COVID-19 肺炎疫情数据实时监控(python 爬虫 + pyecharts 数据可视化 + wordcloud 词云图)
文章目录
- 【1x00】前言
- 【2x00】思维导图
- 【3x00】数据结构分析
- 【4x00】主函数 main()
- 【5x00】数据获取模块 data_get
- 【5x01】初始化函数 init()
- 【5x02】中国总数据 china_total_data()
- 【5x03】全球总数据 global_total_data()
- 【5x04】中国每日数据 china_daily_data()
- 【5x05】境外每日数据 foreign_daily_data()
- 【6x00】词云图绘制模块 data_wordcloud
- 【6x01】中国累计确诊词云图 foreign_daily_data()
- 【6x02】全球累计确诊词云图 foreign_daily_data()
- 【7x00】地图绘制模块 data_map
- 【7x01】中国累计确诊地图 china_total_map()
- 【7x02】全球累计确诊地图 global_total_map()
- 【7x03】中国每日数据折线图 china_daily_map()
- 【7x04】境外每日数据折线图 foreign_daily_map()
- 【8x00】结果截图
- 【8x01】数据储存 Excel
- 【8x02】词云图
- 【8x03】地图 + 折线图
- 【9x00】完整代码
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/107140534
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!
【1x00】前言
本来两三个月之前就想搞个疫情数据实时数据展示的,由于各种不可抗拒因素一而再再而三的鸽了,最近终于抽空写了一个,数据是用 Python 爬取的百度疫情实时大数据报告,请求库用的 requests,解析用的 Xpath 语法,词云用的 wordcloud 库,数据可视化用 pyecharts 绘制的地图和折线图,数据储存在 Excel 表格里面,使用 openpyxl 对表格进行处理。
本程序实现了累计确诊地图展示和每日数据变化折线图展示,其他更多数据的获取和展示均可在程序中进行拓展,可以将程序部署在服务器上,设置定时运行,即可实时展示数据,pyecharts 绘图模块也可以整合到 Web 框架(Django、Flask等)中使用。
在获取数据时有全球和境外两个概念,全球包含中国,境外不包含中国,后期绘制的四个图:中国累计确诊地图、全球累计确诊地图(包含中国)、中国每日数据折线图、境外每日数据折线图(不包含中国)。
注意项:直接向该网页发送请求获取的响应中,没有每个国家的每日数据,该数据获取的地址是:https://voice.baidu.com/newpneumonia/get?target=trend&isCaseIn=1&stage=publish
-
预览地址:http://cov.itrhx.com/
-
数据来源:https://voice.baidu.com/act/newpneumonia/newpneumonia/
-
pyecharts 文档:https://pyecharts.org/
-
openpyxl 文档:https://openpyxl.readthedocs.io/
-
wordcloud 文档:http://amueller.github.io/word_cloud/
【2x00】思维导图
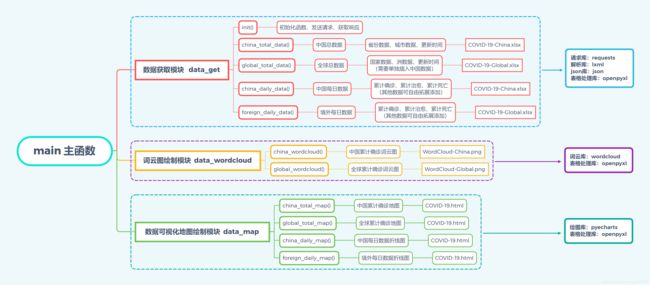
【3x00】数据结构分析
通过查看百度的疫情数据页面,可以看到很多整齐的数据,猜测就是疫情相关的数据,保存该页面,对其进行格式化,很容易可以分析出所有的数据都在 里面,其中 title 里面是一些 Unicode 编码,将其转为中文后更容易得到不同的分类数据。
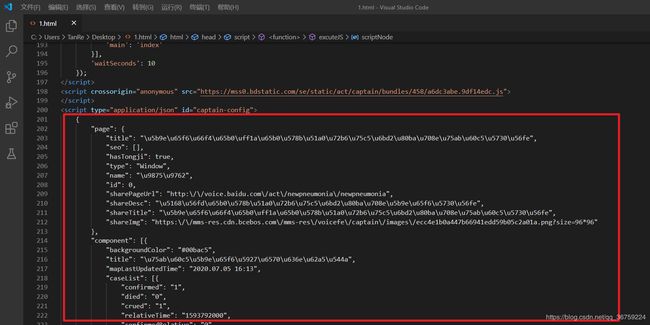
由于数据繁多,可以将数据主体部分提取出来,删除一些重复项和其他杂项,留下数据大体位置并分析数据结构,便于后期的数据提取,经过处理后的数据大致结构如下:
<script type="application/json" id="captain-config">
{
"component": [
{
"mapLastUpdatedTime": "2020.07.05 16:13", // 国内疫情数据最后更新时间
"caseList": [ // caseList 列表,每一个元素是一个字典
{
"confirmed": "1", // 每个字典包含中国每个省的每一项疫情数据
"died": "0",
"crued": "1",
"relativeTime": "1593792000",
"confirmedRelative": "0",
"diedRelative": "0",
"curedRelative": "0",
"curConfirm": "0",
"curConfirmRelative": "0",
"icuDisable": "1",
"area": "西藏",
"subList": [ // subList 列表,每一个元素是一个字典
{
"city": "拉萨", // 每个字典包含该省份对应的每个城市疫情数据
"confirmed": "1",
"died": "0",
"crued": "1",
"confirmedRelative": "0",
"curConfirm": "0",
"cityCode": "100"
}
]
}
],
"caseOutsideList": [ // caseOutsideList 列表,每一个元素是一个字典
{
"confirmed": "241419", // 每个字典包含各国的每一项疫情数据
"died": "34854",
"crued": "191944",
"relativeTime": "1593792000",
"confirmedRelative": "223",
"curConfirm": "14621",
"icuDisable": "1",
"area": "意大利",
"subList": [ // subList 列表,每一个元素是一个字典
{
"city": "伦巴第", // 每个字典包含每个国家对应的每个城市疫情数据
"confirmed": "94318",
"died": "16691",
"crued": "68201",
"curConfirm": "9426"
}
]
}
],
"summaryDataIn": { // summaryDataIn 国内总的疫情数据
"confirmed": "85307",
"died": "4648",
"cured": "80144",
"asymptomatic": "99",
"asymptomaticRelative": "7",
"unconfirmed": "7",
"relativeTime": "1593792000",
"confirmedRelative": "19",
"unconfirmedRelative": "1",
"curedRelative": "27",
"diedRelative": "0",
"icu": "6",
"icuRelative": "0",
"overseasInput": "1931",
"unOverseasInputCumulative": "83375",
