西山小菜鸟之Scrapy学习笔记---爬取链家网楼盘信息
前言
本文以链家网北京地区为例,介绍自己爬取链家全国楼盘信息。链接如下:链家新房-北京。本文中若存在不详细的地方欢迎各位大神网友提问,若有错误的地方,希望大家指正。谢谢!! ? ?
GitHub: https://github.com/wei523712/lianjia_loupan
粗略分析
- 进入楼盘列表页可以看到列表页的链接为:https://bj.fang.lianjia.com/loupan/ ,其中bj为北京,是城市名;最后的loupapn是指楼盘页。
- 点击主页上的楼盘标签进入楼盘列表主页,可以看出每页列出了十个楼盘信息,且某些城市的楼盘信息可能不只一页,此北京市楼盘有十页。此处猜想可通过xpath提取总页数。点击主页上的楼盘标签进入楼盘列表主页,可以看出每页列出了十个楼盘信息,且某些城市的楼盘信息可能不只一页,此北京市楼盘有十页。此处猜想可通过xpath提取总页数。

- 随意进入一个楼盘,可以看到该楼盘的具体信息。此处提取楼盘详情中的字段。
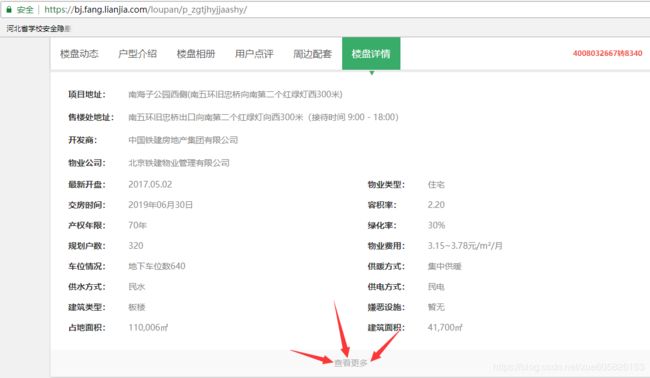
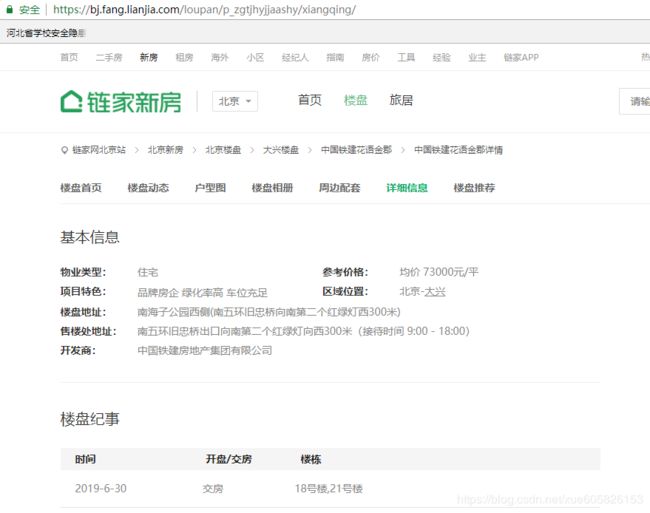
点击“查看更多”,发现打开了一个新的网页,此网页中的基本信息比上一个网页多一些基本字段,所以真实爬取的网页为该网页。
程序分析
- items
import scrapy
class LianjiaItem(scrapy.Item):
lpm = scrapy.Field() #楼盘名
bm = scrapy.Field() #别名
jj = scrapy.Field() #均价
xmdz = scrapy.Field() #项目地址
slcdz = scrapy.Field() #售楼处地址
kfs = scrapy.Field() #开发商
wygs = scrapy.Field() #物业公司
zxkp = scrapy.Field() #最新开盘
jfsj = scrapy.Field() #交房时间
cqnx = scrapy.Field() #产权年限
ghhs = scrapy.Field() #规划户数
cwqk = scrapy.Field() #车位情况
gsfs = scrapy.Field() #供水方式
jzlx = scrapy.Field() #建筑类型
zdmj = scrapy.Field() #占地面积
wylx = scrapy.Field() #物业类型
rjl = scrapy.Field() #容积率
lhl = scrapy.Field() #绿化率
wyfy = scrapy.Field() #物业费用
gnfs = scrapy.Field() #供暖方式
gdfs = scrapy.Field() #供电方式
xwss = scrapy.Field() #嫌恶设施
jzmj = scrapy.Field() #建筑面积
xmts = scrapy.Field() #项目特色
qywz = scrapy.Field() #区域位置
cwpb = scrapy.Field() #车位配比
city = scrapy.Field() #归属城市
- spiders
码前分析
a. 为了便于爬取链家网的全国信息,我把链家网站上的各城市链接写入了一个txt文件。
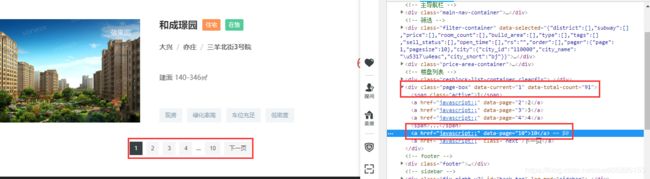
b.此前分析可通过xpath直接提取网页的总页数,但是后面发现不行,网页信息是通过Javascript加载的。但 仍可通过上面的data-total-count属性提取。用此属性值除以10 向上取整便为页数。
代码
import scrapy
from lianjia.items import LianjiaItem
import re
import math
class FangSpider(scrapy.Spider):
name = 'fang'
page = 1
def start_requests(self):
f = open('G:/task/lianjia/lianjia/spiders/city.txt','r',encoding='gbk')
for link in f:
url = 'https:' + link.replace('\n','') + '/loupan/'
yield scrapy.Request(url=url,callback=self.parse,meta={'c_url':url})
#楼盘列表页
def parse(self,response):
bigtag = response.xpath('//div[@class="resblock-list-container clearfix"]/ul[@class="resblock-list-wrapper"]/li')
#进入1级详情页
for tag in bigtag:
lp_link = tag.xpath('.//div/div[@class="resblock-name"]/a/@href').extract_first()
yield scrapy.Request(url=response.urljoin(lp_link),callback=self.parse_lou)
#翻页
page_num = response.xpath('//div[@class="page-box"]/@data-total-count').extract_first()
number = math.ceil(int(page_num)/10)
link = response.meta['c_url']
for p in range(2,number+1):
url = link + 'pg' + str(p) + '/'
yield scrapy.Request(url=url, callback=self.parse,meta={'c_url':link})
#提取1级详情页的某些信息,并进入2级详情页
def parse_lou(self,response):
