Python+lxml+selenium爬虫-爬取豆瓣电影网电影信息
1 准备工作
A 安装pycharm
B selenium 安装
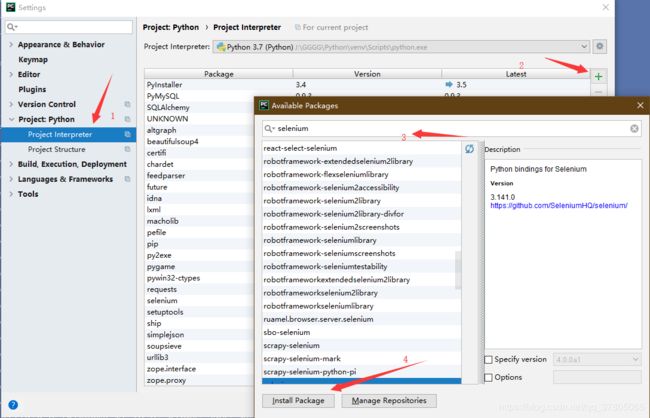
打开Pycharm,使用快捷键Ctrl+Shift+S打开Setting,根据下图指式安装selenium库
C chromedriver下载
chromedriver下载链接:http://npm.taobao.org/mirrors/chromedriver/。
将下载好的chromedriver.exe文件,放在谷歌浏览器安装目录下:

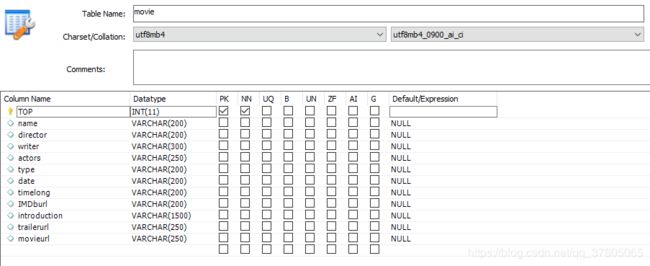
2 数据库表设计
movie表:用来存储豆瓣电影TOP250榜的250个电影的电影信息,其中电影信息包括:电影名、导演、编剧、主演、类型、上映日期、电影时长、IMDb链接URL地址、电影简介、预告片链接URL地址、电影链接URL地址。
豆瓣电影TOP250榜:https://movie.douban.com/top250?start=0&filter=
movie2表类似

3 爬虫主要功能介绍
1、爬取豆瓣TOP250榜上的电影信息(静态网页爬虫)。
2、爬取豆瓣首页最新上映的电影信息(动态网页爬虫)。
3、爬取豆瓣首页的最近热门电影信息(动态网页爬虫)。
4、搜索豆瓣网上的电影电影信息(动态网页爬虫)。
5、爬取到的电影信息存储到MySQL数据库中。
6、其中爬取过程中可设置是否下载电影预告片。
7、查询数据库中的电影信息。(电影名查询、电影类型查询)
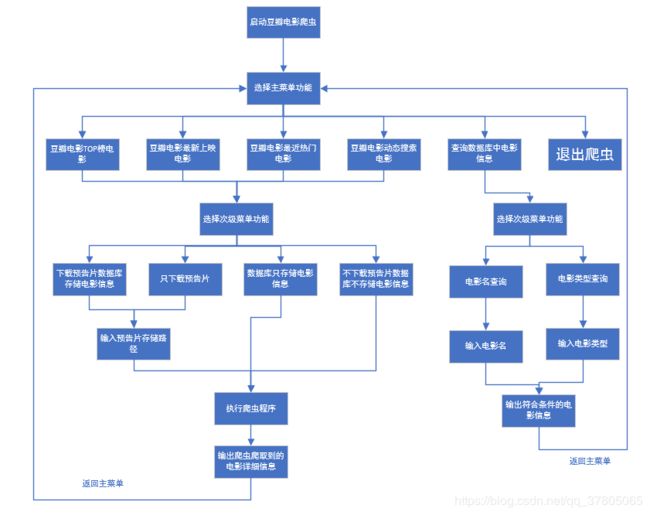
4 爬虫程序流程图
5 主要代码
A 爬虫类代码编写
class spider():
path=""#文件下载路径
mysqlflag=True#是否将数据插入数据库
downloadflag=True#是否下载预告片
# 构造函数 设置预告片存储路径 是否下载预告片? 是否插入数据表?
def __init__(self,path,downloadflag,mysqlflag):
self.path=path
self.downloadflag=downloadflag
self.mysqlflag=mysqlflag
#遍历页面
def foreach(self):
print()
print("豆瓣电影TOP250榜电影")
i=0
while i<10:
#遍历
#flag 为获取当前页电影链接返回的值 如果为1则遍历下一页 不为1继续遍历本页
flag=self.foreachpPageurl(i)
if flag==1:
i+=1
else:
print("重新访问当前页")
# 获取当前页电影链接
def foreachpPageurl(self, page):
url = "https://movie.douban.com/top250?start={}&filter=".format(page * 25)
header = dict()
header["user-agent"] = random.choice(headerlist)
try:
#通过requests.get()方法 获取网页信息
r = requests.get(url, headers=header)
r.raise_for_status()#网页状态码 200 2开头表示正常 4或5开头的抛出异常
#使用lxml将网页的源码转换成xml,然后使用xpath()进行xml解析
xml = lxml.etree.HTML(r.text)
#获取xml下类名为hd的div标签下的所有a标签的href属性 href装着电影链接url
a = xml.xpath("//div[@class='hd']/a/@href")
i = 0
count = page * 25 + 1
while i < (len(a)):
print("TOP {}".format(count))
#遍历当前页面的所有电影链接
flag = self.getMovieMessage(count, a[i],0)
sleep(3) # 休息两秒 应付反爬
if flag == 1:
i += 1
count += 1
print("")
else:
print("重新获取电影详细信息")
return 1
except:
print("当前页无法访问!")