"overseasInputRelative": "6",
"unOverseasInputNewAdd": "13",
"curConfirm": "515",
"curConfirmRelative": "-8",
"icuDisable": "1"
},
"summaryDataOut": { // summaryDataOut 国外总的疫情数据
"confirmed": "11302569",
"died": "528977",
"curConfirm": "4410601",
"cured": "6362991",
"confirmedRelative": "206165",
"curedRelative": "190018",
"diedRelative": "4876",
"curConfirmRelative": "11271",
"relativeTime": "1593792000"
},
"trend": { // trend 字典,包含国内每日的疫情数据
"updateDate": [], // 日期
"list": [ // list 列表,每项数据及其对应的值
{
"name": "确诊",
"data": []
},
{
"name": "疑似",
"data": []
},
{
"name": "治愈",
"data": []
},
{
"name": "死亡",
"data": []
},
{
"name": "新增确诊",
"data": []
},
{
"name": "新增疑似",
"data": []
},
{
"name": "新增治愈",
"data": []
},
{
"name": "新增死亡",
"data": []
},
{
"name": "累计境外输入",
"data": []
},
{
"name": "新增境外输入",
"data": []
}
]
},
"foreignLastUpdatedTime": "2020.07.05 16:13", // 国外疫情数据最后更新时间
"globalList": [ // globalList 列表,每一个元素是一个字典
{
"area": "亚洲", // 按照不同洲进行分类
"subList": [ // subList 列表,每个洲各个国家的疫情数据
{
"died": "52",
"confirmed": "6159",
"crued": "4809",
"curConfirm": "1298",
"confirmedRelative": "0",
"relativeTime": "1593792000",
"country": "塔吉克斯坦"
}
],
"died": "56556", // 每个洲总的疫情数据
"crued": "1625562",
"confirmed": "2447873",
"curConfirm": "765755",
"confirmedRelative": "60574"
},
{
"area": "其他", // 其他特殊区域疫情数据
"subList": [
{
"died": "13",
"confirmed": "712",
"crued": "651",
"curConfirm": "48",
"confirmedRelative": "0",
"relativeTime": "1593792000",
"country": "钻石公主号邮轮"
}
],
"died": "13", // 其他特殊区域疫情总的数据
"crued": "651",
"confirmed": "712",
"curConfirm": "48",
"confirmedRelative": "0"
},
{
"area": "热门", // 热门国家疫情数据
"subList": [
{
"died": "5206",
"confirmed": "204610",
"crued": "179492",
"curConfirm": "19912",
"confirmedRelative": "1172",
"relativeTime": "1593792000",
"country": "土耳其"
}
],
"died": "528967", // 热门国家疫情总的数据
"crued": "6362924",
"confirmed": "11302357",
"confirmedRelative": "216478",
"curConfirm": "4410466"
}],
"allForeignTrend": { // allForeignTrend 字典,包含国外每日的疫情数据
"updateDate": [], // 日期
"list": [ // list 列表,每项数据及其对应的值
{
"name": "累计确诊",
"data": []
},
{
"name": "治愈",
"data": []
},
{
"name": "死亡",
"data": []
},
{
"name": "现有确诊",
"data": []
},
{
"name": "新增确诊",
"data": []
}
]
},
"topAddCountry": [ // 确诊增量最高的国家
{
"name": "美国",
"value": 53162
}
],
"topOverseasInput": [ // 境外输入最多的省份
{
"name": "黑龙江",
"value": 386
}
]
}
]
}
</script>
【4x00】主函数 main()
分别将数据获取、词云图绘制、地图绘制写入三个文件:data_get()、data_wordcloud()、data_map(),然后使用一个主函数文件 main.py 来调用这三个文件里面的函数。
import data_get
import data_wordcloud
import data_map
data_dict = data_get.init()
data_get.china_total_data(data_dict)
data_get.global_total_data(data_dict)
data_get.china_daily_data(data_dict)
data_get.foreign_daily_data(data_dict)
data_wordcloud.china_wordcloud()
data_wordcloud.global_wordcloud()
data_map.all_map()
【5x00】数据获取模块 data_get
【5x01】初始化函数 init()
使用 xpath 语法 //script[@id="captain-config"]/text() 提取里面的值,利用 json.loads 方法将其转换为字典对象,以便后续的其他函数调用。
def init():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.13 Safari/537.36'
}
url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/'
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
dict1 = tree.xpath('//script[@id="captain-config"]/text()')
print(type(dict1[0]))
dict2 = json.loads(dict1[0])
return dict2
【5x02】中国总数据 china_total_data()
