机器学习学习笔记(一)
(一)引言
1.什么是机器学习
最早定义机器学习的人是Arthur Samuel,他对机器学习的定义是说,在进行特定编程的情况下,给予计算机学习能力的领域。
另一个年代近一点的定义,由Tom Mitchell提出,他说,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
通俗来讲,经验E 就是程序上万次的自我练习的经验,而任务T 就是解决问题的目标。性能度量值P呢,就是它在解决一个新的且与任务T同类的问题时,达到目标的概率。
例如:让计算机自己学会下棋,经验E则是让程序练习下棋(不断的下成千上万盘棋),并判断哪种布局(棋盘位置)会赢,哪种布局会输,而任务T则是赢棋,性能度量值P则是当下一盘新棋时,赢棋的概率。
在目前存在几种不同类型的学习算法中,主要的两种类型被我们称之为监督学习和无监督学习:监督学习这个想法是指,我们将教计算机如何去完成任务,而在无监督学习中,我们打算让它自己进行学习。
2.监督学习
先举个例子,假如说你想预测房价,你收集好有关房价的大量数据,并将数据画在二维坐标上。
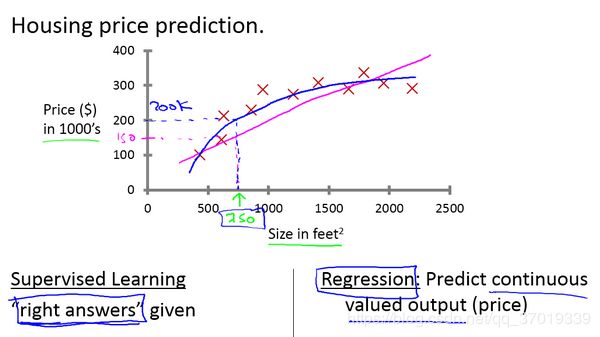
横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。
那基于这组数据,假如你有一个朋友,他有一套750平方英尺房子,现在他希望把房子卖掉,他想知道这房子能卖多少钱。那么关于这个问题,机器学习算法将会怎么帮助你呢?
我们应用学习算法,可以在这组数据中画一条直线,或者换句话说,拟合一条直线,根据这条线我们可以推测出,这套房子可能卖150k,当然这不是唯一的算法。可能还有更好的,比如我们不用直线拟合这些数据,用二次方程去拟合可能效果会更好。根据二次方程的曲线,我们可以从这个点推测出,这套房子能卖接近200k。以上就是监督学习的例子。
可以看出,监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价,然后运用学习算法,算出更多的正确答案。比如那个新房子的价格。用术语来讲,这叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格。
再例如,你想通过查看病历来推测乳腺癌良性与否,假如有人检测出乳腺肿瘤,恶性肿瘤有害并且十分危险,而良性的肿瘤危害就没那么大,所以人们显然会很在意这个问题。
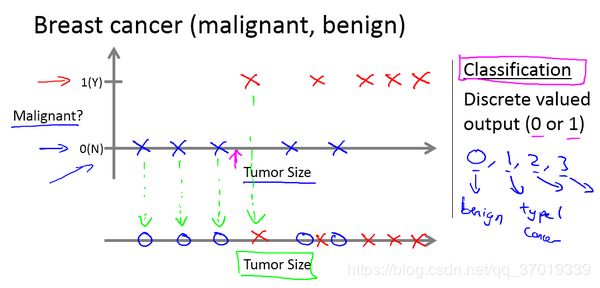 这个数据集中,横轴表示肿瘤的大小,纵轴上,1和0表示是或者不是恶性肿瘤。在之前数据中的肿瘤,如果是恶性则记为1,不是恶性,或者说良性记为0。图片上显示,数据集中有五个良性肿瘤,五个恶心肿瘤,那么机器学习的问题就在于,如若有人很不幸检查出乳腺肿瘤,你能否估算出肿瘤是恶性的或是良性的概率。用术语来讲,这是一个分类问题。
这个数据集中,横轴表示肿瘤的大小,纵轴上,1和0表示是或者不是恶性肿瘤。在之前数据中的肿瘤,如果是恶性则记为1,不是恶性,或者说良性记为0。图片上显示,数据集中有五个良性肿瘤,五个恶心肿瘤,那么机器学习的问题就在于,如若有人很不幸检查出乳腺肿瘤,你能否估算出肿瘤是恶性的或是良性的概率。用术语来讲,这是一个分类问题。
再比如说可能有三种乳腺癌,你希望预测离散输出0、1、2、3。0 代表良性,1 表示第1类乳腺癌,2表示第2类癌症,3表示第3类,但这也是分类问题。因为这几个离散的输出分别对应良性,第一类第二类或者第三类癌症,在分类问题中我们可以用另一种方式绘制这些数据点。
