用BeautifulSoup爬取猫眼榜单Top100电影
用BeautifulSoup爬取猫眼榜单Top100电影
- BeautifulSoup
- 准备工作
- 抓取分析
- 编程代码:
- 获取页面
- 解析网页
- 写入文件
- 代码整合
- 分页爬取
- 完整代码:
BeautifulSoup
最近再学习崔庆才的网络爬虫,之前看到用正则表达式爬取了猫眼Top100的电影,第一次爬取成功的时候还是蛮兴奋的。之后学习了BeautifulSoup,觉得可以试着用BeautifulSoup来编写爬取Top100的电影。这个程序编写参考了网上的BeautifulSoup崔庆才的正则表达式爬取编码。
准备工作
确保自己的电脑已经安装了所需要的库,例如requests、beautifulsoup等。
抓取分析
我们需要抓取的网站是:‘https://maoyan.com/board/4?offset=0’
打开网站后,看到的界面如下所示
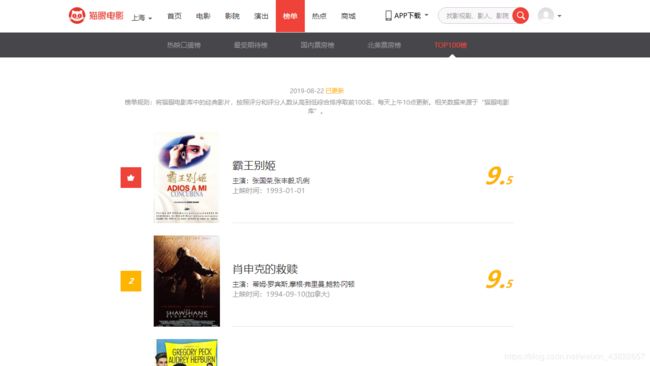
按F12或右击对网页进行检查
在代码中发现有一个"dd"的标签,同时发现每个dd标签代表了一部电影!
我们需要的的也就是“dd“节点

我们可以使用以下代码直接定位到所需的节点部分:
soup=BeautifulSoup(html,'lxml')
items=soup.find_all(name='dd')
我们想要输出电影的排名、电影名、主演、上映时间、评分,这些信息在源代码的位置如下:
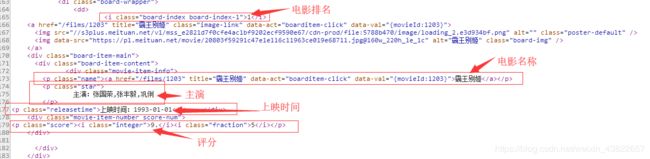
知道了这些所需要输出的信息的位置之后呢,接下来就是需要我们开始编程来打印输出这些信息啦。
编程代码:
获取页面
首先我们需要获取一个页面,如下:
def get_one_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response=requests.get(url)
if response.status_code==200:
return response.text
return None`
简单介绍一下,猫眼必须加上header伪装成浏览器,不然会被禁掉。这个headers是怎么回事呢,你可以把它理解成通行证。发送请求给服务器之后,服务器总的验证一下你是啥玩意,所以就只能看看headers喽。当前大家都是互相相信的,至于我伪不伪造通行证,那必然的不然谁让你爬啊。
解析网页
当获取到一个页面的源码后,开始解析这个网页的源代码,这里就需要用到BeautifulSoup方法了,我们先使用find_all()方法,获取到
def parse_one_page(html):
soup=BeautifulSoup(html,'lxml')
items=soup.find_all(name='dd')
for item in items:
yield{
'index':item.find(name='i',class_='board-index').string,
'name': item.find(name='p',class_='name').string,
'star': item.find(name='p', class_='star').string.strip()[3:],
'time': item.find(name='p', class_='releasetime').string[5:],
'score': item.find(name = 'i',class_ = 'integer').string,
}
使用items提取出所有的dd标签,再使用for循环对每一个遍历。
注意,这里name后跟的是标签名,所以标签名要加引号 ‘ ’ 。
敲代码时注意class名称后需要加下划线!必须的!因为class在Python中是一个关键字,所以要在后面加一个下划线以示区分。
string用于提起文本内容。
写入文件
随后,我们将提取的结果写入文件,这里直接写入到一个文本文件中。这里通过JSON库中的dump()方法实现字典的序列化,并指定ensure_ascii参数为False,这样就能保证输出的结果是中文形式而不是Unicode编码。如下:
def write_to_text(text):
with open('paiming.txt','a',encoding='utf-8') as t:
t.write(json.dumps(text,ensure_ascii=False)+'\n')
此处的参数text就是一部电影的提取结果,是一个字典。
代码整合
最后,实现main()方法来调用前面实现的方法。相关代码如下:
def main(offset):
url='https://maoyan.com/board/4?offset='+str(offset)
html=get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_text(item)
分页爬取
由于一页只有10部电影,爬取100部需要使用翻页功能,通过观察,我们发现URL的offset每次翻页都改变10。因此我们只需要稍微的改造一下就能完成翻页效果。相关代码如下:
if __name__=='__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)
至此,我们的爬取代码编写结束,接下来将代码整合下,即可完整爬取相关信息了。爬取结果如下:

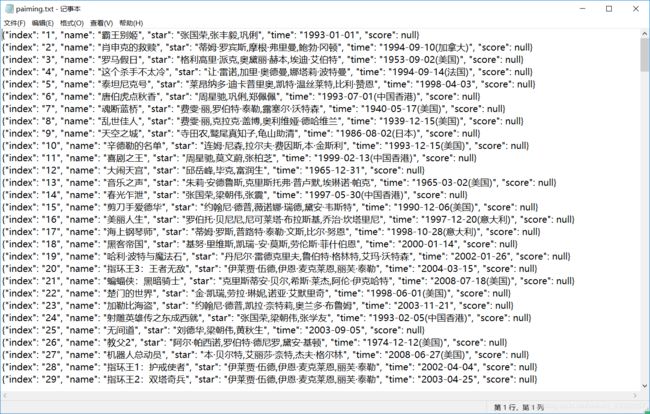
完整代码:
import re
import requests
from bs4 import BeautifulSoup
import time
import json
def get_one_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response=requests.get(url)
if response.status_code==200:
return response.text
return None
def parse_one_page(html):
soup=BeautifulSoup(html,'lxml')
items=soup.find_all(name='dd')
for item in items:
yield{
'index':item.find(name='i',class_='board-index').string,#爬取电影排名
'name': item.find(name='p',class_='name').string,#爬取电影名
'star': item.find(name='p', class_='star').string.strip()[3:],#爬取主演
'time': item.find(name='p', class_='releasetime').string[5:],#上映时间
'score': item.find(name = 'i',class_ = 'integer').string,#评分
}
def write_to_text(text):
with open('paiming.txt','a',encoding='utf-8') as t:
t.write(json.dumps(text,ensure_ascii=False)+'\n')
def main(offset):
url='https://maoyan.com/board/4?offset='+str(offset)
html=get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_text(item)
if __name__=='__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)