使用 pyarrow) |
| to_pickle | Pickle(序列化)对象到文件 |
| to_sql | 将存储在 DataFrame 中的数据写入 SQL 数据库 |
| to_stata | 将 DataFrame 对象导出为 Stata 格式 |
| to_feather | 将 DataFrames 写入 Feather 二进制格式文件 |
以下以 to_csv 为例,它的参数同样多达 50 多个,具体可参见官方文档:
-
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_csv.html
-
https://pandas.pydata.org/docs/reference/api/pandas.Series.to_csv.html
【02x01】简单示例
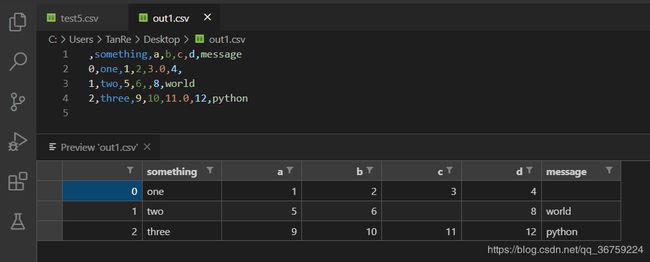
以之前的 test5.csv 文件为例,先读出数据,再将数据写入另外的文件:
>>> import pandas as pd
>>> data = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> data.to_csv(r'C:\Users\TanRe\Desktop\out1.csv')
【02x02】sep 指定分隔符
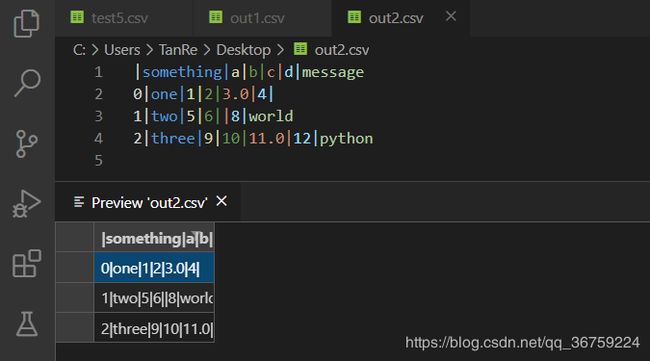
sep 参数可用于其他分隔符:
>>> import pandas as pd
>>> data = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> data.to_csv(r'C:\Users\TanRe\Desktop\out2.csv', sep='|')
【02x03】na_rep 替换缺失值
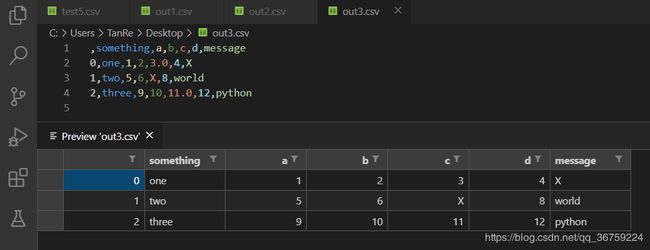
na_rep 参数可将缺失值(NaN)替换成其他字符串:
>>> import pandas as pd
>>> data = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> data.to_csv(r'C:\Users\TanRe\Desktop\out3.csv', na_rep='X')
【02x04】index / header 行与列标签
设置 index=False, header=False,可以禁用行标签与列标签:
>>> import pandas as pd
>>> data = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> data.to_csv(r'C:\Users\TanRe\Desktop\out4.csv', index=False, header=False)
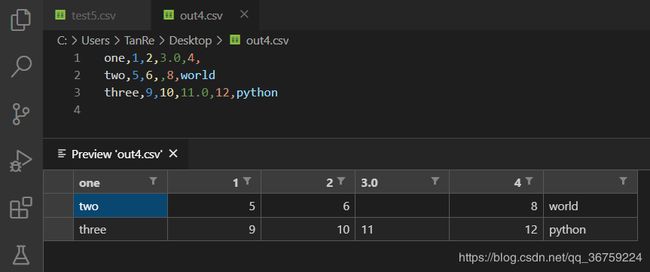
还可以传入列表来重新设置列标签:
>>> import pandas as pd
>>> data = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> data.to_csv(r'C:\Users\TanRe\Desktop\out5.csv', header=['a', 'b', 'c', 'd', 'e', 'f'])
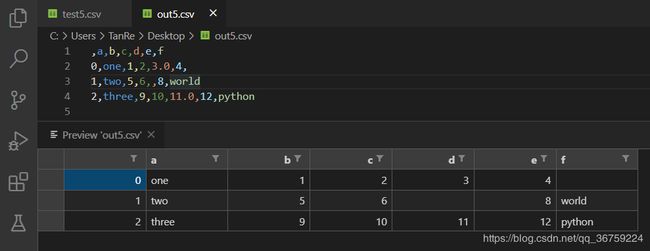
【02x05】columns 指定列
可以通过设置 columns 参数,只写入部分列,并按照指定顺序排序:
>>> import pandas as pd
>>> data = pd.read_csv(r'C:\Users\TanRe\Desktop\test5.csv')
>>> data
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 python
>>>
>>> data.to_csv(r'C:\Users\TanRe\Desktop\out6.csv', columns=['c', 'b', 'a'])
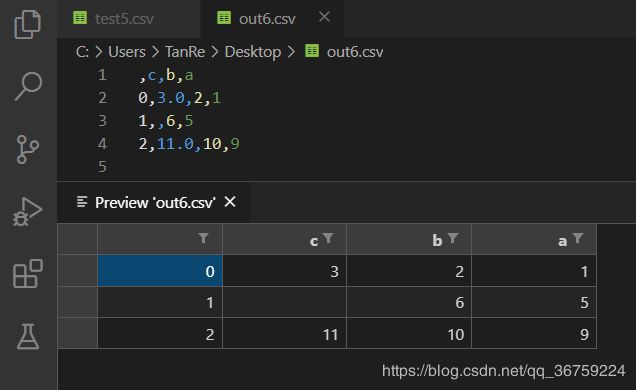
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/106963135
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!