利用Flume和hadoop收集并管理tomcat日志
文章目录
- tomcat方
- 所需依赖
- js埋点
- 控制器层
- 配置文件
- Flume方
- Flume介绍
- Flume的安装
- Hadoop方
- hadoop简介
- Hadoop伪分布式安装
- hadoop组件
- HDFS
- Yarn
- MapReduce
- 启动hadoop

tomcat方
所需依赖
org.apache.flume
flume-ng-core
1.6.0
servlet-api
org.mortbay.jetty
org.apache.flume
flume-ng-configuration
1.6.0
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
mysql
mysql-connector-java
${mysql.version}
jstl
jstl
${jstl.version}
javax.servlet
servlet-api
${servlet-api.version}
provided
javax.servlet
jsp-api
${jsp-api.version}
provided
org.slf4j
slf4j-log4j12
${slf4j.version}
org.jsoup
jsoup
1.9.1
org.apache.storm
storm-core
1.0.1
provided
org.apache.storm
storm-kafka
1.0.1
org.apache.kafka
kafka_2.11
1.0.0
log4j
log4j
1.2.14
org.slf4j
log4j-over-slf4j
1.7.21
org.apache.tomcat.maven
tomcat7-maven-plugin
2.2
80
/
js埋点
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script type="text/javascript" src="js/track.js"></script>
<title>页面A</title>
</head>
<body >
<h2>埋点测试</h2>
<a href="b.jsp">访问下个页面</a>
</body>
<script type="text/javascript">
//函数可对字符串进行编码,防止中文乱码
function jt_encode(str){
//进行URL编码
return encodeURI(str);
}
//屏幕分辨率
function jt_get_screen(){
var c = "";
if (self.screen) {
c = screen.width+"x"+screen.height;
}
return c;
}
//颜色质量 单显(绿、黑色、白色)256色,16万色,32万色+
function jt_get_color(){
var c = "";
if (self.screen) {
c = screen.colorDepth+"-bit";
}
return c;
}
//返回当前的浏览器语言
function jt_get_language(){
var l = "";
var n = navigator;
if (n.language) {
l = n.language.toLowerCase();
}else if (n.browserLanguage) {
l = n.browserLanguage.toLowerCase();
}
return l;
}
//返回浏览器类型IE,Firefox
function jt_get_agent(){
var a = "";
var n = navigator;
if (n.userAgent) {
a = n.userAgent;
}
return a;
}
//方法可返回一个布尔值,该值指示浏览器是否支持并启用了Java
function jt_get_jvm_enabled(){
var j = "";
var n = navigator;
j = n.javaEnabled() ? 1 : 0;
return j;
}
//返回浏览器是否支持(启用)cookie
function jt_get_cookie_enabled(){
var c = "";
var n = navigator;
c = n.cookieEnabled ? 1 : 0;
return c;
}
//检测浏览器是否支持Flash或有Flash插件
function jt_get_flash_ver(){
var f="",n=navigator;
if (n.plugins && n.plugins.length) {
for (var ii=0;ii<n.plugins.length;ii++) {
if (n.plugins[ii].name.indexOf('Shockwave Flash')!=-1) {
f=n.plugins[ii].description.split('Shockwave Flash ')[1];
break;
}
}
}else if (window.ActiveXObject) {
for (var ii=10;ii>=2;ii--) {
try {
var fl=eval("new ActiveXObject('ShockwaveFlash.ShockwaveFlash."+ii+"');");
if (fl) {
f=ii + '.0';
break;
}
}
catch(e) {}
}
}
return f;
}
//匹配顶级域名
function jt_c_ctry_top_domain(str){
var pattern = "/^aero$|^cat$|^coop$|^int$|^museum$|^pro$|^travel$|^xxx$|^com$|^net$|^gov$|^org$|^mil$|^edu$|^biz$|^info$|^name$|^ac$|^mil$|^co$|^ed$|^gv$|^nt$|^bj$|^hz$|^sh$|^tj$|^cq$|^he$|^nm$|^ln$|^jl$|^hl$|^js$|^zj$|^ah$|^hb$|^hn$|^gd$|^gx$|^hi$|^sc$|^gz$|^yn$|^xz$|^sn$|^gs$|^qh$|^nx$|^xj$|^tw$|^hk$|^mo$|^fj$|^ha$|^jx$|^sd$|^sx$/i";
if(str.match(pattern)){ return 1; }
return 0;
}
//处理域名地址
function jt_get_domain(host){
//如果存在则截去域名开头的 "www."