def china_total_data(data):
"""
1、中国省/直辖市/自治区/行政区疫情数据
省/直辖市/自治区/行政区:area
现有确诊: curConfirm
累计确诊: confirmed
累计治愈: crued
累计死亡: died
现有确诊增量: curConfirmRelative
累计确诊增量: confirmedRelative
累计治愈增量: curedRelative
累计死亡增量: diedRelative
"""
wb = openpyxl.Workbook() # 创建工作簿
ws_china = wb.active # 获取工作表
ws_china.title = "中国省份疫情数据" # 命名工作表
ws_china.append(['省/直辖市/自治区/行政区', '现有确诊', '累计确诊', '累计治愈',
'累计死亡', '现有确诊增量', '累计确诊增量',
'累计治愈增量', '累计死亡增量'])
china = data['component'][0]['caseList']
for province in china:
ws_china.append([province['area'],
province['curConfirm'],
province['confirmed'],
province['crued'],
province['died'],
province['curConfirmRelative'],
province['confirmedRelative'],
province['curedRelative'],
province['diedRelative']])
"""
2、中国城市疫情数据
城市:city
现有确诊:curConfirm
累计确诊:confirmed
累计治愈:crued
累计死亡:died
累计确诊增量:confirmedRelative
"""
ws_city = wb.create_sheet('中国城市疫情数据')
ws_city.append(['城市', '现有确诊', '累计确诊',
'累计治愈', '累计死亡', '累计确诊增量'])
for province in china:
for city in province['subList']:
# 某些城市没有 curConfirm 数据,则将其设置为 0,crued 和 died 为空时,替换成 0
if 'curConfirm' not in city:
city['curConfirm'] = '0'
if city['crued'] == '':
city['crued'] = '0'
if city['died'] == '':
city['died'] = '0'
ws_city.append([city['city'], '0', city['confirmed'],
city['crued'], city['died'], city['confirmedRelative']])
"""
3、中国疫情数据更新时间:mapLastUpdatedTime
"""
time_domestic = data['component'][0]['mapLastUpdatedTime']
ws_time = wb.create_sheet('中国疫情数据更新时间')
ws_time.column_dimensions['A'].width = 22 # 调整列宽
ws_time.append(['中国疫情数据更新时间'])
ws_time.append([time_domestic])
wb.save('COVID-19-China.xlsx')
print('中国疫情数据已保存至 COVID-19-China.xlsx!')
【5x03】全球总数据 global_total_data()
全球总数据在提取完成后,进行地图绘制时发现并没有中国的数据,因此在写入全球数据时注意要单独将中国的数据插入 Excel 中。
def global_total_data(data):
"""
1、全球各国疫情数据
国家:country
现有确诊:curConfirm
累计确诊:confirmed
累计治愈:crued
累计死亡:died
累计确诊增量:confirmedRelative
"""
wb = openpyxl.Workbook()
ws_global = wb.active
ws_global.title = "全球各国疫情数据"
# 按照国家保存数据
countries = data['component'][0]['caseOutsideList']
ws_global.append(['国家', '现有确诊', '累计确诊', '累计治愈', '累计死亡', '累计确诊增量'])
for country in countries:
ws_global.append([country['area'],
country['curConfirm'],
country['confirmed'],
country['crued'],
country['died'],
country['confirmedRelative']])
# 按照洲保存数据
continent = data['component'][0]['globalList']
for area in continent:
ws_foreign = wb.create_sheet(area['area'] + '疫情数据')
ws_foreign.append(['国家', '现有确诊', '累计确诊', '累计治愈', '累计死亡', '累计确诊增量'])
for country in area['subList']:
ws_foreign.append([country['country'],
country['curConfirm'],
country['confirmed'],
country['crued'],
country['died'],
country['confirmedRelative']])
# 在“全球各国疫情数据”和“亚洲疫情数据”两张表中写入中国疫情数据
ws1, ws2 = wb['全球各国疫情数据'], wb['亚洲疫情数据']
original_data = data['component'][0]['summaryDataIn']
add_china_data = ['中国',
original_data['curConfirm'],
original_data['confirmed'],
original_data['cured'],
original_data['died'],
original_data['confirmedRelative']]
ws1.append(add_china_data)
ws2.append(add_china_data)
"""
2、全球疫情数据更新时间:foreignLastUpdatedTime
"""
time_foreign = data['component'][0]['foreignLastUpdatedTime']
ws_time = wb.create_sheet('全球疫情数据更新时间')
ws_time.column_dimensions['A'].width = 22 # 调整列宽
ws_time.append(['全球疫情数据更新时间'])
ws_time.append([time_foreign])
wb.save('COVID-19-Global.xlsx')
print('全球疫情数据已保存至 COVID-19-Global.xlsx!')
