基于HttpClient实现网络爬虫~以百度新闻为例
转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/40891791
基于HttpClient4.5实现网络爬虫请访问这里:http://blog.csdn.net/xiaojimanman/article/details/53178307
在以前的工作中,实现过简单的网络爬虫,没有系统的介绍过,这篇博客就系统的介绍以下如何使用java的HttpClient实现网络爬虫。
关于网络爬虫的一些理论知识、实现思想以及策略问题,可以参考百度百科“网络爬虫”,那里已经介绍的十分详细,这里也不再啰嗦,下面就主要介绍如何去实现。
http请求:
代码开始之前,还是首先介绍以下如何通过浏览器获取http请求信息,这一步是分析网站资源的第一步。在浏览器界面右键有“审查元素”这一功能(如果没找到,F12一样可以的),谷歌浏览器效果如下:

点击“审查元素”之后会出现如下界面:

其中的Network栏目是做爬虫应该重点关注的,打开会看到当前网页所有的http请求信息,如下图: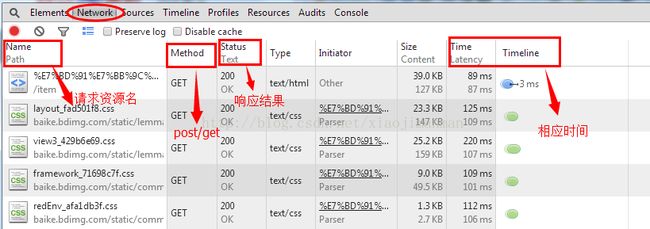
单击每个信息,可以看到http请求的详细信息,如下图所示:

通过程序伪装成浏览器请求的时候,就多需要关注Request Headers里面的信息,还有一些需要登录的网站也是需要关注这些的。Response里面的信息就是服务器返回的内容,这里只做对文本信息的处理,对图片、音频、视频等信息不做介绍。
Response里面就包含这我们爬虫想获取的信息内容。如果里面的格式不好看的话,可以在浏览器中输入该http请求的url地址,然后右键-->查看网页源代码的形式查看相关信息。通过分析网页源代码中的字符串,总结出统一的规则,提取相应的文本信息。
代码实现:
CrawlBase类,模拟http请求的基类
/**
*@Description: 获取网页信息基类
*/
package com.lulei.crawl;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.commons.httpclient.Header;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.methods.PostMethod;
import org.apache.log4j.Logger;
import com.lulei.util.CharsetUtil;
public abstract class CrawlBase {
private static Logger log = Logger.getLogger(CrawlBase.class);
//链接源代码
private String pageSourceCode = "";
//返回头信息
private Header[] responseHeaders = null;
//连接超时时间
private static int connectTimeout = 3500;
//连接读取时间
private static int readTimeout = 3500;
//默认最大访问次数
private static int maxConnectTimes = 3;
//网页默认编码方式
private static String charsetName = "iso-8859-1";
private static HttpClient httpClient = new HttpClient();
static {
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(connectTimeout);
httpClient.getHttpConnectionManager().getParams().setSoTimeout(readTimeout);
}
/**
* @param urlStr
* @param charsetName
* @param method
* @param params
* @return
* @throws HttpException
* @throws IOException
* @Author: lulei
* @Description: method方式访问页面
*/
public boolean readPage(String urlStr, String charsetName, String method, HashMap params) throws HttpException, IOException {
if ("post".equals(method) || "POST".equals(method)) {
return readPageByPost(urlStr, charsetName, params);
} else {
return readPageByGet(urlStr, charsetName, params);
}
}
/**
* @param urlStr
* @param charsetName
* @param params
* @return 访问是否成功
* @throws HttpException
* @throws IOException
* @Author: lulei
* @Description: Get方式访问页面
*/
public boolean readPageByGet(String urlStr, String charsetName, HashMap params) throws HttpException, IOException {
GetMethod getMethod = createGetMethod(urlStr, params);
return readPage(getMethod, charsetName, urlStr);
}
/**
* @param urlStr
* @param charsetName
* @param params
* @return 访问是否成功
* @throws HttpException
* @throws IOException
* @Author: lulei
* @Description: Post方式访问页面
*/
public boolean readPageByPost(String urlStr, String charsetName, HashMap params) throws HttpException, IOException{
PostMethod postMethod = createPostMethod(urlStr, params);
return readPage(postMethod, charsetName, urlStr);
}
/**
* @param method
* @param defaultCharset
* @param urlStr
* @return 访问是否成功
* @throws HttpException
* @throws IOException
* @Author: lulei
* @Description: 读取页面信息和头信息
*/
private boolean readPage(HttpMethod method, String defaultCharset, String urlStr) throws HttpException, IOException{
int n = maxConnectTimes;
while (n > 0) {
try {
if (httpClient.executeMethod(method) != HttpStatus.SC_OK){
log.error("can not connect " + urlStr + "\t" + (maxConnectTimes - n + 1) + "\t" + httpClient.executeMethod(method));
n--;
} else {
//获取头信息
responseHeaders = method.getResponseHeaders();
//获取页面源代码