var d=host.replace(/^www\./, "");
//剩余部分按照"."进行split操作,获取长度
var ss=d.split(".");
var l=ss.length;
//如果长度为3,则为xxx.yyy.zz格式
if(l == 3){
//如果yyy为顶级域名,zz为次级域名,保留所有
if(jt_c_ctry_top_domain(ss[1]) && jt_c_ctry_domain(ss[2])){
}else{ //否则只保留后两节
d = ss[1]+"."+ss[2];
}
}else if(l >= 3){ //如果长度大于3
//如果host本身是个ip地址,则直接返回该ip地址为完整域名
var ip_pat = "^[0-9]*\.[0-9]*\.[0-9]*\.[0-9]*$";
if(host.match(ip_pat)){
return d;
}
//如果host后两节为顶级域名及次级域名,则保留后三节
if(jt_c_ctry_top_domain(ss[l-2]) && jt_c_ctry_domain(ss[l-1])) {
d = ss[l-3]+"."+ss[l-2]+"."+ss[l-1];
}else{ //否则保留后两节
d = ss[l-2]+"."+ss[l-1];
}
}
return d;
}
//返回cookie信息
function jt_get_cookie(name){
//获取所有cookie信息
var co=document.cookie;
//如果名字是个空 返回所有cookie信息
if (name == "") {
return co;
}
//名字不为空 则在所有的cookie中查找这个名字的cookie
var mn=name+"=";
var b,e;
b=co.indexOf(mn);
//没有找到这个名字的cookie 则返回空
if (b < 0) {
return "";
}
//找到了这个名字的cookie 获取cookie的值返回
e=co.indexOf(";", b+name.length);
if (e < 0) {
return co.substring(b+name.length + 1);
}
else {
return co.substring(b+name.length + 1, e);
}
}
/**
设置cookie信息
操作符:
0 表示不设置超时时间 cookie是一个会话级别的cookie cookie信息保存在浏览器内存当中 浏览器关闭时cookie消失
1 表示设置超时时间为10年以后 cookie会一直保存在浏览器的临时文件夹里 直到超时时间到来 或用户手动清空cookie为止
2 表示设置超时时间为1个小时以后 cookie会一直保存在浏览器的临时文件夹里 直到超时时间到来 或用户手动清空cookie为止
**/
function jt_set_cookie(name, val, cotp){
var date=new Date;
var year=date.getFullYear();
var hour=date.getHours();
var cookie="";
if (cotp == 0) {
cookie=name+"="+val+";";
}else if (cotp == 1) {
year=year+10;
date.setYear(year);
cookie=name+"="+val+";expires="+date.toGMTString()+";";
}else if (cotp == 2) {
hour=hour+1;
date.setHours(hour);
cookie=name+"="+val+";expires="+date.toGMTString()+";";
}
var d=jt_get_domain(document.domain);
if(d != ""){
cookie +="domain="+d+";";
}
cookie +="path="+"/;";
document.cookie=cookie;
}
//返回客户端时间
function jt_get_stm(){
return new Date().getTime();
}
//返回格式化日期 yyyyMMdd
function getFormatDate(){
var d = new Date();
var curr_date = d.getDate();
var curr_month = d.getMonth() + 1;
var curr_year = d.getFullYear();
String(curr_month).length < 2 ? (curr_month = "0" + curr_month): curr_month;
String(curr_date).length < 2 ? (curr_date = "0" + curr_date): curr_date;
var yyyyMMdd = curr_year + "" + curr_month +""+ curr_date;
return yyyyMMdd;
}
//返回指定个数的随机数字串
function jt_get_random(n) {
var str = "";
for (var i = 0; i < n; i ++) {
str += String(parseInt(Math.random() * 10));
}
return str;
}
// main function