【5x04】中国每日数据 china_daily_data()
def china_daily_data(data):
"""
i_dict = data['component'][0]['trend']
i_dict['updateDate']:日期
i_dict['list'][0]:确诊
i_dict['list'][1]:疑似
i_dict['list'][2]:治愈
i_dict['list'][3]:死亡
i_dict['list'][4]:新增确诊
i_dict['list'][5]:新增疑似
i_dict['list'][6]:新增治愈
i_dict['list'][7]:新增死亡
i_dict['list'][8]:累计境外输入
i_dict['list'][9]:新增境外输入
"""
ccd_dict = data['component'][0]['trend']
update_date = ccd_dict['updateDate'] # 日期
china_confirmed = ccd_dict['list'][0]['data'] # 每日累计确诊数据
china_crued = ccd_dict['list'][2]['data'] # 每日累计治愈数据
china_died = ccd_dict['list'][3]['data'] # 每日累计死亡数据
wb = openpyxl.load_workbook('COVID-19-China.xlsx')
# 写入每日累计确诊数据
ws_china_confirmed = wb.create_sheet('中国每日累计确诊数据')
ws_china_confirmed.append(['日期', '数据'])
for data in zip(update_date, china_confirmed):
ws_china_confirmed.append(data)
# 写入每日累计治愈数据
ws_china_crued = wb.create_sheet('中国每日累计治愈数据')
ws_china_crued.append(['日期', '数据'])
for data in zip(update_date, china_crued):
ws_china_crued.append(data)
# 写入每日累计死亡数据
ws_china_died = wb.create_sheet('中国每日累计死亡数据')
ws_china_died.append(['日期', '数据'])
for data in zip(update_date, china_died):
ws_china_died.append(data)
wb.save('COVID-19-China.xlsx')
print('中国每日累计确诊/治愈/死亡数据已保存至 COVID-19-China.xlsx!')
【5x05】境外每日数据 foreign_daily_data()
def foreign_daily_data(data):
"""
te_dict = data['component'][0]['allForeignTrend']
te_dict['updateDate']:日期
te_dict['list'][0]:累计确诊
te_dict['list'][1]:治愈
te_dict['list'][2]:死亡
te_dict['list'][3]:现有确诊
te_dict['list'][4]:新增确诊
"""
te_dict = data['component'][0]['allForeignTrend']
update_date = te_dict['updateDate'] # 日期
foreign_confirmed = te_dict['list'][0]['data'] # 每日累计确诊数据
foreign_crued = te_dict['list'][1]['data'] # 每日累计治愈数据
foreign_died = te_dict['list'][2]['data'] # 每日累计死亡数据
wb = openpyxl.load_workbook('COVID-19-Global.xlsx')
# 写入每日累计确诊数据
ws_foreign_confirmed = wb.create_sheet('境外每日累计确诊数据')
ws_foreign_confirmed.append(['日期', '数据'])
for data in zip(update_date, foreign_confirmed):
ws_foreign_confirmed.append(data)
# 写入累计治愈数据
ws_foreign_crued = wb.create_sheet('境外每日累计治愈数据')
ws_foreign_crued.append(['日期', '数据'])
for data in zip(update_date, foreign_crued):
ws_foreign_crued.append(data)
# 写入累计死亡数据
ws_foreign_died = wb.create_sheet('境外每日累计死亡数据')
ws_foreign_died.append(['日期', '数据'])
for data in zip(update_date, foreign_died):
ws_foreign_died.append(data)
wb.save('COVID-19-Global.xlsx')
print('境外每日累计确诊/治愈/死亡数据已保存至 COVID-19-Global.xlsx!')