InputStream inputStream = method.getResponseBodyAsStream();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream, charsetName));
StringBuffer stringBuffer = new StringBuffer();
String lineString = null;
while ((lineString = bufferedReader.readLine()) != null){
stringBuffer.append(lineString);
stringBuffer.append("\n");
}
pageSourceCode = stringBuffer.toString();
InputStream in =new ByteArrayInputStream(pageSourceCode.getBytes(charsetName));
String charset = CharsetUtil.getStreamCharset(in, defaultCharset);
//下面这个判断是为了IP归属地查询特意加上去的
if ("Big5".equals(charset)) {
charset = "gbk";
}
if (!charsetName.toLowerCase().equals(charset.toLowerCase())) {
pageSourceCode = new String(pageSourceCode.getBytes(charsetName), charset);
}
return true;
}
} catch (Exception e) {
e.printStackTrace();
System.out.println(urlStr + " -- can't connect " + (maxConnectTimes - n + 1));
n--;
}
}
return false;
}
/**
* @param urlStr
* @param params
* @return GetMethod
* @Author: lulei
* @Description: 设置get请求参数
*/
@SuppressWarnings("rawtypes")
private GetMethod createGetMethod(String urlStr, HashMap params){
GetMethod getMethod = new GetMethod(urlStr);
if (params == null){
return getMethod;
}
Iterator iter = params.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
String key = (String) entry.getKey();
String val = (String) entry.getValue();
getMethod.setRequestHeader(key, val);
}
return getMethod;
}
/**
* @param urlStr
* @param params
* @return PostMethod
* @Author: lulei
* @Description: 设置post请求参数
*/
private PostMethod createPostMethod(String urlStr, HashMap params){
PostMethod postMethod = new PostMethod(urlStr);
if (params == null){
return postMethod;
}
Iterator> iter = params.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = iter.next();
String key = (String) entry.getKey();
String val = (String) entry.getValue();
postMethod.setParameter(key, val);
}
return postMethod;
}
/**
* @param urlStr
* @param charsetName
* @return 访问是否成功
* @throws IOException
* @Author: lulei
* @Description: 不设置任何头信息直接访问网页
*/
public boolean readPageByGet(String urlStr, String charsetName) throws IOException{
return this.readPageByGet(urlStr, charsetName, null);
}
/**
* @return String
* @Author: lulei
* @Description: 获取网页源代码
*/
public String getPageSourceCode(){
return pageSourceCode;
}
/**
* @return Header[]
* @Author: lulei
* @Description: 获取网页返回头信息
*/
public Header[] getHeader(){
return responseHeaders;
}
/**
* @param timeout
* @Author: lulei
* @Description: 设置连接超时时间
*/
public void setConnectTimeout(int timeout){
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(timeout);
}
/**
* @param timeout
* @Author: lulei
* @Description: 设置读取超时时间
*/
public void setReadTimeout(int timeout){
httpClient.getHttpConnectionManager().getParams().setSoTimeout(timeout);
}
/**
* @param maxConnectTimes
* @Author: lulei
* @Description: 设置最大访问次数,链接失败的情况下使用
*/
public static void setMaxConnectTimes(int maxConnectTimes) {
CrawlBase.maxConnectTimes = maxConnectTimes;
}
/**
* @param connectTimeout
* @param readTimeout
* @Author: lulei
* @Description: 设置连接超时时间和读取超时时间
*/
public void setTimeout(int connectTimeout, int readTimeout){
setConnectTimeout(connectTimeout);
setReadTimeout(readTimeout);
}
/**
* @param charsetName
* @Author: lulei
* @Description: 设置默认编码方式
*/
public static void setCharsetName(String charsetName) {
CrawlBase.charsetName = charsetName;
}
}
/**
*@Description: 获取页面链接地址信息基类
*/
package com.lulei.crawl;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import com.lulei.util.DoRegex;
public abstract class CrawlListPageBase extends CrawlBase {
private String pageurl;
/**
* @param urlStr
* @param charsetName
* @throws IOException
*/
public CrawlListPageBase(String urlStr, String charsetName) throws IOException{