return 0
#搜索豆瓣电影
def seachMovie(self,name):
chrome_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# os.environ['webdriver.chrome.driver'] = chrome_path#设置系统环境变量
drive = webdriver.Chrome(chrome_path) # 打开谷歌浏览器
# 打开一个网址
drive.get('https://movie.douban.com/subject_search?search_text={}&cat=1002'.format(name))
try:
#通过xpath查找网页标签
drive.implicitly_wait(3) # 等待3秒
a = drive.find_element_by_xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/a')
url = a.get_attribute('href')
a.click()#点击连接
#获取电影详细信息
self.getMovieMessage(0,url,1)
drive.implicitly_wait(5) # 等待5秒
except:
print("error")
#drive.close()#关闭页面
#最新上映电影
def LatestReleases(self):
chrome_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# os.environ['webdriver.chrome.driver'] = chrome_path#设置系统环境变量
drive = webdriver.Chrome(chrome_path) # 打开谷歌浏览器
drive.get('https://movie.douban.com/') # 打开一个网址
try:
#等待3秒 给予时间给浏览器加载javascript
drive.implicitly_wait(3)
# 通过xpath查找网页标签
a = drive.find_elements_by_xpath('//*[@id="screening"]/div[2]/ul/li/ul/li[1]/a')
#定义一个集合 用来存储最新上映电影链接地址
s = set()
for i in a:
s.add(i.get_attribute("href"))
print("最新上映的电影有{}个".format(len(s)))
l=list(s)#set转为list
drive.implicitly_wait(3) # 等待3秒
for i in range(len(l)):
print()
print("第{}个".format(i+1))
# 获取电影详细信息
self.getMovieMessage(i+1,l[i],1)
print()
except:
print("error")
# drive.close()#关闭页面
#最近热门电影
def recentot(self):
chrome_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# os.environ['webdriver.chrome.driver'] = chrome_path#设置系统环境变量
drive = webdriver.Chrome(chrome_path)#打开谷歌浏览器
drive.get( 'https://movie.douban.com/' )#打开一个网址
try:
# 等待3秒 给予时间给浏览器加载javascript
drive.implicitly_wait(3)
# 通过xpath查找网页标签
a=drive.find_elements_by_xpath('//*[@id="content"]/div/div[2]/div[4]/div[3]/div/div[1]/div/div//a')
# 定义一个集合 用来存储最近热门电影链接地址
s= set()
for i in a:
s.add(i.get_attribute("href"))
l=list(s)#set转为list
print("最近热门电影有{}个".format(len(l)))
for i in range(len(l)):
print()
print("第{}个".format(i+1))
#获取电影详细信息
self.getMovieMessage(0,l[i],1)
print()
drive.implicitly_wait(3)#等待3秒
except:
print("error")
# drive.close()#关闭浏览器
# 获取电影详细信息
def getMovieMessage(self, top, url,insertflag):#其中flag 用来决定插入哪个数据表 movie或movie2 用来判断使用哪一个数据库插入函数
print("豆瓣电影链接:{}".format(url))
header = dict()
#获取请求头的user-agent字典,应付反爬处理
header["user-agent"] = random.choice(headerlist)#通过random.choice随机抽取一个user-agent
director = '' # 导演
writer = '' # 编剧
actors = '' # 主演
type = '' # 类型
date = '' # 上映时间
timelong = '' # 时长
IMDb = '' # IMDb链接
text = '' # 简介
video = '' # 预告片
try:
#通过requests.get获取url链接
r = requests.get(url, headers=header)
r.raise_for_status()#网页状态码 200
xml = lxml.etree.HTML(r.text)#将网页源码转为xml 用lxml库进行解析
# 获取电影名
n = xml.xpath("//div[@id='content']/h1/span")#通过xpath获取网页标签
name = n[0].text + n[1].text
print("片名:{}".format(name))
div1 = xml.xpath("//div[@id='info']//span[@class='attrs']")
for i in range(len(div1)):
if i == 0:
#获取电影导演
x1 = div1[0].xpath("a")
for i in x1:
director += i.text + " "
elif i == 1:
#获取电影编剧
x2 = div1[1].xpath("a")
for i in x2:
writer += i.text + " "
elif i == 2:
#获取电影的前几个主演
x3 = div1[2].xpath("a")
for i in range(5):
if i >= len(x3): break
actors += x3[i].text + " "
# 以上这么写原因:有些电影无编剧 无主演 健壮代码
print("导演:{}".format(director))
print("编剧:{}".format(writer))
print("主演:{}".format(actors))
# 获取电视;类型
x4 = xml.xpath("//span[@property='v:genre']")