【6x00】词云图绘制模块 data_wordcloud
【6x01】中国累计确诊词云图 foreign_daily_data()
def china_wordcloud():
wb = openpyxl.load_workbook('COVID-19-China.xlsx') # 获取已有的xlsx文件
ws_china = wb['中国省份疫情数据'] # 获取中国省份疫情数据表
ws_china.delete_rows(1) # 删除第一行
china_dict = {} # 将省份及其累计确诊按照键值对形式储存在字典中
for data in ws_china.values:
china_dict[data[0]] = int(data[2])
word_cloud = wordcloud.WordCloud(font_path='C:/Windows/Fonts/simsun.ttc',
background_color='#CDC9C9',
min_font_size=15,
width=900, height=500)
word_cloud.generate_from_frequencies(china_dict)
word_cloud.to_file('WordCloud-China.png')
print('中国省份疫情词云图绘制完毕!')
【6x02】全球累计确诊词云图 foreign_daily_data()
def global_wordcloud():
wb = openpyxl.load_workbook('COVID-19-Global.xlsx')
ws_global = wb['全球各国疫情数据']
ws_global.delete_rows(1)
global_dict = {}
for data in ws_global.values:
global_dict[data[0]] = int(data[2])
word_cloud = wordcloud.WordCloud(font_path='C:/Windows/Fonts/simsun.ttc',
background_color='#CDC9C9',
width=900, height=500)
word_cloud.generate_from_frequencies(global_dict)
word_cloud.to_file('WordCloud-Global.png')
print('全球各国疫情词云图绘制完毕!')
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/107140534
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!
【7x00】地图绘制模块 data_map
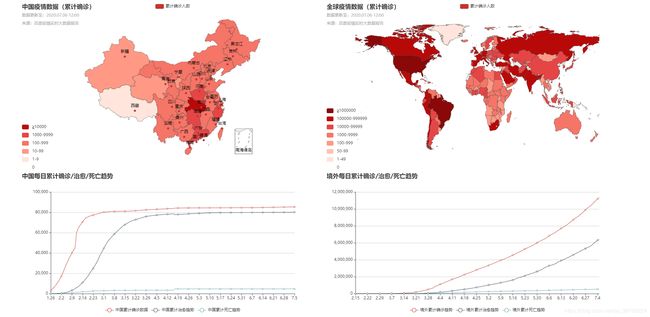
【7x01】中国累计确诊地图 china_total_map()
def china_total_map():
wb = openpyxl.load_workbook('COVID-19-China.xlsx') # 获取已有的xlsx文件
ws_time = wb['中国疫情数据更新时间'] # 获取文件中中国疫情数据更新时间表
ws_data = wb['中国省份疫情数据'] # 获取文件中中国省份疫情数据表
ws_data.delete_rows(1) # 删除第一行
province = [] # 省份
curconfirm = [] # 累计确诊
for data in ws_data.values:
province.append(data[0])
curconfirm.append(data[2])
time_china = ws_time['A2'].value # 更新时间
# 设置分级颜色
pieces = [
{'max': 0, 'min': 0, 'label': '0', 'color': '#FFFFFF'},
{'max': 9, 'min': 1, 'label': '1-9', 'color': '#FFE5DB'},
{'max': 99, 'min': 10, 'label': '10-99', 'color': '#FF9985'},
{'max': 999, 'min': 100, 'label': '100-999', 'color': '#F57567'},
{'max': 9999, 'min': 1000, 'label': '1000-9999', 'color': '#E64546'},
{'max': 99999, 'min': 10000, 'label': '≧10000', 'color': '#B80909'}
]
# 绘制地图
ct_map = (
Map()
.add(series_name='累计确诊人数', data_pair=[list(z) for z in zip(province, curconfirm)], maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情数据(累计确诊)",
subtitle='数据更新至:' + time_china + '\n\n来源:百度疫情实时大数据报告'),
visualmap_opts=opts.VisualMapOpts(max_=300, is_piecewise=True, pieces=pieces)
)
)
return ct_map
【7x02】全球累计确诊地图 global_total_map()
def global_total_map():
wb = openpyxl.load_workbook('COVID-19-Global.xlsx')
ws_time = wb['全球疫情数据更新时间']
ws_data = wb['全球各国疫情数据']
ws_data.delete_rows(1)
country = [] # 国家
curconfirm = [] # 累计确诊
for data in ws_data.values:
country.append(data[0])
curconfirm.append(data[2])
time_global = ws_time['A2'].value # 更新时间
# 国家名称中英文映射表
name_map = {