readPageByGet(urlStr, charsetName);
pageurl = urlStr;
}
/**
* @param urlStr
* @param charsetName
* @param method
* @param params
* @throws IOException
*/
public CrawlListPageBase(String urlStr, String charsetName, String method, HashMap params) throws IOException{
readPage(urlStr, charsetName, method, params);
pageurl = urlStr;
}
/**
* @return List
* @Author: lulei
* @Description: 返回页面上需求的链接地址
*/
public List getPageUrls(){
List pageUrls = new ArrayList();
pageUrls = DoRegex.getArrayList(getPageSourceCode(), getUrlRegexString(), pageurl, getUrlRegexStringNum());
return pageUrls;
}
/**
* @return String
* @Author: lulei
* @Description: 返回页面上需求的网址连接的正则表达式
*/
public abstract String getUrlRegexString();
/**
* @return int
* @Author: lulei
* @Description: 正则表达式中要去的字段位置
*/
public abstract int getUrlRegexStringNum();
}
DoRegex类,封装的一些基于正则表达式字符串匹配查找类
/**
* @Description: 正则处理工具
*/
package com.lulei.util;
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class DoRegex {
private static String rootUrlRegex = "(http://.*?/)";
private static String currentUrlRegex = "(http://.*/)";
private static String ChRegex = "([\u4e00-\u9fa5]+)";
/**
* @param dealStr
* @param regexStr
* @param splitStr
* @param n
* @return String
* @Author: lulei
* @Description: 正则匹配结果,每条记录用splitStr分割
*/
public static String getString(String dealStr, String regexStr, String splitStr, int n){
String reStr = "";
if (dealStr == null || regexStr == null || n < 1 || dealStr.isEmpty()){
return reStr;
}
splitStr = (splitStr == null) ? "" : splitStr;
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
StringBuffer stringBuffer = new StringBuffer();
while (matcher.find()) {
stringBuffer.append(matcher.group(n).trim());
stringBuffer.append(splitStr);
}
reStr = stringBuffer.toString();
if (splitStr != "" && reStr.endsWith(splitStr)){
reStr = reStr.substring(0, reStr.length() - splitStr.length());
}
return reStr;
}
/**
* @param dealStr
* @param regexStr
* @param n
* @return String
* @Author: lulei
* @Description: 正则匹配结果,将所有匹配记录组装成字符串
*/
public static String getString(String dealStr, String regexStr, int n){
return getString(dealStr, regexStr, null, n);
}
/**
* @param dealStr
* @param regexStr
* @param n
* @return String
* @Author: lulei
* @Description: 正则匹配第一条结果
*/
public static String getFirstString(String dealStr, String regexStr, int n){
if (dealStr == null || regexStr == null || n < 1 || dealStr.isEmpty()){
return "";
}
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
while (matcher.find()) {
return matcher.group(n).trim();
}
return "";
}
/**
* @param dealStr
* @param regexStr
* @param n
* @return ArrayList
* @Author: lulei
* @Description: 正则匹配结果,将匹配结果组装成数组
*/
public static List getList(String dealStr, String regexStr, int n){
List reArrayList = new ArrayList();
if (dealStr == null || regexStr == null || n < 1 || dealStr.isEmpty()){
return reArrayList;
}
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
while (matcher.find()) {
reArrayList.add(matcher.group(n).trim());
}
return reArrayList;
}
/**
* @param url
* @param currentUrl
* @return String
* @Author: lulei
* @Description: 组装网址,网页的url
*/
private static String getHttpUrl(String url, String currentUrl){
try {
url = encodeUrlCh(url);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (url.indexOf("http") == 0){
return url;
}
if (url.indexOf("/") == 0){
return getFirstString(currentUrl, rootUrlRegex, 1) + url.substring(1);
}
return getFirstString(currentUrl, currentUrlRegex, 1) + url;
}
/**
* @param dealStr
* @param regexStr
* @param currentUrl
* @param n
* @return ArrayList
* @Author: lulei
* @Description: 获取和正则匹配的绝对链接地址
*/