for i in x4:
type += i.text + " "
print("类型:{}".format(type))
# 获取电视上映日期
x5 = xml.xpath("//span[@property='v:initialReleaseDate']")
for i in x5:
date += i.text + " "
print("上映日期:{}".format(date))
# 获取电影片长
x6 = xml.xpath("//span[@property='v:runtime']")
for i in x6:
timelong += i.text + ' '
print("片长:{}".format(timelong))
#获取电影的IMDb链接
div2 = xml.xpath("//div[@id='info']/a/@href")
if len(div2)!=0:
IMDb = div2[0]
print("IMDb链接:{}".format(IMDb))
#获取电影简介
x7 = xml.xpath("//span[@property='v:summary']/text()")
for i in range(len(x7)):
text += " " + x7[i].strip()
if i < len(x7) - 1: text += '\n'
print("简介:\n{}".format(text))
#获取预告片链接
video = xml.xpath("//a[@title='预告片']/@href")
if len(video) >= 1:
print("预告片链接:{}".format(video[0]))
while True:
sleep(2) # 休息2秒
#前往预告片链接页面,获取预告片的播放地址,实现下载预告片功能
flag = self.getMovieTrailer(name, video[0])
if flag == 1:
#下载成功后,数据库插入数据
#根据myusql来决定是否将数据插入数据表中
if self.mysqlflag:
if insertflag==0:
#将电影详细信息插入数据库
mysql().insert(top, name,director,writer,actors,type,date,timelong,IMDb,text,video[0],url)
elif insertflag == 1:
mysql().insert2(name,director,writer,actors,type,date,timelong,IMDb,text,video[0],url)
return 1
else:
print("重新获取电影预告片")
else:
#有些电影没有预告片,数据库插入数据
# 根据myusql来决定是否将数据插入数据表中
print("该电影找不到预告片")
if self.mysqlflag:
if insertflag==0:
#执行插入函数1
mysql().insert(top, name, director, writer, actors, type, date, timelong, IMDb, text,"", url)
elif insertflag==1:
#执行插入函数2
mysql().insert2(name, director, writer, actors, type, date, timelong, IMDb, text, "", url)
return 1
except:
print("无法访问电影详细信息")
return 0
# 获取电影预告片
def getMovieTrailer(self, name, url):
header = dict()
header['user-agent'] = random.choice(headerlist)
try:
r = requests.get(url, headers=header)
xml = lxml.etree.HTML(r.text)
#预告片页面使用了javascript特性,预告片url地址藏在了内
#获取到指定的script标签后,对script标签下代码转换成字符串后进行字符串处理
#处理后便可以获取到预告片的实际播放地址url
#获取url后便可以进行下载操作,获取不到返回0表示该电影没有预告片
script = xml.xpath("//script[@type='application/ld+json']/text()")
str1 = str(script)
start = str1.find("http://vt1")
end = str1.find(".mp4")
result = str1[start:end + 4]
#根据downloadflag开关来决定是否下载预告片
if self.downloadflag :
while True:
sleep(2) # 休息2秒
# 下载预告片
flag = self.download(name, result)
if flag == 1:
return 1
else:
print("下载失败,重新下载")
else:
return 1
except:
print("无法获取电影预告片")
return 0
# 下载预告片
def download(self, name, url):
header = dict()
header['user-agent'] = random.choice(headerlist)
try:
r = requests.get(url, headers=header, timeout=30)
# 处理一下文件名 有些电影名中带 /\*:"?<>| ,windows中的文件名是不能有这些字符
NAME = ''
for i in range(len(name)):
if name[i] not in '/\*:"?<>|':
NAME += name[i]
else:
NAME += ""
filename = self.path + '\\' + NAME + ".mp4"#预告片路径
print("保存路径:{}".format(filename))
#通过二进制写入文件
with open(filename, 'wb') as f:
f.write(r.content)
f.close()#关闭流
print("下载成功")
return 1
except:
print("下载电影预告片失败")
return 0
B 数据库类代码编写
class mysql():
# 查询函数1
def select1(self, str):
# 打开数据库连接
db = pymysql.connect("localhost", 'root', 'yf123457.', 'yf')
# 获取游标
cursor = db.cursor()
# SQL 查询语句
sql = "select * from movie2 where name like '%{}%'".format(str)
try:
cursor.execute(sql)
result = cursor.fetchall()#获取查询内容
print("搜索结果有{}个".format(len(result)))
index = 1
for i in result:
print("\nIndex:{}".format(index))
print("豆瓣链接:{}".format(i[10]))
print("片名:{}".format(i[0]))
print("导演:{}".format(i[1]))
print("编剧:{}".format(i[2]))