function jt_main(dest_path) {
//收集完日志 提交到的路径
var expire_time = 30 * 60 * 1000; //会话超时时长,三十分钟
//处理uv
//--获取cookie jt_stat_uv的值
var uv_str = jt_get_cookie("jt_stat_uv");
var uv_id = "";
//--如果cookie jt_stat_uv的值为空
if (uv_str == ""){
//--为这个新uv配置id,为一个长度20的随机数字
uv_id = jt_get_random(20);
//--设置cookie jt_stat_uv 保存时间为10年
jt_set_cookie("jt_stat_uv", uv_id, 1);
}
//--如果cookie jt_stat_uv的值不为空
else{
//--获取uv_id
uv_id = uv_str;
}
//处理ss
//--获取cookie jt_stat_ss
var ss_str = jt_get_cookie("jt_stat_ss");
var ss_id = ""; //sessin id
var ss_no = 0; //session有效期内访问页面的次数
//--如果cookie中不存在jt_stat_ss 说明是一次新的会话
if (ss_str == ""){
//--随机生成长度为10的session id
ss_id = jt_get_random(10);
//--session有效期内页面访问次数为0
ss_no = 0;
//--拼接cookie jt_stat_ss 值 格式为 会话编号_会话期内访问次数_客户端时间_网站id
value = ss_id+"_"+ss_no+"_"+jt_get_stm();
//--设置cookie jt_stat_ss
jt_set_cookie("jt_stat_ss", value, 0);
}
//--如果cookie中存在jt_stat_ss
else {
//获取ss相关信息
var items = ss_str.split("_");
//--ss_id
var cookie_ss_id = items[0];
//--ss_no
var cookie_ss_no = parseInt(items[1]);
//--ss_stm
var cookie_ss_stm = items[2];
//如果当前时间-当前会话上一次访问页面的时间>30分钟,虽然cookie还存在,但是其实已经超时了!仍然需要重新生成cookie
if (jt_get_stm() - cookie_ss_stm > expire_time) {
//--重新生成会话id
ss_id = jt_get_random(10);
//--设置会话中的页面访问次数为0
ss_no = 0;
}
//--如果会话没有超时
else{
//--会话id不变
ss_id = cookie_ss_id;
//--设置会话中的页面方位次数+1
ss_no = cookie_ss_no + 1;
}
//--重新拼接cookie jt_stat_ss的值
value = ss_id+"_"+ss_no+"_"+jt_get_stm();
jt_set_cookie("jt_stat_ss", value, 0);
}
//当前地址
var url = document.URL;
url = jt_encode(String(url));
//当前资源名
var urlname = document.URL.substring(document.URL.lastIndexOf("/")+1);
urlname = jt_encode(String(urlname));
//返回导航到当前网页的超链接所在网页的URL
var ref = document.referrer;
ref = jt_encode(String(ref));
//网页标题
var title = document.title;
title = jt_encode(String(title));
//网页字符集
var charset = document.charset;
charset = jt_encode(String(charset));
//屏幕信息
var screen = jt_get_screen();
screen = jt_encode(String(screen));
//颜色信息
var color = jt_get_color();
color = jt_encode(String(color));
//语言信息
var language = jt_get_language();
language = jt_encode(String(language));
//浏览器类型
var agent = jt_get_agent();
agent = jt_encode(String(agent));
//浏览器是否支持并启用了java
var jvm_enabled =jt_get_jvm_enabled();
jvm_enabled = jt_encode(String(jvm_enabled));
//浏览器是否支持并启用了cookie
var cookie_enabled = jt_get_cookie_enabled();
cookie_enabled = jt_encode(String(cookie_enabled));