"Somalia": "索马里",
"Liechtenstein": "列支敦士登",
"Morocco": "摩洛哥",
"W. Sahara": "西撒哈拉",
"Serbia": "塞尔维亚",
"Afghanistan": "阿富汗",
"Angola": "安哥拉",
"Albania": "阿尔巴尼亚",
"Andorra": "安道尔共和国",
"United Arab Emirates": "阿拉伯联合酋长国",
"Argentina": "阿根廷",
"Armenia": "亚美尼亚",
"Australia": "澳大利亚",
"Austria": "奥地利",
"Azerbaijan": "阿塞拜疆",
"Burundi": "布隆迪",
"Belgium": "比利时",
"Benin": "贝宁",
"Burkina Faso": "布基纳法索",
"Bangladesh": "孟加拉国",
"Bulgaria": "保加利亚",
"Bahrain": "巴林",
"Bahamas": "巴哈马",
"Bosnia and Herz.": "波斯尼亚和黑塞哥维那",
"Belarus": "白俄罗斯",
"Belize": "伯利兹",
"Bermuda": "百慕大",
"Bolivia": "玻利维亚",
"Brazil": "巴西",
"Barbados": "巴巴多斯",
"Brunei": "文莱",
"Bhutan": "不丹",
"Botswana": "博茨瓦纳",
"Central African Rep.": "中非共和国",
"Canada": "加拿大",
"Switzerland": "瑞士",
"Chile": "智利",
"China": "中国",
"Côte d'Ivoire": "科特迪瓦",
"Cameroon": "喀麦隆",
"Dem. Rep. Congo": "刚果(布)",
"Congo": "刚果(金)",
"Colombia": "哥伦比亚",
"Cape Verde": "佛得角",
"Costa Rica": "哥斯达黎加",
"Cuba": "古巴",
"N. Cyprus": "北塞浦路斯",
"Cyprus": "塞浦路斯",
"Czech Rep.": "捷克",
"Germany": "德国",
"Djibouti": "吉布提",
"Denmark": "丹麦",
"Dominican Rep.": "多米尼加",
"Algeria": "阿尔及利亚",
"Ecuador": "厄瓜多尔",
"Egypt": "埃及",
"Eritrea": "厄立特里亚",
"Spain": "西班牙",
"Estonia": "爱沙尼亚",
"Ethiopia": "埃塞俄比亚",
"Finland": "芬兰",
"Fiji": "斐济",
"France": "法国",
"Gabon": "加蓬",
"United Kingdom": "英国",
"Georgia": "格鲁吉亚",
"Ghana": "加纳",
"Guinea": "几内亚",
"Gambia": "冈比亚",
"Guinea-Bissau": "几内亚比绍",
"Eq. Guinea": "赤道几内亚",
"Greece": "希腊",
"Grenada": "格林纳达",
"Greenland": "格陵兰岛",
"Guatemala": "危地马拉",
"Guam": "关岛",
"Guyana": "圭亚那合作共和国",
"Honduras": "洪都拉斯",
"Croatia": "克罗地亚",
"Haiti": "海地",
"Hungary": "匈牙利",
"Indonesia": "印度尼西亚",
"India": "印度",
"Br. Indian Ocean Ter.": "英属印度洋领土",
"Ireland": "爱尔兰",
"Iran": "伊朗",
"Iraq": "伊拉克",
"Iceland": "冰岛",
"Israel": "以色列",
"Italy": "意大利",
"Jamaica": "牙买加",
"Jordan": "约旦",
"Japan": "日本",
"Siachen Glacier": "锡亚琴冰川",
"Kazakhstan": "哈萨克斯坦",
"Kenya": "肯尼亚",
"Kyrgyzstan": "吉尔吉斯斯坦",
"Cambodia": "柬埔寨",
"Korea": "韩国",
"Kuwait": "科威特",
"Lao PDR": "老挝",
"Lebanon": "黎巴嫩",
"Liberia": "利比里亚",
"Libya": "利比亚",
"Sri Lanka": "斯里兰卡",
"Lesotho": "莱索托",
"Lithuania": "立陶宛",
"Luxembourg": "卢森堡",
"Latvia": "拉脱维亚",
"Moldova": "摩尔多瓦",
"Madagascar": "马达加斯加",
"Mexico": "墨西哥",
"Macedonia": "马其顿",
"Mali": "马里",
"Malta": "马耳他",
"Myanmar": "缅甸",
"Montenegro": "黑山",
"Mongolia": "蒙古国",
"Mozambique": "莫桑比克",
"Mauritania": "毛里塔尼亚",
"Mauritius": "毛里求斯",
"Malawi": "马拉维",
"Malaysia": "马来西亚",
"Namibia": "纳米比亚",
"New Caledonia": "新喀里多尼亚",
"Niger": "尼日尔",
"Nigeria": "尼日利亚",
"Nicaragua": "尼加拉瓜",
"Netherlands": "荷兰",
"Norway": "挪威",
"Nepal": "尼泊尔",
"New Zealand": "新西兰",
"Oman": "阿曼",
"Pakistan": "巴基斯坦",
"Panama": "巴拿马",
"Peru": "秘鲁",
"Philippines": "菲律宾",
"Papua New Guinea": "巴布亚新几内亚",
"Poland": "波兰",
"Puerto Rico": "波多黎各",
"Dem. Rep. Korea": "朝鲜",
"Portugal": "葡萄牙",
"Paraguay": "巴拉圭",