print("主演:{}".format(i[3]))
print("类型:{}".format(i[4]))
print("上映日期:{}".format(i[5]))
print("片长:{}".format(i[6]))
print("IMDb:{}".format(i[7]))
print("简介:\n{}".format(i[8]))
print("预告片链接:{}".format(i[9]))
index += 1
print()
except:
print("数据查询异常")
db.rollback()#回滚
db.close()#关闭数据库连接
# 查询函数2
def select2(self, str):
# 打开数据库连接
db = pymysql.connect("localhost", 'root', 'yf123457.', 'yf')
# 获取游标
cursor = db.cursor()
# SQL 查询语句
sql = "select * from movie2 where type like '%{}%'".format(str)
try:
cursor.execute(sql)
result = cursor.fetchall()#获取查询内容
print("搜索结果有{}个".format(len(result)))
index = 1
for i in result:
print("\nIndex:{}".format(index))
print("豆瓣链接:{}".format(i[10]))
print("片名:{}".format(i[0]))
print("导演:{}".format(i[1]))
print("编剧:{}".format(i[2]))
print("主演:{}".format(i[3]))
print("类型:{}".format(i[4]))
print("上映日期:{}".format(i[5]))
print("片长:{}".format(i[6]))
print("IMDb:{}".format(i[7]))
print("简介:\n{}".format(i[8]))
print("预告片链接:{}".format(i[9]))
index += 1
print()
except:
db.rollback()
print("数据查询异常")
db.close()#关闭数据库连接
#插入函数1
def insert(self,top,moviename,director,writer,actors,type,date,timelong,IMDburl,introduction,tralerurl,movieurl):
# 打开数据库连接
db = pymysql.connect("localhost", "root", "yf123457.", "yf")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 电影简介内容出现""双引号 无法直接插入数据表中 需要进行处理
# 使用正则替换,便可以插入数据表中
temp = re.compile("\"")
text = temp.sub("\\\"", introduction)
#SQL 插入语句
sql = """INSERT INTO movie VALUES ({}, "{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")""" \
.format(top,moviename, director, writer, actors, type, date, timelong, IMDburl, text, tralerurl, movieurl)
# SQL 查询语句
sql2 = "select name from movie where name='{}'".format(moviename)
try:
# 执行sql语句
cursor.execute(sql2)
# 提交到数据库执行
result = cursor.fetchall()
if len(result)==0:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
print("数据插入成功")
else:
print("数据表中记录已存在")
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
#插入函数2
def insert2(self, moviename, director, writer, actors, type, date, timelong, IMDburl, introduction,
tralerurl, movieurl):
# 打开数据库连接
db = pymysql.connect("localhost", "root", "yf123457.", "yf")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 电影简介内容出现""双引号 无法直接插入数据表中 需要进行处理
# 使用正则替换,便可以插入数据表中
temp = re.compile("\"")
text = temp.sub("\\\"", introduction)
# SQL 插入语句
sql = """INSERT INTO movie2 VALUES ("{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")""" \
.format(moviename, director, writer, actors, type, date, timelong, IMDburl, text, tralerurl, movieurl)
sql2 = "select name from movie2 where name='{}'".format(moviename)
try:
# 执行sql语句
cursor.execute(sql2)
# 提交到数据库执行
result = cursor.fetchall()
if len(result)==0:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
print("数据插入成功")
else:
print("数据表中记录已存在")
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()6 爬虫菜单
菜单如图所示



菜单逻辑代码:
#菜单函数
def menu():
print("""------------------主-----菜-----单--------------------------
1 豆瓣电影TOP250榜电影
2 豆瓣电影最新上映电影
3 豆瓣电影最近热门电影
4 豆瓣电影动态搜索电影
5 查询数据库中电影信息
0 退-出-爬-虫
""")
try:
i=int(input("输入操作(0-5):"))
if i < 0 or i > 5:
print("操作有误,重新操作")
return 1
if i == 0:
return 0
if i == 5:
return menu2()#次级带单2
s = menu1()#次级菜单1
if s != 0:
if i == 1:
s.foreach()#执行豆瓣电影TOP250榜遍历函数
elif i == 2:
s.LatestReleases()#获取豆瓣最新上映电影
elif i == 3:
s.recentot()#获取豆瓣最近热门电影