//浏览器flash版本
var flash_ver = jt_get_flash_ver();
flash_ver = jt_encode(String(flash_ver));
//当前ss状态 格式为"会话id_会话次数_当前时间"
var stat_ss = ss_id+"_"+ss_no+"_"+jt_get_stm();
//拼接访问地址 增加如上信息
dest = dest_path
+"?url="+url
+"&urlname="+urlname
+"&title="+title
+"&chset="+charset
+"&scr="+screen
+"&col="+color
+"&lg="+language
+"&je="+jvm_enabled
+"&ce="+cookie_enabled
+"&fv="+flash_ver
+"&cnv="+String(Math.random())
+"&ref="+ref
+"&uagent="+agent
+"&stat_uv="+uv_id
+"&stat_ss="+stat_ss;
//通过插入图片访问该地址,并不返回图片内容
document.getElementsByTagName("body")[0].innerHTML += " +dest+"\" border=\"0\" width=\"1\" height=\"1\" />";
}
window.onload = function(){
//触发main方法
var logserverUrl = "http://localhost/servlet/logServlet";
jt_main(logserverUrl);
}
</script>
</html>
+dest+"\" border=\"0\" width=\"1\" height=\"1\" />";
}
window.onload = function(){
//触发main方法
var logserverUrl = "http://localhost/servlet/logServlet";
jt_main(logserverUrl);
}
</script>
</html>
控制器层
public class LogServlet extends HttpServlet {
private static Logger log = Logger.getLogger(LogServlet.class);
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//对get请求串解码,防止中文乱码
String qs = URLDecoder.decode(request.getQueryString(), "utf-8");
// www.jt.com?username="老张"&age=13&gender="男"
// username="老张"&age=13&gender="男"
// 请求串中各指标以&符号分割
String [] attrs = qs.split("\\&");
// username="老张" age=13 gender="男"
StringBuffer buf = new StringBuffer();
for(String attr : attrs){
// 每个指标以kv形式存在,中间用=分割
String [] kv = attr.split("=");
String key = kv[0]; //指标名称
String val = kv.length == 2 ? kv[1] : ""; //指标值
buf.append(val + "|"); //指标以|分割
// username="老张"&age=13&gender="男"
// 老张|13|男
}
buf.append(request.getRemoteAddr()); //增加服务器端IP地址指标
String loginfo = buf.toString();
log.info(loginfo);
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
配置文件
log4j.rootLogger = info,stdout,flume
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %m%n
## appender flume avro 以下配置为连接到flume服务器
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = hadoop01 #在本地hosts文件中映射服务器ip
log4j.appender.flume.Port = 22222
log4j.appender.flume.layout = org.apache.log4j.PatternLayout
log4j.appender.flume.UnsafeMode = true
## appender KAFKA
#log4j.appender.KAFKA=kafka.producer.KafkaLog4jAppender
#log4j.appender.KAFKA.topic=jtlog
#log4j.appender.KAFKA.brokerList=brokerNode1:9091,brokerNode2:9092
#log4j.appender.KAFKA.compressionType=none