bigname = response.xpath('//div[@class="box-left"]/div[@class="box-left-top"]/div[@class="name-box"]/a/h1/text()').extract_first().strip()
littlename = response.xpath('//div[@class="box-left"]/div[@class="box-left-top"]/div[@class="name-box"]/a/span/text()').extract_first()
lpm_c = bigname if bigname else '无楼盘信息'
bm_c = re.findall('别名/(.*)',littlename)[0] if littlename else '无别名信息'
kaipan = response.xpath('//div[@class="box-loupan"]/ul/li[1]/p/span[2]/text()').extract_first().strip()
jiaofang = response.xpath('//div[@class="box-loupan"]/ul/li[3]/p/span[2]/text()').extract_first().strip()
xianwu = response.xpath('//div[@class="box-loupan"]/ul/li[12]/p/span[2]/text()').extract_first().strip()
kpsj_c = kaipan if kaipan else '暂无开盘时间信息'
jfsj_c = jiaofang if jiaofang else '暂无交房时间信息'
xwss_c = xianwu if xianwu else '暂无嫌恶设施信息'
#构造链接,进入2级详情页,并传递部分提取的信息
next_detail = response.url + 'xiangqing/'
yield scrapy.Request(url=next_detail,callback=self.parse_detail,meta={'lpm_c':lpm_c,'bm_c':bm_c,'kpsj_c':kpsj_c,'jfsj_c':jfsj_c,'xwss_c':xwss_c,})
#提取2级详情页信息
def parse_detail(self,response):
item = LianjiaItem()
item['lpm'] = response.meta['lpm_c']
item['bm'] = response.meta['bm_c']
item['zxkp'] = response.meta['kpsj_c']
item['jfsj'] = response.meta['jfsj_c']
item['xwss'] = response.meta['xwss_c']
#基本信息
tag_jb = response.xpath('//div[@class="big-left fl"]/ul[@class="x-box"][1]')
wuyelx = tag_jb.xpath('.//li[1]/span[2]/text()').extract_first()
xiangmuts = tag_jb.xpath('.//li[3]/span[2]/text()').extract_first()
loupandz = tag_jb.xpath('.//li[5]/span[2]/text()').extract_first()
shouloucdz = tag_jb.xpath('.//li[6]/span[2]/text()').extract_first()
kaifas = tag_jb.xpath('.//li[7]/span[2]/text()').extract_first().strip()
cankaojg = tag_jb.xpath('.//li[2]/span[2]/span/text()').extract_first().strip()
quyuwz= tag_jb.xpath('.//li[4]/span[2]').xpath('string(.)').extract_first().strip()
city = quyuwz.split('-')[0] if quyuwz else '暂无归属城市'
item['wylx'] = wuyelx if wuyelx else '暂无物业类型信息'
item['xmts'] = xiangmuts if xiangmuts else '暂无项目特色信息'
item['xmdz'] = loupandz if loupandz else '暂无楼盘地址信息'
item['slcdz'] = shouloucdz if shouloucdz else '暂无售楼处地址信息'
item['kfs'] = kaifas if kaifas else '暂无开发商信息'
item['jj'] = cankaojg if cankaojg else '暂无参考价格信息'
item['qywz'] = quyuwz if quyuwz else '暂无区域位置信息'
item['city'] = city
#规划信息
tag_gh = response.xpath('//div[@class="big-left fl"]/ul[@class="x-box"][2]')
jianzhulx = tag_gh.xpath('.//li[1]/span[2]/text()').extract_first().strip()
lvhual = tag_gh.xpath('.//li[2]/span[2]/text()').extract_first().strip()
zhandimj = tag_gh.xpath('.//li[3]/span[2]/text()').extract_first().strip()
rongjil = tag_gh.xpath('.//li[4]/span[2]/text()').extract_first().strip()
jianzhumj = tag_gh.xpath('.//li[5]/span[2]/text()').extract_first().strip()
guihuahs = tag_gh.xpath('.//li[7]/span[2]/text()').extract_first().strip()
changquannx = tag_gh.xpath('.//li[8]/span[2]/text()').extract_first().strip()
item['jzlx'] = jianzhulx if jianzhulx else '暂无建筑类型信息'
item['lhl'] = lvhual if lvhual else '暂无绿化率信息'
item['zdmj'] = zhandimj if zhandimj else '暂无占地面积信息'
item['rjl'] = rongjil if rongjil else '暂无容积率信息'
item['jzmj'] = jianzhumj if jianzhumj else '暂无建筑面积信息'
item['ghhs'] = guihuahs if guihuahs else '暂无规划户数信息'
item['cqnx'] = changquannx if changquannx else '暂无产权年限信息'
#配套信息
tag_pt = response.xpath('//div[@class="big-left fl"]/ul[@class="x-box"][3]')
wuyegs = tag_pt.xpath('.//li[1]/span[2]/text()').extract_first().strip()
cheweipb = tag_pt.xpath('.//li[2]/span[2]/text()').extract_first().strip()
wuyef = tag_pt.xpath('.//li[3]/span[2]/text()').extract_first().strip()
gongnuanfs = tag_pt.xpath('.//li[4]/span[2]/text()').extract_first().strip()
gongshuifs = tag_pt.xpath('.//li[5]/span[2]/text()').extract_first().strip()
gongdianfs = tag_pt.xpath('.//li[6]/span[2]/text()').extract_first().strip()
chewei = tag_pt.xpath('.//li[7]/span[2]/text()').extract_first().strip()
zhoubian = tag_pt.xpath('.//li[8]/div[@id="around_txt"]').xpath('string(.)').extract_first()
item['wygs'] = wuyegs if wuyegs else '暂无物业公司信息'
item['cwpb'] = cheweipb if cheweipb else '暂无车位信息'
item['wyfy'] = wuyef if wuyef else '暂无物业费用信息'
item['gnfs'] = gongnuanfs if gongnuanfs else '暂无供暖方式信息'
item['gsfs'] = gongshuifs if gongshuifs else '暂无供水方式信息'
item['gdfs'] = gongdianfs if gongdianfs else '暂无供电方式信息'
item['cwqk'] = chewei.replace(' ','') if chewei else '暂无车位情况信息'
yield item
- pipelines
此处将爬取的数据插入MySQL数据库中,提前已在库中建好库和相应的表。
import pymysql
class LianjiaPipeline(object):
def open_spider(self,spider):
# 链接数据库
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='lianjia',charset='utf8')
# 获取游标
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = "INSERT INTO loupan (lpm,bm,jj,xmdz,slcdz,kfs,wygs,zxkp,jfsj,cqnx,ghhs,cwqk,gsfs,jzlx,zdmj,wylx,rjl,lhl,wyfy,gnfs,gdfs,xwss,jzmj,xmts,qywz,cwpb,city) VALUES ('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (item['lpm'],item['bm'],item['jj'],item['xmdz'],item['slcdz'],item['kfs'],item['wygs'],item['zxkp'],item['jfsj'],item['cqnx'],item['ghhs'],item['cwqk'],item['gsfs'],item['jzlx'],item['zdmj'],item['wylx'],item['rjl'],item['lhl'],item['wyfy'],item['gnfs'],item['gdfs'],item['xwss'],item['jzmj'],item['xmts'],item['qywz'],item['cwpb'],item['city'])
try:
self.cursor.execute(sql)
# 提交
self.conn.commit()
except Exception as e:
print('写入错误:',e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
- 其它
此处不再给出程序的settings信息及自己找的链家各城市网站。
再次声明
若有错误及不合理之处,望大家批评指正。