elif i == 4:
s.seachMovie(input("输入电影关键词:"))#豆瓣搜索电影
else:
print("操作有误,重新操作")
return 1
return 1
except:
print("输入有误,请按规定输入数字")
#二级菜单1 获取spider爬虫类对象
def menu1():
print("""------------------次---级---菜---单-----------------------
1 不下载电影预告片,数据库不存储电影信息
2 下载电影预告片,数据库存储电影信息
3 数据库只存储电影信息
4 只下载电影预告片
""")
try:
i = int(input("输入操作(1-4):"))
if i == 1:
return spider("", False, False)#返回一个spider类对象
elif i == 2:
return spider(input("输入预告片存储路径:"), True, True)#返回一个spider类对象
elif i == 3:
return spider("", False, True)
elif i == 4:
return spider(input("输入预告片存储路径:"), True, False)#返回一个spider类对象
else:
print("操作有误,返回上一级")
return 0
except:
print("输入有误,请按规定输入数字")
return 0
#二级菜单2 查询数据库电影信息
def menu2():
m=mysql()
print("""------------------次---级---菜---单-----------------------
1 电影名查询
2 类型查询
""")
try:
i=int(input("输入操作(1-2):"))
except:
print("输入有误,请按规定输入数字")
return 0
try:
if i==1:
m.select1(input("输入查询电影名关键字:"))
elif i==2:
m.select2(input("输入查询电影类型关键字:"))
else:
print("操作有误,返回上次菜单")
return 1
except:
print("查询异常")
return 0
7 运行结果截图
爬虫功能有点多,这里只演示一个功能就好
演示的功能是主菜单第四个功能
a 运行爬虫程序

选择菜单4
b 选择次级菜单

然后选择2,下载电影预告片,数据库存储电影信息,并且输入预告片的存储路径
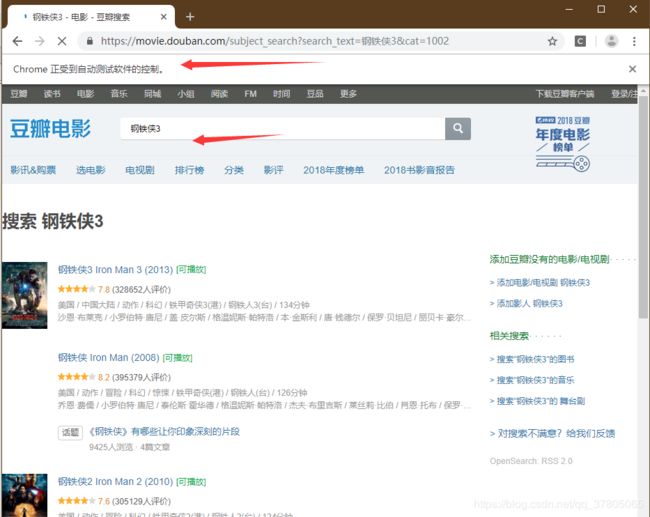
c 输入搜索电影关键字

selenium调用谷歌浏览器
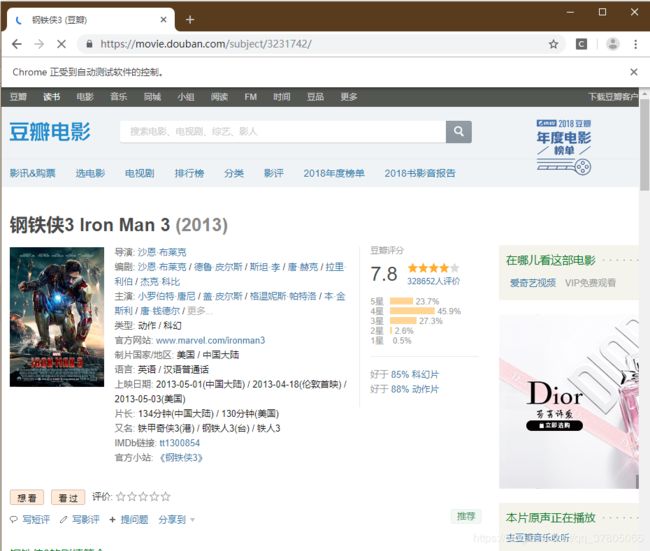
d pycharm控制台输出爬取到的电影详细信息


钢铁侠3预告片爬取完毕
e 数据表内容

8 爬虫全部代码
# Author:YFAN
import random
import requests
import lxml.etree
from time import sleep
import re
import pymysql
from selenium import webdriver
#浏览器请求头
headerlist = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/61.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Trident/5.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0.1 Safari/602.2.14',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Mozilla/5.0 (iPad; CPU OS 10_1_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0 Mobile/14B100 Safari/602.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:49.0) Gecko/20100101 Firefox/49.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0']
#---------分 --割 --线 -------------------
#数据库类
#完成数据插入 查询操作
class mysql():
# 查询函数1
def select1(self, str):
# 打开数据库连接
db = pymysql.connect("localhost", 'root', 'yf123457.', 'yf')
# 获取游标
cursor = db.cursor()
# SQL 查询语句
sql = "select * from movie2 where name like '%{}%'".format(str)
try:
cursor.execute(sql)
result = cursor.fetchall()#获取查询内容
print("搜索结果有{}个".format(len(result)))
index = 1
for i in result:
print("\nIndex:{}".format(index))
print("豆瓣链接:{}".format(i[10]))
print("片名:{}".format(i[0]))
print("导演:{}".format(i[1]))
print("编剧:{}".format(i[2]))
print("主演:{}".format(i[3]))
print("类型:{}".format(i[4]))
print("上映日期:{}".format(i[5]))
print("片长:{}".format(i[6]))
print("IMDb:{}".format(i[7]))
print("简介:\n{}".format(i[8]))
print("预告片链接:{}".format(i[9]))
index += 1
print()
except:
print("数据查询异常")
db.rollback()#回滚
db.close()#关闭数据库连接
# 查询函数2
def select2(self, str):
# 打开数据库连接
db = pymysql.connect("localhost", 'root', 'yf123457.', 'yf')
# 获取游标
cursor = db.cursor()
# SQL 查询语句
sql = "select * from movie2 where type like '%{}%'".format(str)
try:
cursor.execute(sql)
result = cursor.fetchall()#获取查询内容
print("搜索结果有{}个".format(len(result)))
index = 1
for i in result:
print("\nIndex:{}".format(index))
print("豆瓣链接:{}".format(i[10]))
print("片名:{}".format(i[0]))
print("导演:{}".format(i[1]))
print("编剧:{}".format(i[2]))
print("主演:{}".format(i[3]))
print("类型:{}".format(i[4]))