#log4j.appender.KAFKA.syncSend=true
#log4j.appender.KAFKA.layout=org.apache.log4j.PatternLayout
#log4j.appender.KAFKA.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L %% - %m%n

Flume方
Flume介绍
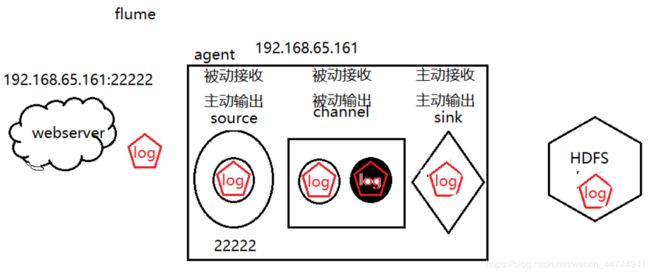
Flume是一个分布式的支持高可用的框架,用于收集,聚合,移动日志数据,它具有简单的流式数据处理的特点{流式数据:DAG有向无环}。数据处理模型非常简单,特点是使用灵活。

flume重要概念:
agent:代表flume接收封装承载传输数据的整个过程,flume集群中,每个节点都叫做一个agen
event:flume在接收数据之后会将日志数据封装为一个个的event,封装为json,
{“headers”:自定义内容,“body”:我今天早上喝了一杯咖啡},其中body为数据本身
source(数据来源):被动接收日志数据,并将其封装为event,主动输出到channel中进行缓存
== source能接收的数据常用有avro[字符虚列串]、http请求、spooldir[本地目录下的资源]==
channel:被动接收source传来的event,进行缓存,等待sink的消费。
sink:主动消费channel中的event并将其输出到指定位置(HDFS或者下一个agent)
Flume的安装
官网:http://flume.apache.org/
Flume因为是java所写,所以在具备JDK环境下,在官网上下载flume上传解压即可用。在flume的主目录下,有一个conf目录,flume的配置文件flume.properties就在其中(没有则建立一个);
vim flume.properties
#a1为自定义的agent名字,与启动命令中的-n属性对应
a1.sources = r1 #定义agent的数据源source,可以有多个。
a1.sinks = k1 #定义agent的数据出处,可以有多个。
a1.channels = c1 #定义agent的通道,一般有多少个sink就有多少个channel
a1.sources.r1.type = avro #指定数据源的类型为字符序列串
a1.sources.r1.bind = 0.0.0.0 #指定source的来源。一般为本机,被动接收。当前为任意
a1.sources.r1.port = 22222 #指定当前flume端口
//因为日志是很小的数据,而hadoop中存储块是128M,在这里可以配置满128M再落地HDFS
a1.sinks.k1.type = hdfs #指定sink的类型为hadoop的hdfs
a1.sinks.k1.hdfs.path= hdfs://hadoop01:9000/jt/data #指定sink的目标节点路径
a1.sinks.k1.hdfs.fileTpe = DataStream #指定文件类型为数据流
a1.channels.c1.type = memory #指定channel的类型为 内存
a1.channels.c1.capacity = 1000 #指定存储容量,避免强制抢占内存影响其他进程的正常运行
a1.channels.c1.transactionCapacity = 100 #指定事务容量
a1.sources.r1.channels = c1 #绑定source
a1.sinks.k1.channel = c1 #绑定sink
启动命令:
../bin/flume-ng agent -c ./ -f ./flume.properties -n a1 -Dflume.root.logger=INFO,console
解析:上一层的bin目录下执行flume-ng命令, 执行conf文件为当前目录下的flume.properties,指定该配置文件的a1为Dflume.root.logger(INFO类型)
JPS命令检查:出现 Application 则证明启动成功;
Hadoop方
官网:http://hadoop.apache.org/
hadoop简介
Hadoop是大数据领域中非常重要的基础技术,他是一个海量数据存储、处理系统,也是一个生态圈(HDFS,MapReduce,Hive,Hbase等),主要用作海量离线数据的存储和离线数据的计算。流行版本为2.7.1(作者:Doug Cutting,java开发)
三种安装模式:
单机模式:解压就能运行,但是只支持MapReduce的测试,不支持HDFS,不常用。
伪分布式模式:单机通过多进程模拟集群方式安装,支持Hadoop所有功能。优点:功能完整。缺点:性能低下。
完全分布式模式:集群方式安装,所有节点的高可用,生产级别。
Hadoop伪分布式安装
大环境配置:hadoop也是java所写,所以需要java环境,JDK,JAVA_HOME,配置hosts,关闭防火墙,配置免密登录等。
第一步:下载并解压,本次示例安装在/home/app目录下
第二步:修改hadoop-env.sh
vim /home/app/hadoop-2.7.1/etc/hadoop/hadoop-env.sh

hadoop组件
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Ozone: An object store for Hadoop.