"Palestine": "巴勒斯坦",
"Qatar": "卡塔尔",
"Romania": "罗马尼亚",
"Russia": "俄罗斯",
"Rwanda": "卢旺达",
"Saudi Arabia": "沙特阿拉伯",
"Sudan": "苏丹",
"S. Sudan": "南苏丹",
"Senegal": "塞内加尔",
"Singapore": "新加坡",
"Solomon Is.": "所罗门群岛",
"Sierra Leone": "塞拉利昂",
"El Salvador": "萨尔瓦多",
"Suriname": "苏里南",
"Slovakia": "斯洛伐克",
"Slovenia": "斯洛文尼亚",
"Sweden": "瑞典",
"Swaziland": "斯威士兰",
"Seychelles": "塞舌尔",
"Syria": "叙利亚",
"Chad": "乍得",
"Togo": "多哥",
"Thailand": "泰国",
"Tajikistan": "塔吉克斯坦",
"Turkmenistan": "土库曼斯坦",
"Timor-Leste": "东帝汶",
"Tonga": "汤加",
"Trinidad and Tobago": "特立尼达和多巴哥",
"Tunisia": "突尼斯",
"Turkey": "土耳其",
"Tanzania": "坦桑尼亚",
"Uganda": "乌干达",
"Ukraine": "乌克兰",
"Uruguay": "乌拉圭",
"United States": "美国",
"Uzbekistan": "乌兹别克斯坦",
"Venezuela": "委内瑞拉",
"Vietnam": "越南",
"Vanuatu": "瓦努阿图",
"Yemen": "也门",
"South Africa": "南非",
"Zambia": "赞比亚",
"Zimbabwe": "津巴布韦",
"Aland": "奥兰群岛",
"American Samoa": "美属萨摩亚",
"Fr. S. Antarctic Lands": "南极洲",
"Antigua and Barb.": "安提瓜和巴布达",
"Comoros": "科摩罗",
"Curaçao": "库拉索岛",
"Cayman Is.": "开曼群岛",
"Dominica": "多米尼加",
"Falkland Is.": "福克兰群岛马尔维纳斯",
"Faeroe Is.": "法罗群岛",
"Micronesia": "密克罗尼西亚",
"Heard I. and McDonald Is.": "赫德岛和麦克唐纳群岛",
"Isle of Man": "曼岛",
"Jersey": "泽西岛",
"Kiribati": "基里巴斯",
"Saint Lucia": "圣卢西亚",
"N. Mariana Is.": "北马里亚纳群岛",
"Montserrat": "蒙特塞拉特",
"Niue": "纽埃",
"Palau": "帕劳",
"Fr. Polynesia": "法属波利尼西亚",
"S. Geo. and S. Sandw. Is.": "南乔治亚岛和南桑威奇群岛",
"Saint Helena": "圣赫勒拿",
"St. Pierre and Miquelon": "圣皮埃尔和密克隆群岛",
"São Tomé and Principe": "圣多美和普林西比",
"Turks and Caicos Is.": "特克斯和凯科斯群岛",
"St. Vin. and Gren.": "圣文森特和格林纳丁斯",
"U.S. Virgin Is.": "美属维尔京群岛",
"Samoa": "萨摩亚"
}
pieces = [
{'max': 0, 'min': 0, 'label': '0', 'color': '#FFFFFF'},
{'max': 49, 'min': 1, 'label': '1-49', 'color': '#FFE5DB'},
{'max': 99, 'min': 50, 'label': '50-99', 'color': '#FFC4B3'},
{'max': 999, 'min': 100, 'label': '100-999', 'color': '#FF9985'},
{'max': 9999, 'min': 1000, 'label': '1000-9999', 'color': '#F57567'},
{'max': 99999, 'min': 10000, 'label': '10000-99999', 'color': '#E64546'},
{'max': 999999, 'min': 100000, 'label': '100000-999999', 'color': '#B80909'},
{'max': 9999999, 'min': 1000000, 'label': '≧1000000', 'color': '#8A0808'}
]
gt_map = (
Map()
.add(series_name='累计确诊人数', data_pair=[list(z) for z in zip(country, curconfirm)], maptype="world", name_map=name_map, is_map_symbol_show=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="全球疫情数据(累计确诊)",
subtitle='数据更新至:' + time_global + '\n\n来源:百度疫情实时大数据报告'),
visualmap_opts=opts.VisualMapOpts(max_=300, is_piecewise=True, pieces=pieces),
)
)
return gt_map
【7x03】中国每日数据折线图 china_daily_map()
def china_daily_map():
wb = openpyxl.load_workbook('COVID-19-China.xlsx')
ws_china_confirmed = wb['中国每日累计确诊数据']
ws_china_crued = wb['中国每日累计治愈数据']
ws_china_died = wb['中国每日累计死亡数据']