public static List getArrayList(String dealStr, String regexStr, String currentUrl, int n){
List reArrayList = new ArrayList();
if (dealStr == null || regexStr == null || n < 1 || dealStr.isEmpty()){
return reArrayList;
}
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
while (matcher.find()) {
reArrayList.add(getHttpUrl(matcher.group(n).trim(), currentUrl));
}
return reArrayList;
}
/**
* @param url
* @return
* @throws UnsupportedEncodingException
* @Author: lulei
* @Description: 将连接地址中的中文进行编码处理
*/
public static String encodeUrlCh (String url) throws UnsupportedEncodingException {
while (true) {
String s = getFirstString(url, ChRegex, 1);
if ("".equals(s)){
return url;
}
url = url.replaceAll(s, URLEncoder.encode(s, "utf-8"));
}
}
/**
* @param dealStr
* @param regexStr
* @param array 正则位置数组
* @return
* @Author:lulei
* @Description: 获取全部
*/
public static List getListArray(String dealStr, String regexStr, int[] array) {
List reArrayList = new ArrayList();
if (dealStr == null || regexStr == null || array == null) {
return reArrayList;
}
for (int i = 0; i < array.length; i++) {
if (array[i] < 1) {
return reArrayList;
}
}
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
while (matcher.find()) {
String[] ss = new String[array.length];
for (int i = 0; i < array.length; i++) {
ss[i] = matcher.group(array[i]).trim();
}
reArrayList.add(ss);
}
return reArrayList;
}
/**
* @param dealStr
* @param regexStr
* @param array
* @return
* @Author:lulei
* @Description: 获取全部
*/
public static List getStringArray(String dealStr, String regexStr, int[] array) {
List reStringList = new ArrayList();
if (dealStr == null || regexStr == null || array == null) {
return reStringList;
}
for (int i = 0; i < array.length; i++) {
if (array[i] < 1) {
return reStringList;
}
}
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
while (matcher.find()) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < array.length; i++) {
sb.append(matcher.group(array[i]).trim());
}
reStringList.add(sb.toString());
}
return reStringList;
}
/**
* @param dealStr
* @param regexStr
* @param array 正则位置数组
* @return
* @Author:lulei
* @Description: 获取第一个
*/
public static String[] getFirstArray(String dealStr, String regexStr, int[] array) {
if (dealStr == null || regexStr == null || array == null) {
return null;
}
for (int i = 0; i < array.length; i++) {
if (array[i] < 1) {
return null;
}
}
Pattern pattern = Pattern.compile(regexStr, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher matcher = pattern.matcher(dealStr);
while (matcher.find()) {
String[] ss = new String[array.length];
for (int i = 0; i < array.length; i++) {
ss[i] = matcher.group(array[i]).trim();
}
return ss;
}
return null;
}
}
CharsetUtil类,编码方式检测类
/**
*@Description: 编码方式检测类
*/
package com.lulei.util;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.nio.charset.Charset;
import info.monitorenter.cpdetector.io.ASCIIDetector;
import info.monitorenter.cpdetector.io.CodepageDetectorProxy;
import info.monitorenter.cpdetector.io.JChardetFacade;
import info.monitorenter.cpdetector.io.ParsingDetector;
import info.monitorenter.cpdetector.io.UnicodeDetector;
public class CharsetUtil {
private static final CodepageDetectorProxy detector;
static {//初始化探测器
detector = CodepageDetectorProxy.getInstance();
detector.add(new ParsingDetector(false));
detector.add(ASCIIDetector.getInstance());
detector.add(UnicodeDetector.getInstance());
detector.add(JChardetFacade.getInstance());
}
/**
* @param url
* @param defaultCharset
* @Author:lulei
* @return 获取文件的编码方式
*/
public static String getStreamCharset (URL url, String defaultCharset) {
if (url == null) {
return defaultCharset;
}
try {
//使用第三方jar包检测文件的编码
Charset charset = detector.detectCodepage(url);
if (charset != null) {
return charset.name();
}
} catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return defaultCharset;
}
/**
* @param inputStream
* @param defaultCharset
* @return
* @Author:lulei
* @Description: 获取文件流的编码方式
*/
public static String getStreamCharset (InputStream inputStream, String defaultCharset) {
if (inputStream == null) {
return defaultCharset;
}
int count = 200;
try {
count = inputStream.available();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
//使用第三方jar包检测文件的编码
Charset charset = detector.detectCodepage(inputStream, count);
if (charset != null) {
return charset.name();
}
} catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return defaultCharset;
}
}
百度新闻案例:
1)找到百度新闻更新列表页,如http://news.baidu.com/n?cmd=4&class=civilnews&pn=1&from=tab 界面如下图所示:

文章URL链接地址如下图所示:

通过对源文件的分析,编写BaiduNewList类,实现百度新闻列表页信息的抓取,代码如下:
/**
*@Description: 百度新闻滚动列表页,可以获取当前页面上的链接
*/
package com.lulei.crawl.news;
import java.io.IOException;
import java.util.HashMap;
import com.lulei.crawl.CrawlListPageBase;
public class BaiduNewList extends CrawlListPageBase{
private static HashMap params;
/**
* 添加相关头信息,对请求进行伪装
*/
static {
params = new HashMap();
params.put("Referer", "http://www.baidu.com");
params.put("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36");
}
public BaiduNewList(String urlStr) throws IOException {
super(urlStr, "utf-8", "get", params);
}
@Override
public String getUrlRegexString() {
// TODO Auto-generated method stub
//新闻列表页中文章链接地址的正则表达式
return "• 2)通过第一步获取的URL,得到新闻所在的内容页面URL,由于百度新闻列表页面上的新闻来自不同的站,所以很难找到一个通用的结构,大多数的新闻类网站,内容都是放在p标签内,所以就采用了如下的方式获取新闻的内容,如下图:
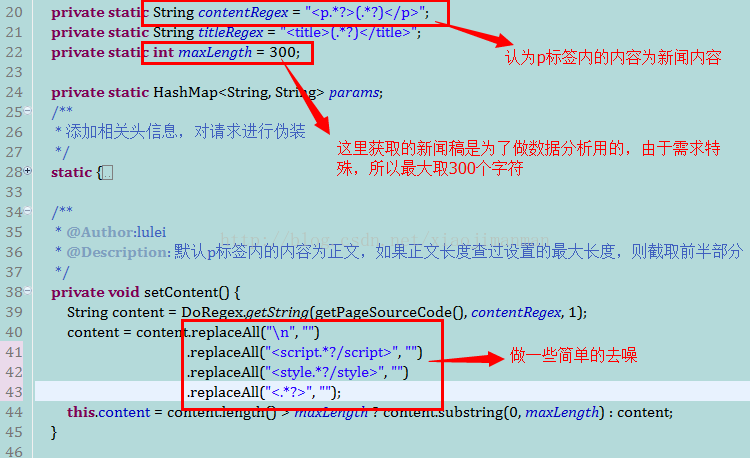
News类具体实现如下所示:
/**
*@Description: 新闻类网站新闻内容
*/
package com.lulei.crawl.news;
import java.io.IOException;
import java.util.HashMap;
import org.apache.commons.httpclient.HttpException;
import com.lulei.crawl.CrawlBase;
import com.lulei.util.DoRegex;
public class News extends CrawlBase{
private String url;
private String content;
private String title;
private String type;
private static String contentRegex = "(.*?)";
private static String titleRegex = "(.*?) ";
private static int maxLength = 300;
private static HashMap params;
/**
* 添加相关头信息,对请求进行伪装
*/
static {
params = new HashMap();
params.put("Referer", "http://www.baidu.com");
params.put("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36");
}
/**
* @Author:lulei
* @Description: 默认p标签内的内容为正文,如果正文长度查过设置的最大长度,则截取前半部分
*/
private void setContent() {
String content = DoRegex.getString(getPageSourceCode(), contentRegex, 1);
content = content.replaceAll("\n", "")
.replaceAll("", "")
.replaceAll("", "")
.replaceAll("<.*?>", "");
this.content = content.length() > maxLength ? content.substring(0, maxLength) : content;
}
/**
* @Author:lulei
* @Description: 默认title标签内的内容为标题
*/
private void setTitle() {
this.title = DoRegex.getString(getPageSourceCode(), titleRegex, 1);;
}
public News(String url) throws HttpException, IOException {
this.url = url;
readPageByGet(url, "utf-8", params);
setContent();
setTitle();
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public String getTitle() {
return title;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public static void setMaxLength(int maxLength) {
News.maxLength = maxLength;
}
/**
* @param args
* @throws HttpException
* @throws IOException
* @Author:lulei
* @Description: 测试用例
*/
public static void main(String[] args) throws HttpException, IOException {
// TODO Auto-generated method stub
News news = new News("http://we.sportscn.com/viewnews-1634777.html");
System.out.println(news.getContent());
System.out.println(news.getTitle());
}
}
3)编写抓取的入口,这里为了简单,只做了两层的分析,所以新闻更新列表也的URL就直接写在程序中。如下图所示:

执行一次采集任务如下图所示:

在main函数里面只需要一次性或周期性的去执行run函数即可,具体代码如下:
/**
*@Description:
*/
package com.lulei.knn.data;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import com.lulei.crawl.news.BaiduNewList;
import com.lulei.crawl.news.News;
import com.lulei.knn.index.KnnIndex;
import com.lulei.knn.index.KnnSearch;
import com.lulei.util.ParseMD5;
public class CrawlNews {
private static List infos;
private static KnnIndex knnIndex = new KnnIndex();
private static KnnSearch knnSearch = new KnnSearch();
private static HashMap result;
static {
infos = new ArrayList();
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=sportnews&pn=1&from=tab", "体育类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=sportnews&pn=2&from=tab", "体育类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=sportnews&pn=3&from=tab", "体育类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=mil&pn=1&sub=0", "军事类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=mil&pn=2&sub=0", "军事类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=mil&pn=3&sub=0", "军事类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=finannews&pn=1&sub=0", "财经类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=finannews&pn=2&sub=0", "财经类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=finannews&pn=3&sub=0", "财经类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=internet&pn=1&from=tab", "互联网"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=housenews&pn=1&sub=0", "房产类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=housenews&pn=2&sub=0", "房产类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=housenews&pn=3&sub=0", "房产类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=gamenews&pn=1&sub=0", "游戏类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=gamenews&pn=2&sub=0", "游戏类"));
infos.add(new Info("http://news.baidu.com/n?cmd=4&class=gamenews&pn=3&sub=0", "游戏类"));
}
/**
*@Description: 抓取网址信息
*@Author:lulei
*/
static class Info{
String url;
String type;
Info(String url, String type) {
this.url = url;
this.type = type;
}
}
/**
* @param info
* @Author:lulei
* @Description: 抓取一个列表页面下的新闻信息
*/
private void crawl(Info info) {
if (info == null) {
return;
}
try {
BaiduNewList baiduNewList = new BaiduNewList(info.url);
List urls = baiduNewList.getPageUrls();
for (String url : urls) {
News news = new News(url);
NewsBean newBean = new NewsBean();
newBean.setId(ParseMD5.parseStrToMd5L32(url));
newBean.setType(info.type);
newBean.setUrl(url);
newBean.setTitle(news.getTitle());
newBean.setContent(news.getContent());
//保存到索引文件中
knnIndex.add(newBean);
//knn验证
if (news.getContent() == null || "".equals(news.getContent())) {
result.put("E", 1+result.get("E"));
continue;
}
if (info.type.equals(knnSearch.getType(news.getContent()))) {
result.put("R", 1+result.get("R"));
} else {
result.put("W", 1+result.get("W"));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @Author:lulei
* @Description: 启动入口
*/
public void run() {
result = new HashMap();
result.put("R", 0);
result.put("W", 0);
result.put("E", 0);
for (Info info : infos) {
System.out.println(info.url + "------start");
crawl(info);
System.out.println(info.url + "------end");
}
try {
knnIndex.commit();
System.out.println("R = " + result.get("R"));
System.out.println("W = " + result.get("W"));
System.out.println("E = " + result.get("E"));
System.out.println("精确度:" + (result.get("R") * 1.0 / (result.get("R") + result.get("W"))));
System.out.println("-------------finished---------------");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new CrawlNews().run();
}
}