如上图,现在用不同的符号来表示这些数据。既然我们把肿瘤的尺寸看做区分恶性或良性的特征,那么可以这么画,用不同的符号来表示良性和恶性肿瘤。或者说是负样本和正样本现在我们不全部画X,良性的肿瘤改成用 O 表示,恶性的继续用 X 表示。来预测肿瘤的恶性与否。
在这里解释一下什么是回归问题,什么是分类问题。
回归这个词的意思是,我们在试着推测出这一系列连续值属性。
而分类指的是,我们试着推测出离散的输出值,离散的输出值可以不仅仅是1或0。
在其它一些机器学习问题中,可能会遇到不止一种特征。举个例子,我们不仅知道肿瘤的尺寸,还知道对应患者的年龄。在其他机器学习问题中,我们通常有更多的特征,比如肿块密度,肿瘤细胞尺寸的一致性和形状的一致性等等,还有一些其他的特征。
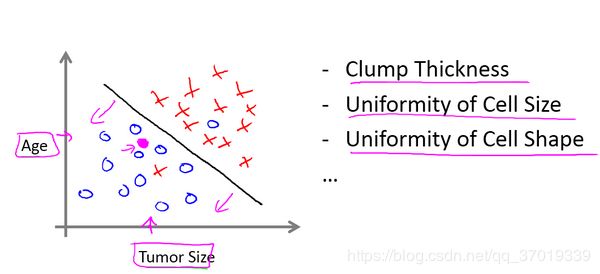
例如,上图中列举了总共5种不同的特征,坐标轴上的两种和右边的3种,但是在一些学习问题中,你希望不只用3种或5种特征。相反,你想用无限多种特征,好让你的算法可以利用大量的特征,或者说线索来做推测。那你怎么处理无限多个特征,甚至怎么存储这些特征都存在问题,你电脑的内存肯定不够用。这里有一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。
最后,回顾一下监督学习,其基本思想是:我们数据集中的每个样本都有相应的“正确答案”,再根据这些样本作出预测,就像房子和肿瘤的例子中做的那样。并且还介绍到了回归问题和分类问题,回归问题即通过回归来推出一个连续的输出,而分类问题其目标是推出一组离散的结果。
3.无监督学习
在监督学习的数据集中每条数据都已经标明是阴性或阳性,即是良性或恶性肿瘤。所以,对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案,是良性或恶性了。
而在无监督学习中,我们已知的数据。看上去有点不一样,不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
聚类应用的一个例子就是在谷歌新闻中。谷歌新闻每天都在收集非常多,非常多的网络的新闻内容。它再将这些新闻分组,组成有关联的新闻。所以谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起。如果这些新闻事件全是同一主题的,那这些新闻就会显示在一起。
所以这个就是无监督学习,因为我们没有提前告知算法一些信息,我们只是说,这里有一堆数据。我不知道数据里面有什么。我不知道谁是什么类型,我几乎什么都不知道。但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类,我没法提前知道哪些是哪些。因为我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习。
无监督学习或聚集有着大量的应用。例如社交网络的分析,将常联系的人群和不常联系的人群进行分隔,还有市场分割,将购物人群分割到各个更小的细分市场。当然,聚类只是无监督学习中的一种。
4.总结
总得来说,监督学习与无监督学习最大的区别在于,对于大量的数据集,前者有明确的“正确答案”,而后者没有。
监督学习中又解释一下什么是回归问题,什么是分类问题。
回归这个词的意思是,我们在试着推测出这一系列连续值属性。
而分类指的是,我们试着推测出离散的输出值。