这里只点出最重要的三个组件:
HDFS
hdfs优点是:可存储超大文件,理论可无限拓展,高容错,支持数据丢失自动恢复,可以构建在廉价机群上。
缺点是:做不到低延迟访问,不支持事务,不适合存储大量小文件,不支持行级别的增删改。

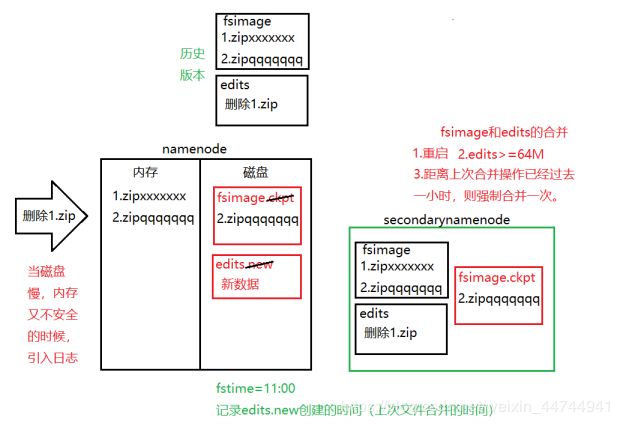
NameNode节点:HDFS集群中的老大,负责元数据信息(文件分为几块,备份几份,每一份都存在哪里的描述信息)的存储和整个集群工作的调度。
第三步:修改core-site.xml,增加以下内容到 configuration 标签内
vim /home/app/hadoop-2.7.1/etc/hadoop/core-site.xml
fs.default.name
hdfs://hadoop01:9000
hadoop.tmp.dir
/home/app/hadoop-2.7.1/tmp
DataNode:保存文件块,记录自己存放文件的基本信息(按信息备份故障时自动恢复)
Block:文件块,Hadoop1.0时,每块64M。Hadoop2.0时,每块128M。默认备份三份。
第一份位置:上传节点机器上。第二份:第一份节点机架的隔壁机架。第三份:第二份所在机架的另一台机器,三分以上:负载较小的节点上。
第四步:修改hdfs-site.xml,增加以下内容到 configuration 标签内
vim /home/app/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.permissions
false
SecondaryNameNode:NameNode的小秘,帮助NameNode对fsimage和edits进行合并。分担NameNode的压力{NameNode在完成文件合并时,因为Edits文件被占用,造成HDFS无法对外提供服务,不时的合并文件加大了它的压力,一旦Namenode宕机,整个服务瘫痪,磁盘损坏会造成这个系统文件丢失,所以secondaryNameNode帮助nameNode完成文件合并}
HDFS基本Shell操作命令:
创建文件夹(不支持多级创建):
hadoop fs -mkdir /xxx
查看目录:
hadoop fs -ls /xxx
递归查看多级目录:
hadoop fs -lsr /xxx
上传文件到HDFS:
hadoop fs -put xxx.txt /xxx
下载文件到本地当前目录:
hadoop fs -get /xxx/xxx/xxx.txt
删除文件:
hadoop fs -rm /xxx/xxx/xxx.txt
删除文件夹(文件夹必须为空):
hadoop fs -rmdir /xxx/xxx
强制删除文件夹或文件
Hadoop fs -rm -r /xxx
Yarn
yarn相当于Hadoop中的大管家,负责整个集群的资源管理调度。主要用于管理MapReduce相关资源,原来HDFS中的数据只能被MapReduce直接处理,引入Yarn之后可以支持多种数据处理工具的接入,包括Spark等(相当于插排)

第五步:修改mapred-site.xml
说明:在/home/app/hadoop-2.7.1/etc/hadoop的目录下,只有一个mapred-site.xml.template文件,复制一个。修改mapred-site.xml,复制到 configuration 标签内。
cp mapred-site.xml.template mapred-site.xml
vim /home/app/hadoop-2.7.1/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
第六步:修改yarn-site.xml,复制内容到 configuration 标签内
vim /home/app/hadoop-2.7.1/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
MapReduce
MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框,就是mapreduce,缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程。
MapReduce是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为Map和Reduce两个阶段的编程模型。
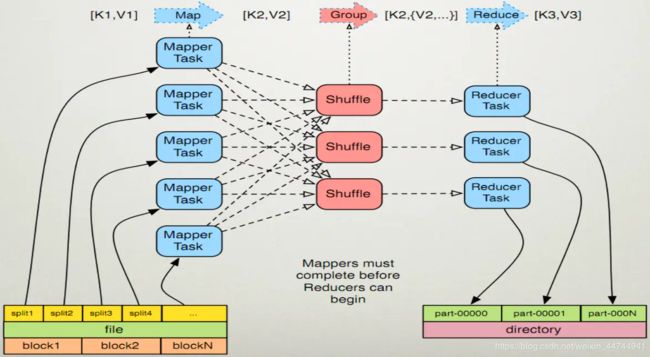
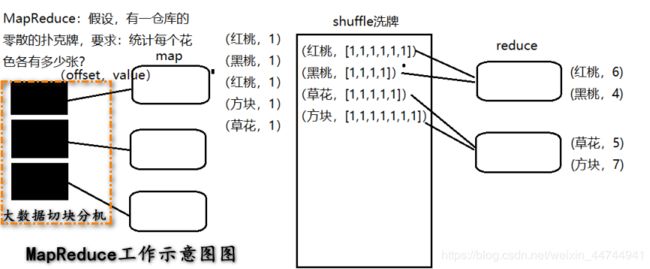
记住一点:Map的输出既是Reduce的输入。即:
Map:
Reduce:
- 在启动map函数前,需要对输入文件进行“分片”,也就是把所要输入的文件copy到HDFS中。
- 在分片结束后,启动job就开始读取HDFS中的内容了,map对每条记录的输出以
- 在进入reduce阶段之前,还要将各个map中相关的数据(key相同的数据)进过洗牌,排序,reduce,归结到一起,发往一个reducer。
- 进入reduce阶段。相同的key的map输出会到达同一个reducer,reducer对key相同的多个value进行“reduce操作”.