ws_china_confirmed.delete_rows(1)
ws_china_crued.delete_rows(1)
ws_china_died.delete_rows(1)
x_date = [] # 日期
y_china_confirmed = [] # 每日累计确诊
y_china_crued = [] # 每日累计治愈
y_china_died = [] # 每日累计死亡
for china_confirmed in ws_china_confirmed.values:
y_china_confirmed.append(china_confirmed[1])
for china_crued in ws_china_crued.values:
x_date.append(china_crued[0])
y_china_crued.append(china_crued[1])
for china_died in ws_china_died.values:
y_china_died.append(china_died[1])
fi_map = (
Line(init_opts=opts.InitOpts(height='420px'))
.add_xaxis(xaxis_data=x_date)
.add_yaxis(
series_name="中国累计确诊数据",
y_axis=y_china_confirmed,
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="中国累计治愈趋势",
y_axis=y_china_crued,
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="中国累计死亡趋势",
y_axis=y_china_died,
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国每日累计确诊/治愈/死亡趋势"),
legend_opts=opts.LegendOpts(pos_bottom="bottom", orient='horizontal'),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
)
return fi_map
【7x04】境外每日数据折线图 foreign_daily_map()
def foreign_daily_map():
wb = openpyxl.load_workbook('COVID-19-Global.xlsx')
ws_foreign_confirmed = wb['境外每日累计确诊数据']
ws_foreign_crued = wb['境外每日累计治愈数据']
ws_foreign_died = wb['境外每日累计死亡数据']
ws_foreign_confirmed.delete_rows(1)
ws_foreign_crued.delete_rows(1)
ws_foreign_died.delete_rows(1)
x_date = [] # 日期
y_foreign_confirmed = [] # 累计确诊
y_foreign_crued = [] # 累计治愈
y_foreign_died = [] # 累计死亡
for foreign_confirmed in ws_foreign_confirmed.values:
y_foreign_confirmed.append(foreign_confirmed[1])
for foreign_crued in ws_foreign_crued.values:
x_date.append(foreign_crued[0])
y_foreign_crued.append(foreign_crued[1])
for foreign_died in ws_foreign_died.values:
y_foreign_died.append(foreign_died[1])
fte_map = (
Line(init_opts=opts.InitOpts(height='420px'))
.add_xaxis(xaxis_data=x_date)
.add_yaxis(
series_name="境外累计确诊趋势",
y_axis=y_foreign_confirmed,
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="境外累计治愈趋势",
y_axis=y_foreign_crued,
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="境外累计死亡趋势",
y_axis=y_foreign_died,
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="境外每日累计确诊/治愈/死亡趋势"),
legend_opts=opts.LegendOpts(pos_bottom="bottom", orient='horizontal'),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
)
return fte_map
【8x00】结果截图
【8x01】数据储存 Excel
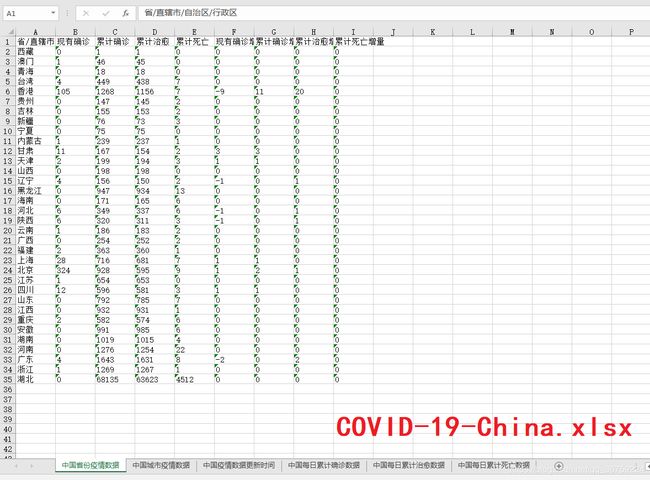
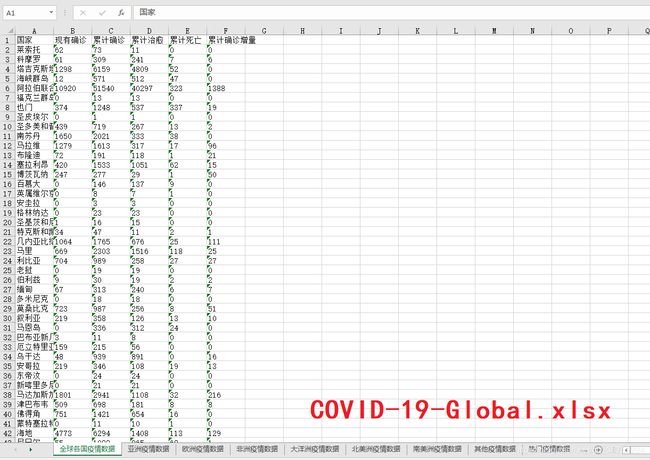
【8x02】词云图


【8x03】地图 + 折线图
【9x00】完整代码
预览地址:http://cov.itrhx.com/
完整代码地址(点亮 star 有 buff 加成):https://github.com/TRHX/Python3-Spider-Practice/tree/master/COVID-19
其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
这里是一段防爬虫文本,请读者忽略。
本文原创首发于 CSDN,作者 TRHX。
博客首页:https://itrhx.blog.csdn.net/
本文链接:https://itrhx.blog.csdn.net/article/details/107140534
未经授权,禁止转载!恶意转载,后果自负!尊重原创,远离剽窃!