print("上映日期:{}".format(i[5]))
print("片长:{}".format(i[6]))
print("IMDb:{}".format(i[7]))
print("简介:\n{}".format(i[8]))
print("预告片链接:{}".format(i[9]))
index += 1
print()
except:
db.rollback()
print("数据查询异常")
db.close()#关闭数据库连接
#插入函数1
def insert(self,top,moviename,director,writer,actors,type,date,timelong,IMDburl,introduction,tralerurl,movieurl):
# 打开数据库连接
db = pymysql.connect("localhost", "root", "yf123457.", "yf")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 电影简介内容出现""双引号 无法直接插入数据表中 需要进行处理
# 使用正则替换,便可以插入数据表中
temp = re.compile("\"")
text = temp.sub("\\\"", introduction)
#SQL 插入语句
sql = """INSERT INTO movie VALUES ({}, "{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")""" \
.format(top,moviename, director, writer, actors, type, date, timelong, IMDburl, text, tralerurl, movieurl)
# SQL 查询语句
sql2 = "select name from movie where name='{}'".format(moviename)
try:
# 执行sql语句
cursor.execute(sql2)
# 提交到数据库执行
result = cursor.fetchall()
if len(result)==0:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
print("数据插入成功")
else:
print("数据表中记录已存在")
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
#插入函数2
def insert2(self, moviename, director, writer, actors, type, date, timelong, IMDburl, introduction,
tralerurl, movieurl):
# 打开数据库连接
db = pymysql.connect("localhost", "root", "yf123457.", "yf")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 电影简介内容出现""双引号 无法直接插入数据表中 需要进行处理
# 使用正则替换,便可以插入数据表中
temp = re.compile("\"")
text = temp.sub("\\\"", introduction)
# SQL 插入语句
sql = """INSERT INTO movie2 VALUES ("{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")""" \
.format(moviename, director, writer, actors, type, date, timelong, IMDburl, text, tralerurl, movieurl)
sql2 = "select name from movie2 where name='{}'".format(moviename)
try:
# 执行sql语句
cursor.execute(sql2)
# 提交到数据库执行
result = cursor.fetchall()
if len(result)==0:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
print("数据插入成功")
else:
print("数据表中记录已存在")
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
#---------分 --割 --线 -------------------
#豆瓣爬虫类
#豆瓣网 https://movie.douban.com/
#豆瓣TOP250电影榜 https://movie.douban.com/top250?start=0&filter=
class spider():
path=""#文件下载路径
mysqlflag=True#是否将数据插入数据库
downloadflag=True#是否下载预告片
# 构造函数 设置预告片存储路径 是否下载预告片? 是否插入数据表?
def __init__(self,path,downloadflag,mysqlflag):
self.path=path
self.downloadflag=downloadflag
self.mysqlflag=mysqlflag
#遍历页面
def foreach(self):
print()
print("豆瓣电影TOP250榜电影")
i=0
while i<10:
#遍历
#flag 为获取当前页电影链接返回的值 如果为1则遍历下一页 不为1继续遍历本页
flag=self.foreachpPageurl(i)
if flag==1:
i+=1
else:
print("重新访问当前页")
# 获取当前页电影链接
def foreachpPageurl(self, page):
url = "https://movie.douban.com/top250?start={}&filter=".format(page * 25)
header = dict()
header["user-agent"] = random.choice(headerlist)
try:
#通过requests.get()方法 获取网页信息
r = requests.get(url, headers=header)
r.raise_for_status()#网页状态码 200 2开头表示正常 4或5开头的抛出异常
#使用lxml将网页的源码转换成xml,然后使用xpath()进行xml解析
xml = lxml.etree.HTML(r.text)
#获取xml下类名为hd的div标签下的所有a标签的href属性 href装着电影链接url
a = xml.xpath("//div[@class='hd']/a/@href")
i = 0
count = page * 25 + 1
while i < (len(a)):
print("TOP {}".format(count))
#遍历当前页面的所有电影链接
flag = self.getMovieMessage(count, a[i],0)
sleep(3) # 休息两秒 应付反爬
if flag == 1:
i += 1
count += 1
print("")
else:
print("重新获取电影详细信息")
return 1
except:
print("当前页无法访问!")
return 0
#搜索豆瓣电影
def seachMovie(self,name):
chrome_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# os.environ['webdriver.chrome.driver'] = chrome_path#设置系统环境变量
drive = webdriver.Chrome(chrome_path) # 打开谷歌浏览器
# 打开一个网址
drive.get('https://movie.douban.com/subject_search?search_text={}&cat=1002'.format(name))
try:
#通过xpath查找网页标签
drive.implicitly_wait(3) # 等待3秒
a = drive.find_element_by_xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/a')
url = a.get_attribute('href')
a.click()#点击连接
#获取电影详细信息
self.getMovieMessage(0,url,1)
drive.implicitly_wait(5) # 等待5秒
except:
print("error")
#drive.close()#关闭页面
#最新上映电影
def LatestReleases(self):
chrome_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# os.environ['webdriver.chrome.driver'] = chrome_path#设置系统环境变量
drive = webdriver.Chrome(chrome_path) # 打开谷歌浏览器
drive.get('https://movie.douban.com/') # 打开一个网址
try:
#等待3秒 给予时间给浏览器加载javascript
drive.implicitly_wait(3)
# 通过xpath查找网页标签
a = drive.find_elements_by_xpath('//*[@id="screening"]/div[2]/ul/li/ul/li[1]/a')
#定义一个集合 用来存储最新上映电影链接地址
s = set()
for i in a:
s.add(i.get_attribute("href"))
print("最新上映的电影有{}个".format(len(s)))
l=list(s)#set转为list
drive.implicitly_wait(3) # 等待3秒
for i in range(len(l)):
print()
print("第{}个".format(i+1))
# 获取电影详细信息
self.getMovieMessage(i+1,l[i],1)
print()
except:
print("error")
# drive.close()#关闭页面
#最近热门电影
def recentot(self):
chrome_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# os.environ['webdriver.chrome.driver'] = chrome_path#设置系统环境变量
drive = webdriver.Chrome(chrome_path)#打开谷歌浏览器
drive.get( 'https://movie.douban.com/' )#打开一个网址
try:
# 等待3秒 给予时间给浏览器加载javascript
drive.implicitly_wait(3)
# 通过xpath查找网页标签
a=drive.find_elements_by_xpath('//*[@id="content"]/div/div[2]/div[4]/div[3]/div/div[1]/div/div//a')
# 定义一个集合 用来存储最近热门电影链接地址
s= set()
for i in a:
s.add(i.get_attribute("href"))
l=list(s)#set转为list
print("最近热门电影有{}个".format(len(l)))
for i in range(len(l)):
print()
print("第{}个".format(i+1))
#获取电影详细信息
self.getMovieMessage(0,l[i],1)
print()
drive.implicitly_wait(3)#等待3秒
except:
print("error")
# drive.close()#关闭浏览器
# 获取电影详细信息
def getMovieMessage(self, top, url,insertflag):#其中flag 用来决定插入哪个数据表 movie或movie2 用来判断使用哪一个数据库插入函数
print("豆瓣电影链接:{}".format(url))
header = dict()
#获取请求头的user-agent字典,应付反爬处理
header["user-agent"] = random.choice(headerlist)#通过random.choice随机抽取一个user-agent
director = '' # 导演
writer = '' # 编剧
actors = '' # 主演
type = '' # 类型
date = '' # 上映时间
timelong = '' # 时长
IMDb = '' # IMDb链接
text = '' # 简介
video = '' # 预告片
try:
#通过requests.get获取url链接
r = requests.get(url, headers=header)
r.raise_for_status()#网页状态码 200
xml = lxml.etree.HTML(r.text)#将网页源码转为xml 用lxml库进行解析
# 获取电影名
n = xml.xpath("//div[@id='content']/h1/span")#通过xpath获取网页标签
name = n[0].text + n[1].text
print("片名:{}".format(name))
div1 = xml.xpath("//div[@id='info']//span[@class='attrs']")
for i in range(len(div1)):
if i == 0:
#获取电影导演
x1 = div1[0].xpath("a")
for i in x1:
director += i.text + " "
elif i == 1:
#获取电影编剧
x2 = div1[1].xpath("a")
for i in x2:
writer += i.text + " "
elif i == 2:
#获取电影的前几个主演
x3 = div1[2].xpath("a")
for i in range(5):
if i >= len(x3): break
actors += x3[i].text + " "
# 以上这么写原因:有些电影无编剧 无主演 健壮代码
print("导演:{}".format(director))
print("编剧:{}".format(writer))
print("主演:{}".format(actors))
# 获取电视;类型
x4 = xml.xpath("//span[@property='v:genre']")
for i in x4:
type += i.text + " "
print("类型:{}".format(type))
# 获取电视上映日期
x5 = xml.xpath("//span[@property='v:initialReleaseDate']")
for i in x5:
date += i.text + " "
print("上映日期:{}".format(date))
# 获取电影片长
x6 = xml.xpath("//span[@property='v:runtime']")
for i in x6:
timelong += i.text + ' '
print("片长:{}".format(timelong))
#获取电影的IMDb链接
div2 = xml.xpath("//div[@id='info']/a/@href")
if len(div2)!=0:
IMDb = div2[0]
print("IMDb链接:{}".format(IMDb))
#获取电影简介
x7 = xml.xpath("//span[@property='v:summary']/text()")
for i in range(len(x7)):
text += " " + x7[i].strip()
if i < len(x7) - 1: text += '\n'
print("简介:\n{}".format(text))
#获取预告片链接
video = xml.xpath("//a[@title='预告片']/@href")
if len(video) >= 1:
print("预告片链接:{}".format(video[0]))
while True:
sleep(2) # 休息2秒
#前往预告片链接页面,获取预告片的播放地址,实现下载预告片功能
flag = self.getMovieTrailer(name, video[0])
if flag == 1:
#下载成功后,数据库插入数据
#根据myusql来决定是否将数据插入数据表中
if self.mysqlflag:
if insertflag==0:
#将电影详细信息插入数据库
mysql().insert(top, name,director,writer,actors,type,date,timelong,IMDb,text,video[0],url)
elif insertflag == 1:
mysql().insert2(name,director,writer,actors,type,date,timelong,IMDb,text,video[0],url)
return 1
else:
print("重新获取电影预告片")
else:
#有些电影没有预告片,数据库插入数据
# 根据myusql来决定是否将数据插入数据表中
print("该电影找不到预告片")
if self.mysqlflag:
if insertflag==0:
#执行插入函数1
mysql().insert(top, name, director, writer, actors, type, date, timelong, IMDb, text,"", url)
elif insertflag==1:
#执行插入函数2
mysql().insert2(name, director, writer, actors, type, date, timelong, IMDb, text, "", url)
return 1
except:
print("无法访问电影详细信息")
return 0
# 获取电影预告片
def getMovieTrailer(self, name, url):
header = dict()
header['user-agent'] = random.choice(headerlist)
try:
r = requests.get(url, headers=header)
xml = lxml.etree.HTML(r.text)
#预告片页面使用了javascript特性,预告片url地址藏在了内
#获取到指定的script标签后,对script标签下代码转换成字符串后进行字符串处理
#处理后便可以获取到预告片的实际播放地址url
#获取url后便可以进行下载操作,获取不到返回0表示该电影没有预告片
script = xml.xpath("//script[@type='application/ld+json']/text()")
str1 = str(script)
start = str1.find("http://vt1")
end = str1.find(".mp4")
result = str1[start:end + 4]
#根据downloadflag开关来决定是否下载预告片
if self.downloadflag :
while True:
sleep(2) # 休息2秒
# 下载预告片
flag = self.download(name, result)
if flag == 1:
return 1
else:
print("下载失败,重新下载")
else:
return 1
except:
print("无法获取电影预告片")
return 0
# 下载预告片
def download(self, name, url):
header = dict()
header['user-agent'] = random.choice(headerlist)
try:
r = requests.get(url, headers=header, timeout=30)
# 处理一下文件名 有些电影名中带 /\*:"?<>| ,windows中的文件名是不能有这些字符
NAME = ''
for i in range(len(name)):
if name[i] not in '/\*:"?<>|':
NAME += name[i]
else:
NAME += ""
filename = self.path + '\\' + NAME + ".mp4"#预告片路径
print("保存路径:{}".format(filename))
#通过二进制写入文件
with open(filename, 'wb') as f:
f.write(r.content)
f.close()#关闭流
print("下载成功")
return 1
except:
print("下载电影预告片失败")
return 0
#---------------------------
#----------------分割线-----------
#菜单函数
def menu():
print("""------------------主-----菜-----单--------------------------
1 豆瓣电影TOP250榜电影
2 豆瓣电影最新上映电影
3 豆瓣电影最近热门电影
4 豆瓣电影动态搜索电影
5 查询数据库中电影信息
0 退-出-爬-虫
""")
try:
i=int(input("输入操作(0-5):"))
if i < 0 or i > 5:
print("操作有误,重新操作")
return 1
if i == 0:
return 0
if i == 5:
return menu2()#次级带单2
s = menu1()#次级菜单1
if s != 0:
if i == 1:
s.foreach()#执行豆瓣电影TOP250榜遍历函数
elif i == 2:
s.LatestReleases()#获取豆瓣最新上映电影
elif i == 3:
s.recentot()#获取豆瓣最近热门电影
elif i == 4:
s.seachMovie(input("输入电影关键词:"))#豆瓣搜索电影
else:
print("操作有误,重新操作")
return 1
return 1
except:
print("输入有误,请按规定输入数字")
#二级菜单1 获取spider爬虫类对象
def menu1():
print("""------------------次---级---菜---单-----------------------
1 不下载电影预告片,数据库不存储电影信息
2 下载电影预告片,数据库存储电影信息
3 数据库只存储电影信息
4 只下载电影预告片
""")
try:
i = int(input("输入操作(1-4):"))
if i == 1:
return spider("", False, False)#返回一个spider类对象
elif i == 2:
return spider(input("输入预告片存储路径:"), True, True)#返回一个spider类对象
elif i == 3:
return spider("", False, True)
elif i == 4:
return spider(input("输入预告片存储路径:"), True, False)#返回一个spider类对象
else:
print("操作有误,返回上一级")
return 0
except:
print("输入有误,请按规定输入数字")
return 0
#二级菜单2 查询数据库电影信息
def menu2():
m=mysql()
print("""------------------次---级---菜---单-----------------------
1 电影名查询
2 类型查询
""")
try:
i=int(input("输入操作(1-2):"))
except:
print("输入有误,请按规定输入数字")
return 0
try:
if i==1:
m.select1(input("输入查询电影名关键字:"))
elif i==2:
m.select2(input("输入查询电影类型关键字:"))
else:
print("操作有误,返回上次菜单")
return 1
except:
print("查询异常")
return 0
# ----------------分----割----线-----------
#主函数
if __name__ == '__main__':
while True:
print()
flag=menu()#
if flag==0:break
sleep(3)