Map-Reduce框架的运作完全基于
简单的说来,Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定,比如对[1, 2, 3, 4]进行乘2的映射就变成了[2, 4, 6, 8]。
Map任务处理
读取HDFS中的文件。每一行解析成一个。每一个键值对调用一次map函数
重写map(),对第一步产生的进行处理,转换为新的输出
对输出的key、value进行分区
对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中
(可选)对分组后的数据进行归约
Reduce是对一组数据进行归约,这个归约的规则由一个函数指定,比如对[1, 2, 3, 4]进行求和的归约得到结果是10,而对它进行求积的归约结果是24。
Reduce任务处理
多个map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点上
对多个map的输出进行合并、排序。
重写reduce函数实现自己的逻辑,对输入的key、value处理,转换成新的key、value输出
把reduce的输出保存到文件中
第七步:修改slaves
vim /home/app/hadoop-2.7.1/etc/hadoop/slaves
添加节点ip,因为是伪分布式,所以只写当前ip(hadoop01)
配置hadoop环境变量
vim /etc/profile
#set java environment
JAVA_HOME=/home/app/jdk1.8.0_65
JAVA_BIN=/home/app/jdk1.8.0_65/bin
HADOOP_HOME=/home/app/hadoop-2.7.1
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN HADOOP_HOME PATH CLASSPATH
重新加载profile使配置生效
source /etc/profile
环境变量配置成功,测试环境变量是否生效
echo $HADOOP_HOME
启动hadoop
初始化
hdfs namenode -format
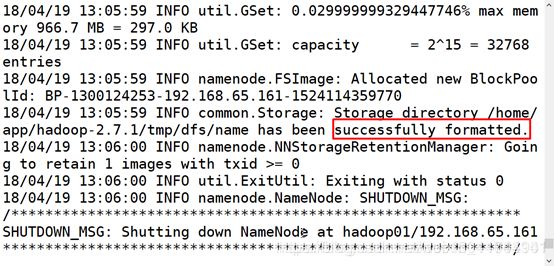
由于配置了hadoop环境变量,所以可以在任意地方执行以下命令
启动
start-all.sh
停止
stop-all.sh
测试是否成功
jsp

访问hadoop: hadoop01:50070
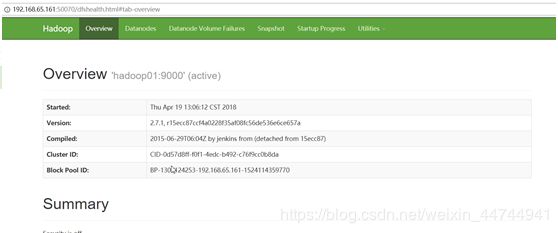
如果没有成功(进程数不够)
1.stop-all.sh 停掉hadoop所有进程
2.删掉hadoop2.7.1下的tmp文件并重新创建tmp
3.hdfs namenode -format 重新初始化(出现successfully证明成功),如果配置文件报错,安装报错信息修改相应位置后重新执行第二步。
4.start-all.sh 启动hadoop
查看flume收集传输到HDFS保存的日记数据: