爬虫ip总被封?教你构造代理ip池
代理ip池
首先是所需库的准备:
requests,fake_useragent,lxml,time
安装方法
pip install xxx
并准备好数据库(这里使用redis)
所以我还安装了redis-py
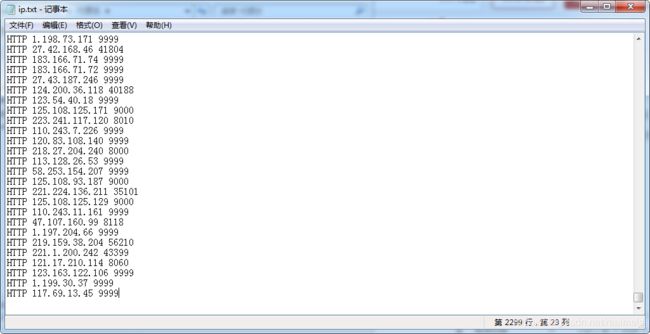
效果展示

fake_useragent
生成随机请求头
例如
from fake_useragent import UserAgent
ua=UserAgent()
headers={
'User-Agent':ua.random
}
print(headers)
运行结果如下
{‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:21.0.0) Gecko/20121011 Firefox/21.0.0’}
也有可能是其他的
redis-py
连接数据库
from redis import StrictRedis
redis=StrictRedis(host='localhost',db=0,port=6379,password=None)
redis.set('mykey','I love you')
print(redis.get('mykey').decode())
结果如下
I love you
思路整理
获取免费ip->检测是否可用->保存->每天自动运行
1:创建文件
get_ip.py
screen.py
这里推荐两个代理ip网站
西刺 https://www.xicidaili.com/
快代理 https://www.kuaidaili.com/
开始愉快的写代码
get_ip.py
import requests
from fake_useragent import UserAgent
from lxml import etree
import time
ua = UserAgent()
class XiCi:
def __init__(self):
self.ni = ['https://www.xicidaili.com/nn/%d' % x for x in range(1, 11)]
self.ordinary = ['https://www.xicidaili.com/nt/%d' % x for x in range(1, 11)]
self.headers = {'User-Agent': ua.random}
def get_ordinary(self):
ordinary = []
for item in self.ordinary:
r = requests.get(item, headers=self.headers).content.decode()
html = etree.HTML(r)
scheme1 = html.xpath('//tr[@class="odd"]/td[6]/text()')
ip1 = html.xpath('//tr[@class="odd"]/td[2]/text()')
port1 = html.xpath('//tr[@class="odd"]/td[3]/text()')
list = []
for i in range(len(scheme1)):
list.append('%s %s %s' % (scheme1[i], ip1[i], port1[i]))
scheme2 = html.xpath('//tr[@class=""]/td[6]/text()')
ip2 = html.xpath('//tr[@class=""]/td[2]/text()')
port2 = html.xpath('//tr[@class=""]/td[3]/text()')
list2 = []
for i in range(len(scheme2)):
list2.append('%s %s %s' % (scheme2[i], ip2[i], port2[i]))
for l in list + list2:
ordinary.append(l)
return ordinary
def get_ni(self):
ni = []
for item in self.ni:
r = requests.get(item, headers=self.headers).content.decode()
html = etree.HTML(r)
scheme1 = html.xpath('//tr[@class="odd"]/td[6]/text()')
ip1 = html.xpath('//tr[@class="odd"]/td[2]/text()')
port1 = html.xpath('//tr[@class="odd"]/td[3]/text()')
list = []
for i in range(len(scheme1)):
list.append('%s %s %s' % (scheme1[i], ip1[i], port1[i]))
scheme2 = html.xpath('//tr[@class=""]/td[6]/text()')
ip2 = html.xpath('//tr[@class=""]/td[2]/text()')
port2 = html.xpath('//tr[@class=""]/td[3]/text()')
list2 = []
for i in range(len(scheme2)):
list2.append('%s %s %s' % (scheme2[i], ip2[i], port2[i]))
for l in list + list2:
ni.append(l)
return ni
def get_xici(self):
return self.get_ordinary() + self.get_ni()
class KuaiDaiLi:
def __init__(self):
self.ni = ['https://www.kuaidaili.com/free/inha/%d/' % x for x in range(1, 11)]
self.ordinary = ['https://www.kuaidaili.com/free/intr/%d/' % x for x in range(1, 11)]
self.headers = {'User-Agent': ua.random}
def get_ordinary(self):
ordinary = []
for item in self.ordinary:
r = requests.get(item, headers=self.headers).content.decode()
html = etree.HTML(r)
scheme = html.xpath('//tbody/tr/td[@data-title="类型"]/text()')
ip = html.xpath('//tbody/tr/td[@data-title="IP"]/text()')
port = html.xpath('//tbody/tr/td[@data-title="PORT"]/text()')
for i in range(len(scheme)):
ordinary.append('%s %s %s' % (scheme[i], ip[i], port[i]))
time.sleep(1)
return ordinary
def get_ni(self):
ni = []
for item in self.ni:
r = requests.get(item, headers=self.headers).content.decode()
html = etree.HTML(r)
scheme = html.xpath('//tbody/tr/td[@data-title="类型"]/text()')
ip = html.xpath('//tbody/tr/td[@data-title="IP"]/text()')
port = html.xpath('//tbody/tr/td[@data-title="PORT"]/text()')
for i in range(len(scheme)):
ni.append('%s %s %s' % (scheme[i], ip[i], port[i]))
time.sleep(1)
return ni
def get_kuaidaili(self):
list1 = self.get_ordinary()
list2 = self.get_ni()
return list1 + list2
def get_ip():
xici=XiCi()
list1=xici.get_xici()
kuaidaili=KuaiDaiLi()
list2=kuaidaili.get_kuaidaili()
return list1+list2
screen.py
import requests
from fake_useragent import UserAgent
from get_ip import get_ip
from redis import StrictRedis
def detection(scheme, ip, port):
ua = UserAgent()
url = '%s://www.baidu.com/' % scheme
headers = {
'User-Agent': ua.random
}
proxies = {
scheme: ip + ':' + port
}
try:
r = requests.get(url, headers=headers, proxies=proxies, timeout=3)
return True
except:
return False
if __name__ == '__main__':
redis = StrictRedis(host='localhost', db=0, port=6379, password=12345)
redis.delete('ip')
list = get_ip()
file = open('ip.txt', 'w', encoding='utf-8')
for item in list:
l = item.split(' ')
if detection(l[0], l[1], l[2]):
file.write(item + "\n")
redis.lpush('ip', item)
print(item, '可用')
else:
pass
最后只要运行screen.py,默默等待即可
小白程序,大佬勿喷